How Deep Learning HDL Toolbox Compiles the LSTM Layer
An LSTM is a type of recurrent neural network (RNN) that can learn long-term dependencies between time steps of sequence data. When you compile LSTM layers, Deep Learning HDL Toolbox™ splits the LSTM layer into components, generates instructions and memory offsets for those components. Integrate a deep learning processor IP core with LSTM layers into your reference design by:
Learning about the
compilefunction generated LSTM layer components and how those components are optimized.Identifying the external memory addresses that store the generated LSTM layer components weights, biases, and instructions.
LSTM Layer Architecture
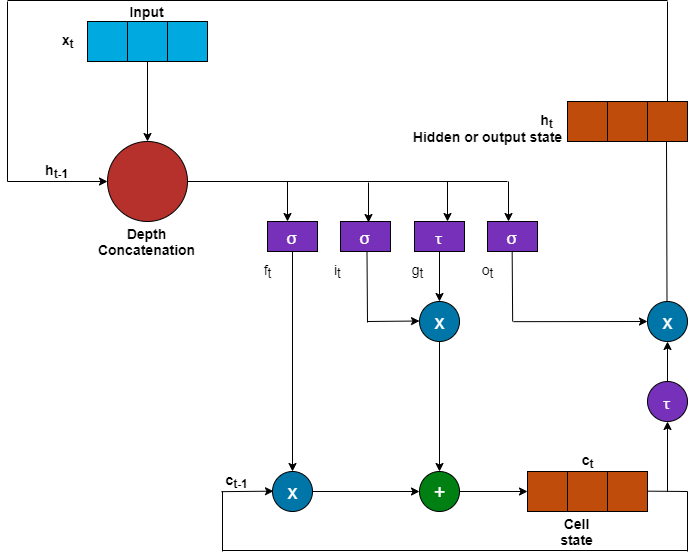
The LSTM layer uses a gating mechanism that controls the memorizing process. You can store, write, or read information in LSTMs by using gates that open and close. An LSTM layer consists of these components:
Forget gate — The forget gate,
fdecides which information to remember and which information to forget.Input gate — The input gate,
iupdates the cell state using information from the input current statexand the previous hidden stateh.Cell state — The cell state stores information from the new layer state based on the previous cell state,
c. The current cell state is,g.Output gate — The output gate,
odetermines the value of the next hidden state,h.
This image shows the components of an LSTM layer:
Compiler Interpretation
The compile method of the dlhdl.Workflow object
translates the:
Forget gate into
lstm.wfInput gate into
lstm.wiCell candidate into
lstm.wgOutput gate into
lstm.wo
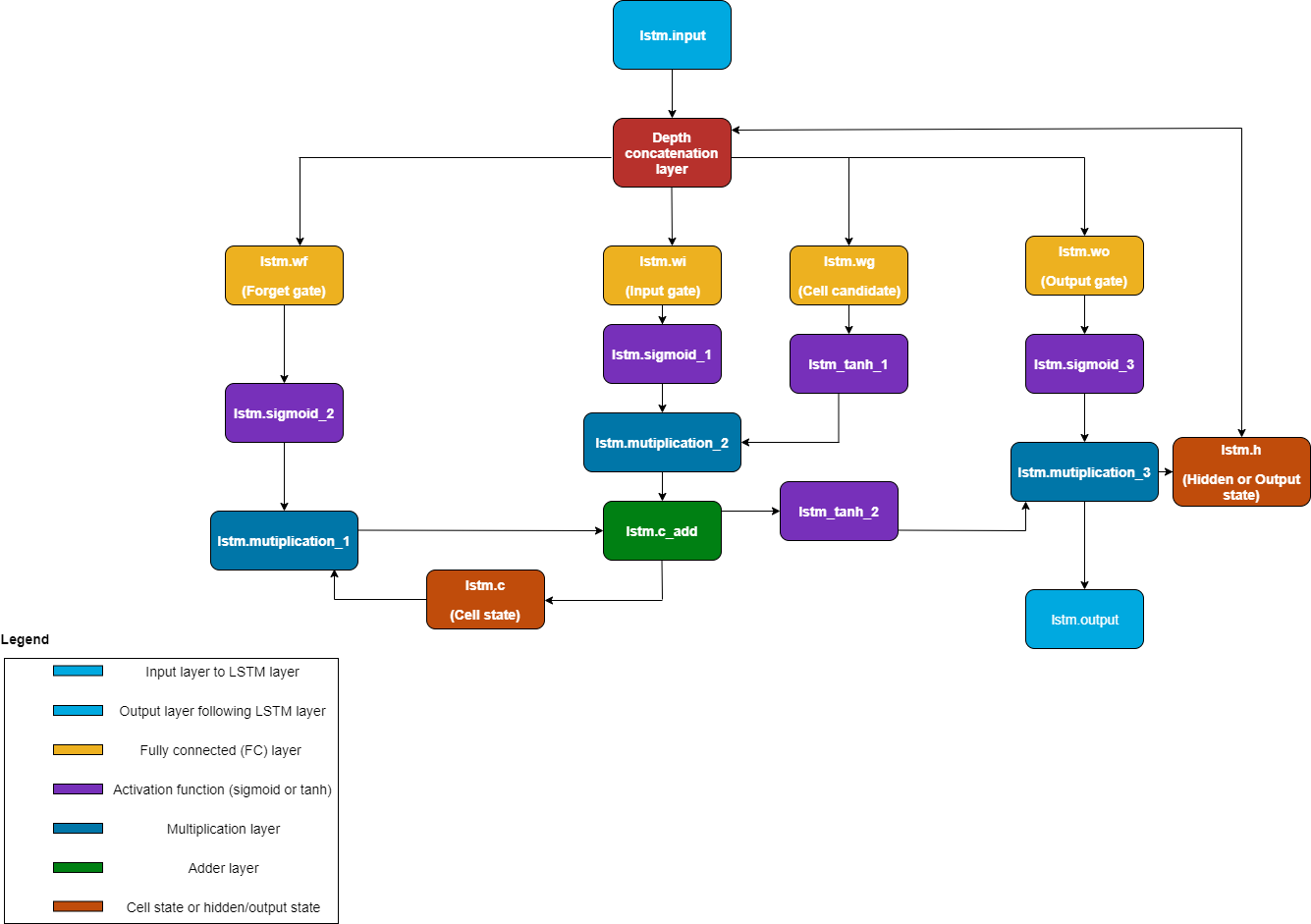
The compile method
Inserts a depth concatenation layer between the layer preceding the LSTM layer and the gates of the LSTM layer.
Generates sigmoid, hyperbolic tangent, multiplication, and addition layers to replace the mathematical operations of the LSTM layer.
When the network has multiple stacked LSTM layers, the compile method
uses the LSTM layer name when generating the translated instructions. For example, if the
network has three stacked LSTM layers named lstm_1,
lstm_2, and lstm_3, the compile
method output is lstm_1.wi, lstm_1.wo,
lstm_1.wg, lstm_1.wf, lstm_2.wi,
and so on. The compiler schedules the different components of the LSTM layer such as fully
connected layers, sigmoid blocks, tanh blocks, and so on, into different kernels within the
deep learning processor architecture.
This image shows the graphical view of the compile method
transformation of the LSTM layer:
To see the output of the compile method for
an LSTM network, see Run Sequence-to-Sequence Classification on Intel FPGA.
Deep Learning Processor Configuration for LSTM Layers
When you want to generate a custom bitstream for deploying an LSTM layer network, you must:
Set the fully connected (FC) layer
ModuleGenerationproperty toon.In the custom module, set the
Addition,Multiplication,TanhLayer, andSigmoidproperties toon.
This code output shows you the deep learning processor configuration for a shipping LSTM bitstream:
hPC = dlhdl.ProcessorConfig(Bitstream="zcu102_lstm_single")hPC =
Processing Module "conv"
ModuleGeneration: 'off'
Processing Module "fc"
ModuleGeneration: 'on'
SoftmaxBlockGeneration: 'off'
GELUBlockGeneration: 'off'
FCThreadNumber: 4
InputMemorySize: 25088
OutputMemorySize: 4096
Processing Module "custom"
ModuleGeneration: 'on'
Addition: 'on'
MishLayer: 'off'
Multiplication: 'on'
Resize2D: 'off'
Sigmoid: 'on'
SwishLayer: 'off'
TanhLayer: 'on'
InputMemorySize: 40
OutputMemorySize: 120
Processor Top Level Properties
RunTimeControl: 'register'
RunTimeStatus: 'register'
InputStreamControl: 'register'
OutputStreamControl: 'register'
SetupControl: 'register'
ProcessorDataType: 'single'
UseVendorLibrary: 'on'
LayerNormalizationBlock: 'off'
System Level Properties
TargetPlatform: 'Xilinx Zynq UltraScale+ MPSoC ZCU102 Evaluation Kit'
TargetFrequency: 250
SynthesisTool: 'Xilinx Vivado'
ReferenceDesign: 'AXI-Stream DDR Memory Access : 3-AXIM'
SynthesisToolChipFamily: 'Zynq UltraScale+'
SynthesisToolDeviceName: 'xczu9eg-ffvb1156-2-e'
SynthesisToolPackageName: ''
SynthesisToolSpeedValue: ''