Cette page s'applique à la version précédente. La page correspondante en anglais a été supprimée de la version actuelle.
Fonctionnement des réseaux de neurones dynamiques
Réseau de neurones feedforward et récurrents
Les réseaux dynamiques peuvent être divisés en deux catégories : ceux qui ne disposent que de connexions feedforward et ceux qui comportent également des connexions de feedback ou récurrentes. Pour comprendre les différences qui existent entre les réseaux statiques, dynamiques et récurrents, créez des réseaux et examinez la manière dont ils répondent à une séquence en entrée. (Vous voudrez peut-être revoir dans un premier temps Simulation avec des entrées séquentielles dans un réseau dynamique.)
Les commandes suivantes créent une séquence d’impulsions et la tracent :
p = {0 0 1 1 1 1 0 0 0 0 0 0};
stem(cell2mat(p))

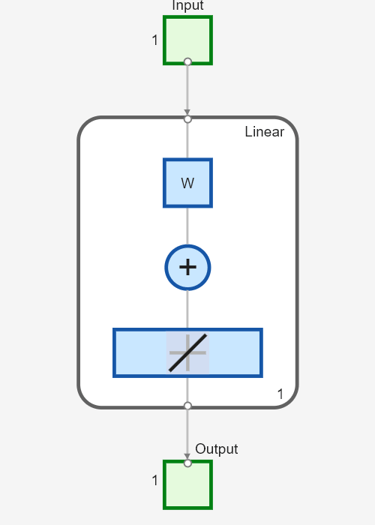
Créez à présent un réseau statique et découvrez la réponse du réseau à la séquence d'impulsions. Les commandes suivantes créent un réseau linéaire simple avec une couche, un neurone, aucun biais et un poids de 2 :
net = linearlayer;
net.inputs{1}.size = 1;
net.layers{1}.dimensions = 1;
net.biasConnect = 0;
net.IW{1,1} = 2;
view(net)
Vous pouvez à présent simuler la réponse du réseau à l'impulsion en entrée et la tracer :
a = net(p); stem(cell2mat(a))
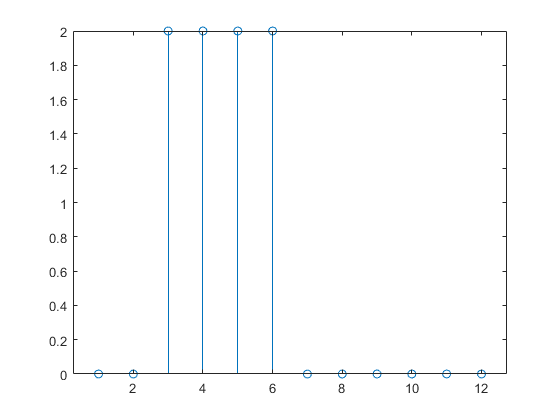
Remarque : la réponse du réseau statique dure aussi longtemps que l'impulsion en entrée. La réponse du réseau statique à un moment donné dépend uniquement de la valeur de la séquence d'entrée à ce même moment.
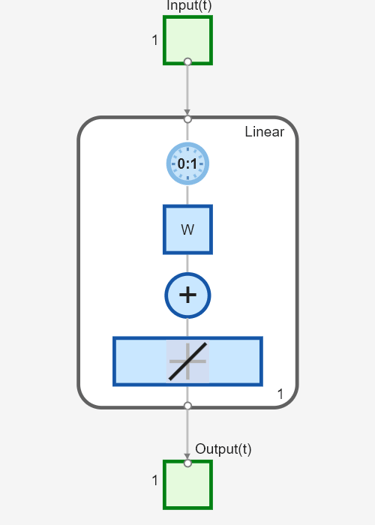
Créez à présent un réseau dynamique, mais sans aucune connexion de rétroaction (un réseau non récurrent). Vous pouvez utiliser le réseau que vous aviez utilisé dans Simulation avec des entrées concurrentes dans un réseau dynamique, qui était un réseau linéaire avec une ligne de retard sur l'entrée :
net = linearlayer([0 1]);
net.inputs{1}.size = 1;
net.layers{1}.dimensions = 1;
net.biasConnect = 0;
net.IW{1,1} = [1 1];
view(net)
Vous pouvez à nouveau simuler la réponse du réseau à l'impulsion en entrée et la tracer :
a = net(p); stem(cell2mat(a))
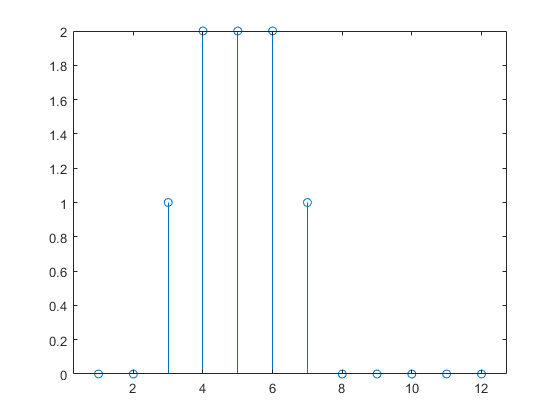
La réponse du réseau dynamique dure plus longtemps que l'impulsion en entrée. Le réseau dynamique est doté d’une mémoire. Sa réponse à un moment donné dépend non seulement de l'entrée actuelle, mais également de l'historique de la séquence en entrée. Si le réseau est dépourvu de connexions de rétroaction, seule une partie finie de l'historique a une incidence sur la réponse. Cette figure permet de constater que la réponse à l'impulsion dure un pas de temps de plus que la durée de l'impulsion. En effet, la ligne de retard sur l'entrée présente un retard maximal de 1.
Examinons à présent un réseau dynamique récurrent simple, représenté dans la figure suivante.
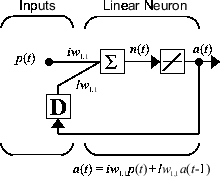
Vous pouvez créer le réseau, l’afficher et le simuler en utilisant les commandes suivantes. La commande narxnet est abordée dans .
net = narxnet(0,1,[],'closed');
net.inputs{1}.size = 1;
net.layers{1}.dimensions = 1;
net.biasConnect = 0;
net.LW{1} = .5;
net.IW{1} = 1;
view(net)

Les commandes suivantes tracent la réponse du réseau.
a = net(p); stem(cell2mat(a))

Vous remarquerez que les réseaux dynamiques récurrents donnent généralement une réponse plus longue que les réseaux dynamiques feedforward. En ce qui concerne les réseaux linéaires, les réseaux dynamiques feedforward sont dits à réponse impulsionnelle finie (FIR). En effet, la réponse à une impulsion en entrée devient nulle après d’un temps fini. Les réseaux dynamiques récurrents linéaires sont dits à réponse impulsionnelle infinie (IIR). En effet, la réponse à une impulsion peut décroître jusqu'à zéro (dans le cas d’un réseau stable), mais elle ne deviendra jamais exactement égale à zéro. La réponse impulsionnelle d’un réseau non linéaire ne peut pas être définie, mais les idées de réponses finies et infinies s'appliquent tout de même .
Applications des réseaux dynamiques
En règle générale, les réseaux dynamiques sont plus puissants que les réseaux statiques (bien qu'ils soient un peu plus difficiles à entraîner). Les réseaux dynamiques étant dotés d'une mémoire, ils peuvent être entraînés à apprendre des modèles séquentiels ou variant dans le temps. Ils trouvent leur place dans des domaines aussi divers que la prédiction sur les marchés financiers [RoJa96], l'égalisation de canal dans les systèmes de communication [FeTs03], la détection de phase dans les systèmes électriques [KaGr96], le tri [JaRa04], la détection des défauts [ChDa99], la reconnaissance vocale [Robin94], voire la prédiction de la structure des protéines en génétique [GiPr02]. Vous trouverez une discussion à propos des nombreux autres contextes d’utilisation des réseaux dynamiques dans [MeJa00].
Les réseaux de neurones dynamiques sont en particulier utilisés dans les systèmes de contrôle. Nous y reviendrons de manière plus détaillée dans . Les réseaux dynamiques conviennent tout aussi bien au filtrage. Vous constaterez que certains réseaux dynamiques linéaires sont utilisés pour le filtrage, mais que certaines de ces idées sont également développées en recourant aux réseaux dynamiques non linéaires.
Structures des réseaux dynamiques
Le logiciel Deep Learning Toolbox™ a été mis au point pour entraîner une classe de réseau appelée Layered Digital Dynamic Network (LDDN). Tout réseau pouvant être organisé sous la forme d'un LDDN peut être entraîné avec la toolbox. Voici une description basique d'un LDDN.
Chaque couche d'un LDDN est constituée des parties suivantes :
Un ensemble de matrices de poids qui arrivent dans cette couche (pouvant être connectées à d'autres couches ou entrées externes), une règle de fonction de poids associée utilisée pour combiner la matrice de poids avec son entrée (normalement la multiplication de matrices standard,
dotprod) et une ligne de retard associée.Un vecteur de biais
Une règle de fonction d'entrée nette utilisée pour combiner les sorties des différentes fonctions de poids avec les biais afin de produire l'entrée nette (généralement une jonction sommante,
netprod).Une fonction de transfert
Le réseau comporte des entrées qui sont connectées à des poids spéciaux, appelés poids d'entrée et notés IWi,j (net.IW{i,j} dans le code), où j désigne le numéro du vecteur en entrée qui entre dans le poids et i, le numéro de la couche à laquelle le poids est connecté. Les poids connectant une couche à une autre sont appelés poids de couche et sont désignés par LWi,j (net.LW{i,j} dans le code), où j désigne le numéro de la couche entrant dans le poids et i, le numéro de la couche à la sortie du poids.
La figure suivante est un exemple de LDDN à trois couches. La première couche est associée à trois poids : un poids d'entrée, un poids issu de la couche 1 et un poids issu de la couche 3. Les poids des deux couches sont associés à des lignes de retard.
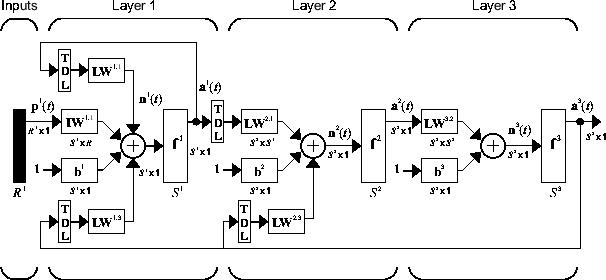
Le logiciel Deep Learning Toolbox peut être utilisé pour entraîner n'importe quel LDDN du moment où les fonctions de poids, les fonctions d'entrée nette et les fonctions de transfert disposent de dérivées. La plupart des architectures de réseaux dynamiques bien connues peuvent être représentées sous forme de LDDN. Plus loin dans cette rubrique, vous allez découvrir comment utiliser certaines commandes simples pour créer et entraîner plusieurs réseaux dynamiques très puissants. Nous avons choisi de ne pas aborder certains autres réseaux LDDN qui peuvent être créés en utilisant la commande de réseau générique, comme l’explique .
Apprentissage des réseaux dynamiques
Les réseaux dynamiques sont entraînés dans le logiciel Deep Learning Toolbox avec les algorithmes basés sur le gradient que nous avons décrits dans Réseaux de neurones peu profonds multicouches et apprentissage par rétropropagation. Vous pouvez faire votre choix parmi les fonctions d’apprentissage présentées dans cette rubrique. Des exemples vous sont présentés dans les sections suivantes.
Bien que les réseaux dynamiques puissent être entraînés avec les mêmes algorithmes basés sur le gradient que ceux utilisés pour les réseaux statiques, la performance des algorithmes sur les réseaux dynamiques peut varier énormément et le gradient doit être calculé de manière plus complexe. Examinons une nouvelle fois le réseau récurrent simple présenté dans cette figure.
Les poids ont deux effets différents sur la sortie du réseau. Tout d’abord, un effet direct : en effet, un changement de poids entraîne une modification immédiate de la sortie au pas de temps actuel. (Ce premier effet peut être calculé par une rétropropagation standard.) Ensuite, un effet indirect : en effet, certaines des entrées de la couche, telles que a(t - 1), sont également des fonctions des poids. Pour tenir compte de cet effet indirect, vous devez utiliser la rétropropagation dynamique pour calculer les gradients, ce qui réclame davantage de calculs. (Voir [DeHa01a], [DeHa01b] et [DeHa07].) Attendez-vous à ce que l’apprentissage de la rétropropagation dynamique prenne plus de temps, en partie pour cette raison. En outre, les surfaces d'erreur des réseaux dynamiques peuvent être plus complexes que celles des réseaux statiques. L‘apprentissage est plus susceptible d'être piégé dans des minima locaux. De ce faite, vous pouvez être amené à entraîner le réseau plusieurs fois avant d’obtenir un résultat optimal. Voir [DHH01] et [HDH09] pour en savoir plus sur l’apprentissage des réseaux dynamiques.
Les autres sections de cette rubrique indiquent comment créer, entraîner et appliquer certains réseaux dynamiques à des problèmes de modélisation, de détection et de prévision. Certains réseaux nécessitent une rétropropagation dynamique pour calculer les gradients, d'autres non. En tant qu'utilisateur, vous n'avez pas statuer sur la nécessité d’une rétropropagation dynamique. Le logiciel le détermine automatiquement et décide également de la meilleure forme de rétropropagation dynamique à utiliser. De votre côté, il vous suffit de créer le réseau et d'invoquer la commande train standard.