Speech Command Recognition in Simulink
This example shows a Simulink® model that detects the presence of speech commands in audio. The model uses a pretrained convolutional neural network to recognize a given set of commands.
Speech Command Recognition Model
The model recognizes these speech commands:
"yes"
"no"
"up"
"down"
"left"
"right"
"on"
"off"
"stop"
"go"
The model uses a pretrained convolutional deep learning network. Refer to the example Train Speech Command Recognition Model Using Deep Learning for details on the architecture of this network and how you train it.
Open the model.
model = "cmdrecog";
open_system(model)
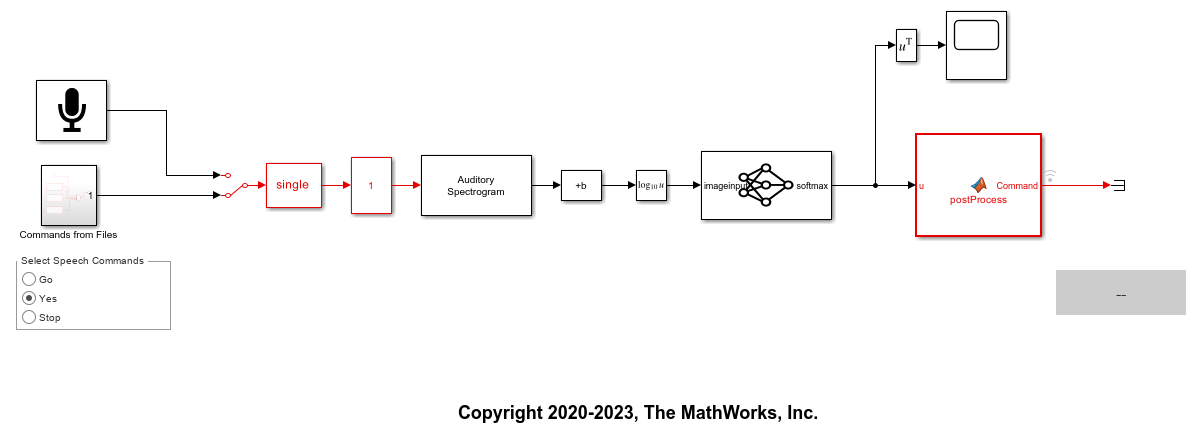
The model breaks the audio stream into one-second overlapping segments. A bark spectrogram is computed from each segment. The spectrograms are fed to the pretrained network.
Use the manual switch to select either a live stream from your microphone or read commands stored in audio files. For commands on file, use the rotary switch to select one of three commands (Go, Yes, or Stop).
Auditory Spectrogram Extraction
The deep learning network was trained on auditory spectrograms computed using an audioFeatureExtractor. The Auditory Spectrogram block in the model has been configured to extract the same features as the network was trained on.
Run the model
Simulate the model for 20 seconds.
set_param(model,StopTime="20"); open_system(model + "/Time Scope") sim(model);
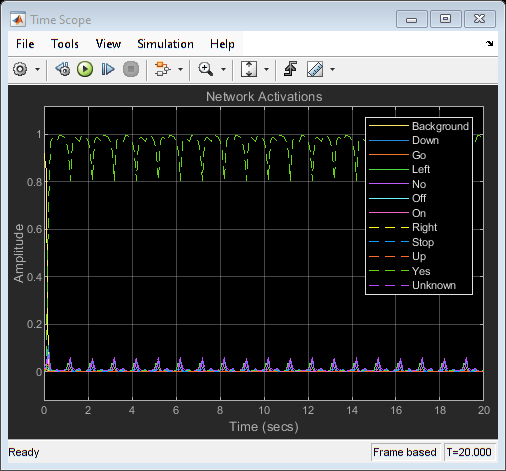
The recognized command is printed in the display block. The network activations, which give a level of confidence in the different supported commands, are displayed in a time scope.
Close the model.
close_system(model,0)
See Also
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)