Keyword Spotting in Simulink
This example shows a Simulink® model that identifies a keyword in speech using a pretrained deep learning model. This model was trained to identify the keyword "yes". To learn about the model architecture and training, see Keyword Spotting in Noise Using MFCC and LSTM Networks.
Download Pretrained Keyword Spotting Network
Download and unzip the pretrained network and the standardization factors. The standardization factors are the global mean and standard deviation of the features used to train the model.
downloadFolder = matlab.internal.examples.downloadSupportFile("audio/examples","kwslstm.zip"); dataFolder = tempdir; netFolder = fullfile(dataFolder,"KeywordSpotting"); unzip(downloadFolder,netFolder) addpath(netFolder)
Model Description
The deep learning network was trained on mel-frequency cepstral coefficients (MFCC) computed using an audioFeatureExtractor. The MFCC block in the model has been configured to extract the same features that the network was trained on.
The MFCC block extracts feature vectors from the audio stream using 512-point analysis windows with 384-point overlap and then applies a buffer to output 16 feature vectors consisting of 39 features each. Buffering the feature vectors enables vectorized computations on the Stateful Predict block, which enables the system to keep pace with real time (given a short time delay).
After the MFCC block, the features are standardized using precomputed coefficients and then transposed so that time is along the second dimension.
The Stateful Predict block outputs a 2-element score vector for each feature vector. The scores are converted to decisions by picking the index of the maximum score. The decisions are converted to doubles and then upsampled to create a decision mask the same length as the corresponding audio.
open_system("KeywordSpotting2.slx")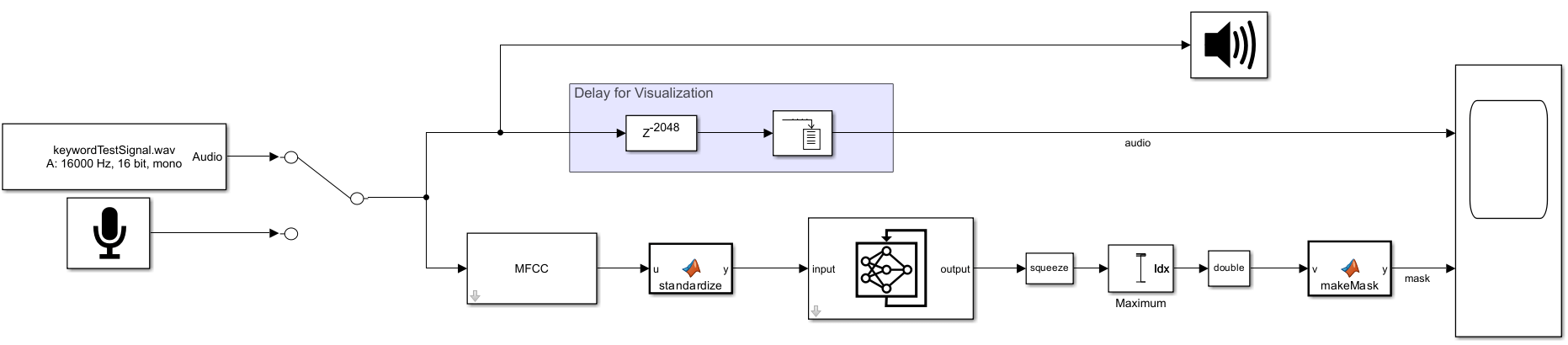
Run Model
Use the Manual Switch block to select either a live stream from your microphone or a test signal from an audio file.
sim("KeywordSpotting2.slx");
Close the model and remove the path to the pretrained network.
close_system("KeywordSpotting2.slx",0);
rmpath(netFolder)