Importer des données dans Deep Network Designer
Remarque
Il est déconseillé d’utiliser Deep Network Designer pour importer des données et entraîner un réseau.
Pour importer et visualiser des données d’apprentissage et de validation dans Deep Network Designer, utilisez la syntaxe deepNetworkDesigner("-v1") existante.
Importer des données
Dans Deep Network Designer, vous pouvez importer des données de classification d'images à partir d'un datastore d'images ou d'un dossier contenant des sous-dossiers d'images de chaque classe. Sélectionnez une méthode d’importation en fonction du type de datastore que vous utilisez.
Importer un objet ImageDatastore | Importer n’importe quel autre objet du datastore (déconseillé pour ImageDatastore) |
|---|---|
Sélectionnez Import Data > Import Image Classification Data.
| Sélectionnez Import Data > Import Custom Data.
|
Importer des données par tâche
| Tâche | Type de données | Méthode d’importation de données |
|---|---|---|
| Classification d'images | Dossier avec des sous-dossiers contenant des images pour chaque classe. Les étiquettes de classe proviennent des noms des sous-dossiers. | Sélectionnez Import Data > Import Image Classification Data. |
Par exemple, créez un datastore d’images contenant des données numériques. unzip("DigitsData.zip"); dataFolder = "DigitsData"; imds = imageDatastore(dataFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames"); | ||
Par exemple, créez un datastore d’images augmentées contenant des données numériques. unzip("DigitsData.zip"); dataFolder = "DigitsData"; imds = imageDatastore(dataFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames"); imageAugmenter = imageDataAugmenter( ... 'RandRotation',[1,2]); augimds = augmentedImageDatastore([28 28],imds, ... 'DataAugmentation',imageAugmenter); augimds = shuffle(augimds); | Sélectionnez Import Data > Import Custom Data. | |
| Segmentation sémantique | Par exemple, associez un dataFolder = fullfile(toolboxdir('vision'), ... 'visiondata','triangleImages'); imageDir = fullfile(dataFolder,'trainingImages'); labelDir = fullfile(dataFolder,'trainingLabels'); imds = imageDatastore(imageDir); classNames = ["triangle","background"]; labelIDs = [255 0]; pxds = pixelLabelDatastore(labelDir,classNames,labelIDs); cds = combine(imds,pxds); | Sélectionnez Import Data > Import Custom Data. |
| Régression d’image à image | Par exemple, combinez des images bruitées en entrée et des images parfaites en sortie pour créer des données convenant à la régression d'image à image. unzip("DigitsData.zip"); dataFolder = "DigitsData"; imds = imageDatastore(dataFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames"); imds = transform(imds,@(x) rescale(x)); imdsNoise = transform(imds,@(x) {imnoise(x,'Gaussian',0.2)}); cds = combine(imdsNoise,imds); cds = shuffle(cds); | Sélectionnez Import Data > Import Custom Data. |
| Régression | Créez des données convenant à l'apprentissage des réseaux de régression en combinant des objets de datastore de type tableau. [XTrain,~,YTrain] = digitTrain4DArrayData; ads = arrayDatastore(XTrain,'IterationDimension',4, ... 'OutputType','cell'); adsAngles = arrayDatastore(YTrain,'OutputType','cell'); cds = combine(ads,adsAngles); | Sélectionnez Import Data > Import Custom Data. |
| Séquences et séries temporelles | Pour saisir les données de séquence du datastore de prédicteurs dans un réseau Deep Learning, les mini-batchs de séquences doivent présenter la même longueur. Vous pouvez utiliser la fonction Par exemple, remplissez les séquences afin qu’elles aient toutes la même longueur que la plus longue. [XTrain,YTrain] = japaneseVowelsTrainData;
XTrain = padsequences(XTrain,2);
adsXTrain = arrayDatastore(XTrain,'IterationDimension',3);
adsYTrain = arrayDatastore(YTrain);
cdsTrain = combine(adsXTrain,adsYTrain);Pour réduire la quantité de remplissage, vous pouvez utiliser un datastore de transformations et une fonction auxiliaire. Par exemple, remplissez les séquences afin qu’elles présentent toutes la même longueur que la plus longue. Vous pouvez également utiliser la même taille de mini-batch dans les options d’apprentissage. [XTrain,TTrain] = japaneseVowelsTrainData; miniBatchSize = 27; adsXTrain = arrayDatastore(XTrain,'OutputType',"same",'ReadSize',miniBatchSize); adsTTrain = arrayDatastore(TTrain,'ReadSize',miniBatchSize); tdsXTrain = transform(adsXTrain,@padToLongest); cdsTrain = combine(tdsXTrain,adsTTrain); function data = padToLongest(data) sequence = padsequences(data,2,Direction="left"); for n = 1:numel(data) data{n} = sequence(:,:,n); end end Vous pouvez également réduire la quantité de remplissage en triant vos données de la plus courte à la plus longue et réduire l'impact du remplissage en spécifiant la direction du remplissage. Pour plus d’informations sur les données de la séquence de remplissage, veuillez consulter Sequence Padding and Truncation. Vous pouvez également importer des données de séquence au moyen d’un objet de datastore personnalisé. Pour obtenir un exemple indiquant comment créer un datastore de séquences personnalisé, veuillez consulter Train Network Using Custom Mini-Batch Datastore for Sequence Data. | Sélectionnez Import Data > Import Custom Data. |
| Autres workflows étendus (entrée contenant des caractéristiques numériques, données hors mémoire, traitement d’images et traitement audio et de la parole) | Datastore Pour d’autres workflows étendus, utilisez un objet du datastore adapté. Par exemple, un datastore personnalisé, Par exemple, créez un objet dataFolder = fullfile(toolboxdir('images'),'imdata'); imds = imageDatastore(dataFolder,'FileExtensions',{'.jpg'}); dnds = denoisingImageDatastore(imds,... 'PatchesPerImage',512,... 'PatchSize',50,... 'GaussianNoiseLevel',[0.01 0.1]); Pour les données de tableaux d’une table, vous devez convertir vos données en un datastore convenant à l’apprentissage avec Deep Network Designer. Par exemple, commencez par convertir votre table en tableaux contenant les prédicteurs et réponses. Convertissez ensuite les tableaux en objets | Sélectionnez Import Data > Import Custom Data. |
Augmentation des images
En cas de problèmes de classification d'images, Deep Network Designer propose des options d'augmentation simples à appliquer aux données d'apprentissage. Ouvrez la boîte de dialogue Import Image Classification Data en sélectionnant Import Data > Import Image Classification Data. Vous pouvez sélectionner des options afin d’appliquer un ensemble aléatoire d'opérations de réflexion, de rotation, de changement d'échelle et de translation aux données d'apprentissage.
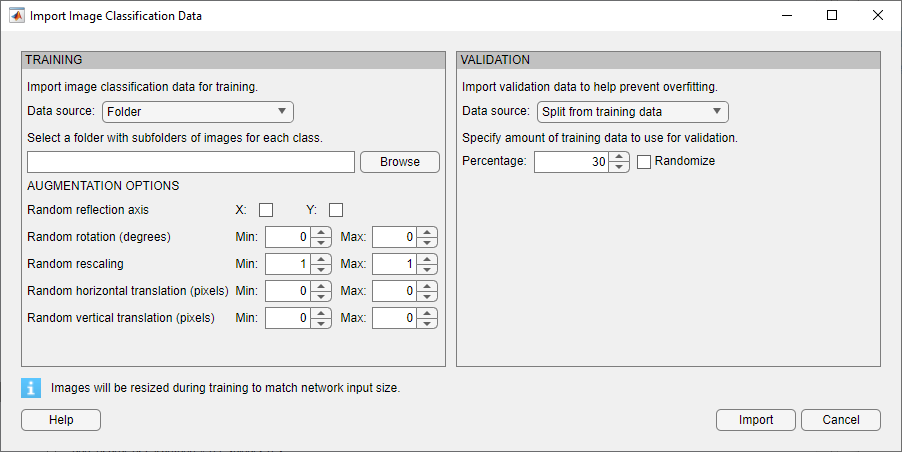
Pour réaliser des opérations de prétraitement d'images plus générales et plus complexes que celles proposées par Deep Network Designer, utilisez les objets TransformedDatastore et CombinedDatastore. Pour importer des objets CombinedDatastore et TransformedDatastore, sélectionnez Import Data > Import Custom Data.
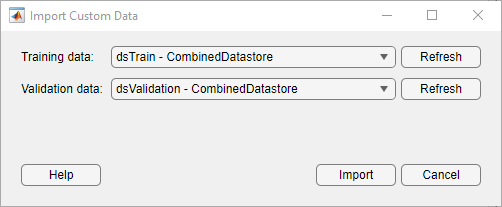
Pour plus d’informations sur l’augmentation des images, veuillez consulter Preprocess Images for Deep Learning.
Données de validation
Dans Deep Network Designer, vous pouvez importer des données de validation à utiliser pendant l’apprentissage. Vous pouvez surveiller les métriques de validation, comme la perte et la précision, afin d'évaluer si le réseau est surajusté (overfitting) ou sous-ajusté (underfitting) et d'ajuster les options d’apprentissage si nécessaire. Par exemple, si la perte pour la validation est beaucoup plus importante que la perte pour l'apprentissage, le réseau risque le surajustement.
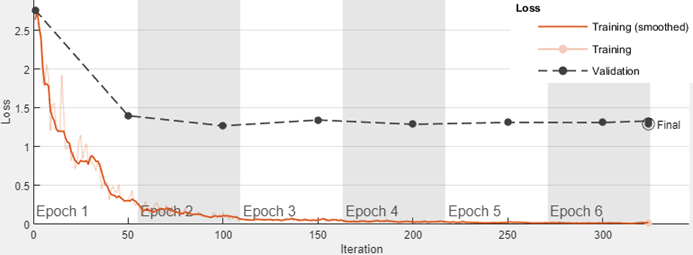
Dans Deep Network Designer, vous pouvez importer des données de validation à utiliser pendant l’apprentissage :
Depuis un datastore dans l’espace de travail.
Depuis un dossier contenant des sous-dossiers d’images pour chaque classe (données de classification d’images uniquement).
En séparant une partie des données d’apprentissage pour les utiliser comme données de validation (données de classification d’images uniquement). Les données sont séparées une fois entre un ensemble de validation et un ensemble d’apprentissage, avant l’apprentissage. Cette méthode est appelée validation holdout.
Séparer les données de validation des données d’apprentissage
Au moment de la séparation des données de validation holdout des données d'apprentissage, Deep Network Designer sépare un pourcentage des données d’apprentissage de chaque classe. Par exemple, supposons que vous disposiez d'un ensemble de données comportant deux classes, chat et chien, et que vous choisissiez d'utiliser 30 % des données d’apprentissage pour la validation. Deep Network Designer utilise les 30 derniers % des images avec le libellé « chat » et les 30 derniers % avec le libellé « dog » en tant qu’ensemble de validation.
Plutôt que d'utiliser les 30 derniers % des données d'apprentissage en tant que données de validation, vous pouvez choisir d'attribuer de manière aléatoire les observations aux ensembles d'apprentissage et de validation en cochant la case Randomize dans la boîte de dialogue Import Image Data. La randomisation des images peut améliorer la précision des réseaux entraînés sur des données stockées dans un ordre non aléatoire. Par exemple, l'ensemble de données numériques se compose de 10 000 images synthétiques en niveaux de gris de chiffres écrits à la main. Cet ensemble de données suit un ordre sous-jacent dans lequel les images présentant le même style d'écriture à la main apparaissent les unes à côté des autres au sein de chaque classe. Voici un exemple d’affichage.

Voir aussi
Deep Network Designer | TransformedDatastore | CombinedDatastore | imageDatastore | augmentedImageDatastore | splitEachLabel