La traduction de cette page n'est pas à jour. Cliquez ici pour voir la dernière version en anglais.
Conversion manuelle d’un algorithme MATLAB virgule flottante en virgule fixe
Cet exemple montre comment convertir un algorithme virgule flottante en algorithme virgule fixe et générer ensuite un code C pour cet algorithme. L’exemple utilise les bonnes pratiques suivantes :
Séparer votre algorithme du fichier test.
Préparer votre algorithme en vue de l'instrumentation et de la génération de code.
Gérer les types de données et contrôler la croissance des bits.
Séparer les définitions des types de données du code algorithmique en créant une table de définitions des données.
Pour une liste complète des bonnes pratiques, voir Manual Fixed-Point Conversion Best Practices.
Séparer votre algorithme du fichier test
Écrivez une fonction MATLAB®, mysum, qui effectue la somme des éléments d’un vecteur.
function y = mysum(x) y = 0; for n = 1:length(x) y = y + x(n); end end
Puisque qu’il vous suffit de convertir la portion algorithmique en virgule fixe, il est plus efficace de structurer votre code pour que l’algorithme, dans lequel vous procédez au traitement principal, soit séparé du fichier test.
Écrire un script de test
Dans le fichier de test, créez vos entrées, appelez l’algorithme, et tracez les résultats.
Écrivez un script MATLAB,
mysum_test, qui vérifie le comportement de votre algorithme en utilisant les types de données doubles.n = 10; rng default x = 2*rand(n,1)-1; % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected
rng defaultrègle les paramètres du générateur de nombres aléatoires utilisé par la fonction random à leurs valeurs par défaut afin qu’il produise les mêmes nombres aléatoires que si vous redémarriez MATLAB.Exécutez le script de test.
mysum_test
err = 0Les résultats obtenus en utilisant
mysumcorrespondent à ceux obtenus en utilisant la fonctionsumMATLAB.
Pour plus d’informations, consultez Create a Test File.
Préparer votre algorithme en vue de l'instrumentation et de la génération de code
Dans votre algorithme, après la signature de la fonction, ajoutez la directive de compilation %#codegen pour indiquer que vous souhaitez procéder à l’instrumentation de l’algorithme et générer un code C pour lui. L’ajout de cette directive stipule à l’analyseur de code MATLAB de vous aider à diagnostiquer et à remédier aux violations qui entraîneraient des erreurs lors de l’instrumentation et de la génération de code.
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y = y + x(n); end end
Pour cet algorithme, le témoin de l’analyseur de code, en haut à droite de la fenêtre d’édition, reste vert, ce qui indique qu’il n’a détecté aucune erreur.

Pour plus d’informations, consultez Prepare Your Algorithm for Code Acceleration or Code Generation.
Générer un code C pour votre algorithme original
Générez un code C pour l’algorithme original afin de vérifier que l’algorithme convient pour la génération de code, et afin de voir le code C à virgule flottante. Utilisez la fonction codegen (MATLAB Coder) (MATLAB Coder™ est requis), pour générer une bibliothèque C.
Ajoutez la ligne suivante à l’extrémité de votre script de test afin de générer le code C pour
mysum.codegen mysum -args {x} -config:lib -report
Exécutez à nouveau le script de test.
MATLAB Coder génère un code C pour la fonction
mysumet fournit un lien pour le rapport relatif à la génération du code.En cliquant sur ce lien, vous ouvrez le rapport sur la génération du code et visualisez le code C créé pour
mysum./* Function Definitions */ double mysum(const double x[10]) { double y; int n; y = 0.0; for (n = 0; n < 10; n++) { y += x[n]; } return y; }Comme le langage C n’autorise pas les indices à virgule flottante, le compteur de boucle,
n, est automatiquement déclaré comme un type entier. Vous n’avez pas besoin de convertirnen virgule fixe.L’entrée
xet la sortieysont déclarées comme doubles.
Gérer les types de données et contrôler la croissance des bits
Testez votre algorithme avec des « singles » pour identifier d’éventuelles non-concordances de types
Modifiez votre fichier test pour que le type de données de
xsoit single.n = 10; rng default x = single(2*rand(n,1)-1); % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected codegen mysum -args {x} -config:lib -report
Exécutez à nouveau le script de test.
mysum_test
err = -4.4703e-08 ??? This assignment writes a 'single' value into a 'double' type. Code generation does not support changing types through assignment. Check preceding assignments or input type specifications for type mismatches.
La génération de code échoue, et une non-concordance de type de données est signalée à la ligne
y = y + x(n);.Ouvrez le rapport pour voir l’erreur.
À la ligne
y = y + x(n), le rapport affiche en rouge leysur la gauche de l’affectation pour indiquer qu’il y a une erreur. Le problème est queyest déclaré comme un double alors qu’il est assigné à un single.y + x(n)est la somme d’un double et d’un single ce qui est un single. Placez votre curseur au-dessus des variables et des expressions du rapport pour obtenir des informations sur leurs types. Vous voyez ici que l’expressiony + x(n)est un single.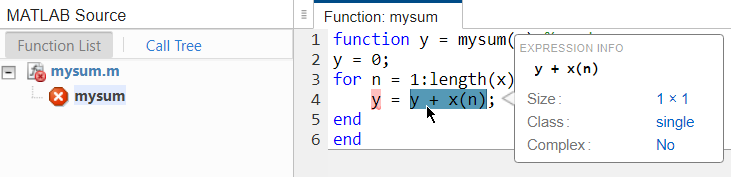
Pour remédier à la non-concordance de type, mettez votre algorithme à jour pour utiliser l’affectation indicée pour la somme des éléments. Changez
y = y + x(n)eny(:) = y + x(n).function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y(:) = y + x(n); end end
En utilisant l’affectation indicée, vous évitez également la croissance des bits, qui est le comportement par défaut lorsque vous ajoutez des nombres à virgule fixe. Pour plus d’informations, consultez Croissance des bits. Il est important d’éviter la croissance des bits afin de pouvoir maintenir vos types à virgule fixe dans l’ensemble de votre code. Pour plus d’informations, consultez Contrôle de la croissance des bits.
Générez à nouveau le code C et ouvrez le rapport de génération de code. Dans le code C, le résultat est maintenant converti en double pour remédier à la non-concordance de type.
Construire un fichier Mex instrumenté
Utilisez la fonction buildInstrumentedMex pour instrumenter votre algorithme afin d'enregistrer les valeurs minimale et maximale de toutes les variables nommées et intermédiaires. Utilisez la fonction showInstrumentationResults pour proposer des types de données à virgule fixe en fonction des valeurs enregistrées. Par la suite, vous utiliserez ces types à virgule fixe proposés pour tester votre algorithme.
Mettez à jour le script de test :
Après avoir déclaré
n, ajoutezbuildInstrumentedMex mySum —args {zeros(n,1)} -histogram.Changez
xpour qu’il soit à nouveau un double. Remplacezx = single(2*rand(n,1)-1);parx = 2*rand(n,1)-1;Au lieu d’appeler l’algorithme original, appelez la fonction MEX générée. Changez
y = mysum(x)eny=mysum_mex(x).Après avoir appelé la fonction MEX, ajoutez
showInstrumentationResults mysum_mex -defaultDT numerictype(1,16) -proposeFL. Les drapeaux-defaultDT numerictype(1,16) -proposeFLindiquent que vous voulez proposer des longueurs de partie fractionnaire pour une longueur de mot de 16 bits.Voici un script de test actualisé.
%% Build instrumented mex n = 10; buildInstrumentedMex mysum -args {zeros(n,1)} -histogram %% Test inputs rng default x = 2*rand(n,1)-1; % Algorithm y = mysum_mex(x); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x} -config:lib -report
Exécutez à nouveau le script de test.
La fonction
showInstrumentationResultspropose des types de données et ouvre un rapport pour afficher les résultats.Dans le rapport, cliquez sur l’onglet Variables.
showInstrumentationResultspropose une longueur de partie fractionnaire de 13 pouryet de 15 pourx.
Dans ce rapport, vous pouvez :
Voir la simulation des valeurs minimale et maximale pour l’entrée
xet la sortiey.Voir les types de données proposés pour
xety.Voir les informations relatives à l’ensemble des variables, les résultats intermédiaires et les expressions de votre code.
Pour voir ces informations s’afficher, placez votre curseur au-dessus des variables ou des expressions du rapport.
Affichez les données d’histogramme pour
xetyafin de vous aider à identifier les valeurs qui sortent de la plage ou dont la précision est inférieure par rapport au type de données courant.Pour visualiser l’histogramme d’une variable particulière, cliquez sur l’icône de son histogramme,
 .
.
Séparer les définitions des types de données du code de l'algorithme
Plutôt que de modifier l’algorithme manuellement pour examiner le comportement de chaque type de données, séparez les définitions des types de données de l'algorithme.
Modifiez mysum de manière à ce qu’il utilise un paramètre d’entrée, T, qui est une structure définissant les types de données pour les données d’entrée et de sortie. Lors de la définition initiale de y, utilisez la syntaxe de la fonction cast avec like — cast(x,'like',y) — pour convertir (par cast) x dans le type de données souhaité.
function y = mysum(x,T) %#codegen y = cast(0,'like',T.y); for n = 1:length(x) y(:) = y + x(n); end end
Créer une table des définitions des types de données
Écrivez une fonction, mytypes, pour définir les différents types de données que vous souhaitez utiliser pour tester votre algorithme. Dans votre tableau de types de données, incluez les doubles, les singles et les types de données doubles mises à l’échelle ainsi que les types de données à virgule fixe proposés précédemment. Avant de convertir votre algorithme en virgule fixe, la bonne pratique consiste à :
Tester la connexion entre le tableau de définition des types de données et votre algorithme en utilisant des doubles.
Tester votre algorithme avec des singles pour identifier d’éventuelles non-concordance de types de données ou d’autres problèmes.
Exécuter l’algorithme en utilisant des doubles mis à l’échelle pour identifier d’éventuels overflows.
function T = mytypes(dt) switch dt case 'double' T.x = double([]); T.y = double([]); case 'single' T.x = single([]); T.y = single([]); case 'fixed' T.x = fi([],true,16,15); T.y = fi([],true,16,13); case 'scaled' T.x = fi([],true,16,15,... 'DataType','ScaledDouble'); T.y = fi([],true,16,13,... 'DataType','ScaledDouble'); end end
Pour plus d’informations, consultez Separate Data Type Definitions from Algorithm.
Mettre à jour le script de test pour utiliser la table des types
Mettez à jour le script de test, mysum_test, pour utiliser la table des types.
Pour le premier essai, vérifiez la connexion entre la table et l’algorithme en utilisant des doubles. Avant de déclarer
n, ajoutezT = mytypes('double');Mettez à jour l’appel de
buildInstrumentedMexpour utiliser le type deT.xspécifié dans le tableau des types de données :buildInstrumentedMex mysum -args {zeros(n,1,'like',T.x),T} -histogramConvertissez par cast
xpour utiliser le type deT.xspécifié dans la table :x = cast(2*rand(n,1)-1,'like',T.x);Appelez la fonction MEX en passant
T:y = mysum_mex(x,T);Appelez
codegenen passantT:codegen mysum -args {x,T} -config:lib -reportVoici le script de test actualisé.
%% Build instrumented mex T = mytypes('double'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); % Algorithm y = mysum_mex(x,T); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Exécutez le script de test et cliquez sur le lien pour ouvrir le rapport sur la génération du code.
Le code C généré est le même que le code généré pour l’algorithme original. Étant donné que la variable
Test utilisée pour spécifier les types et que ces types sont constants au moment de la génération du code ;Tn’est pas utilisé au moment de l’exécution et n'apparaît pas dans le code généré.
Générer un code en virgule fixe
Mettez à jour le script de test pour utiliser les types à virgule fixe proposés précédemment et afficher le code C généré.
Mettez à jour le script de test pour utiliser les types à virgule fixe. Remplacez
T = mytypes('double');parT = mytypes('fixed');, puis sauvegardez le script.Exécutez le script de test et affichez le code C généré.
Cette version de code C n’est pas très efficace ; elle implique de nombreux traitements d'overflows. L’étape suivante consiste à optimiser les types de données pour éviter les overflows.
Optimiser les types de données
Utilisez les doubles mis à l'échelle pour détecter les overflows
Les doubles mis à l'échelle sont une forme hybride entre les nombres à virgule flottante et les nombres à virgule fixe. Fixed-Point Designer™ les stocke en tant que doubles en retenant les informations de mise à l’échelle, de signe et de longueur de mot. Toute l’arithmétique étant réalisée en double précision, vous pouvez voir les overflows qui se produisent.
Mettez à jour le script de test pour utiliser les doubles mis à l’échelle. Remplacez
T = mytypes('fixed');parT = mytypes('scaled');Exécutez à nouveau le script de test.
Le test s’exécute en utilisant des doubles mis à l’échelle et affiche le rapport. Aucun overflow n’a été détecté.
Jusqu’ici, vous avez exécuté le script de test en utilisant des entrées aléatoires, ce qui signifie qu’il est peu probable que le texte ait mis en œuvre la totalité de la plage opérationnelle de l'algorithme.
Trouvez toute la plage des valeurs de l’entrée.
range(T.x)
-1.000000000000000 0.999969482421875 DataTypeMode: Fixed-point: binary point scaling Signedness: Signed WordLength: 16 FractionLength: 15Mettez à jour le script pour tester le cas de contour négatif. Exécutez
mysum_mexavec l’entrée aléatoire originale et avec une entrée qui teste toute la plage des valeurs et agrège les résultats.%% Build instrumented mex T = mytypes('scaled'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); y = mysum_mex(x,T); % Run once with this set of inputs y_expected = sum(double(x)); err = double(y) - y_expected % Run again with this set of inputs. The logs will aggregate. x = -ones(n,1,'like',T.x); y = mysum_mex(x,T); y_expected = sum(double(x)); err = double(y) - y_expected % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Exécutez à nouveau le script de test.
Le test s’exécute et
ydépasse la plage du type de données à virgule fixe.showInstrumentationResultspropose une nouvelle longueur de partie fractionnaire de 11 poury.
Mettez à jour le script de test pour utiliser les doubles mis à l’échelle avec le nouveau type proposé pour
y. DansmyTypes.m, pour le cas'scaled',T.y = fi([],true,16,11,'DataType','ScaledDouble')Exécutez le script de test à nouveau.
Il n’y a maintenant plus d'overflow.
Générer un code pour le type à virgule fixe proposé
Mettez à jour la table des types de données pour utiliser le type à virgule fixe proposé et générez le code.
Dans
myTypes.m, pour le cas'fixed',T.y = fi([],true,16,11)Mettez à jour le script de test,
mysum_test, pour utiliserT = mytypes('fixed');Exécutez le script de test puis cliquez sur le lien « View Report » pour visualiser le code C généré.
short mysum(const short x[10]) { short y; int n; int i; int i1; int i2; int i3; y = 0; for (n = 0; n < 10; n++) { i = y << 4; i1 = x[n]; if ((i & 1048576) != 0) { i2 = i | -1048576; } else { i2 = i & 1048575; } if ((i1 & 1048576) != 0) { i3 = i1 | -1048576; } else { i3 = i1 & 1048575; } i = i2 + i3; if ((i & 1048576) != 0) { i |= -1048576; } else { i &= 1048575; } i = (i + 8) >> 4; if (i > 32767) { i = 32767; } else { if (i < -32768) { i = -32768; } } y = (short)i; } return y; }Par défaut, l’arithmétique de
fiutilise la saturation pour les overflows et l’arrondi au plus proche, ce qui donne un code inefficace.
Modifier les paramètres fimath
Pour rendre le code généré plus efficace, utilisez les paramètres des mathématiques à virgule fixe (fimath), qui sont plus appropriés pour la génération de codes C : wrap pour les overflows et arrondi « plancher ».
Dans
myTypes.m, ajoutez un cas'fixed2':case 'fixed2' F = fimath('RoundingMethod', 'Floor', ... 'OverflowAction', 'Wrap', ... 'ProductMode', 'FullPrecision', ... 'SumMode', 'KeepLSB', ... 'SumWordLength', 32, ... 'CastBeforeSum', true); T.x = fi([],true,16,15,F); T.y = fi([],true,16,11,F);Conseil
Au lieu de saisir manuellement les propriétés
fimath, vous pouvez utiliser l’option Insert fimath de l’éditeur MATLAB. Pour plus d’informations, consultez Building fimath Object Constructors in a GUI.Mettez à jour le script de test pour utiliser
'fixed2', exécutez le script, puis visualisez le code C généré.short mysum(const short x[10]) { short y; int n; y = 0; for (n = 0; n < 10; n++) { y = (short)(((y << 4) + x[n]) >> 4); } return y; }Le code généré est plus efficace, mais
yest décalé pour s’aligner avecxet perd 4 bits de précision.Pour remédier à cette perte de précision, mettez à jour la longueur de mot de
yà 32 bits et conservez 15 bits de précision pour l’alignement avecx.Dans
myTypes.m, ajoutez un cas'fixed32':case 'fixed32' F = fimath('RoundingMethod', 'Floor', ... 'OverflowAction', 'Wrap', ... 'ProductMode', 'FullPrecision', ... 'SumMode', 'KeepLSB', ... 'SumWordLength', 32, ... 'CastBeforeSum', true); T.x = fi([],true,16,15,F); T.y = fi([],true,32,15,F);Mettez à jour le script de test pour utiliser
'fixed32'et exécutez le script pour générer le code à nouveau.Le code généré est maintenant très efficace.
int mysum(const short x[10]) { int y; int n; y = 0; for (n = 0; n < 10; n++) { y += x[n]; } return y; }
Pour plus d’informations, consultez Optimize Your Algorithm.
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)