Concepts in Multicore Programming
Basics of Multicore Programming
Multicore programming helps you create concurrent systems for deployment on multicore processor and multiprocessor systems. A multicore processor system is a single processor with multiple execution cores in one chip. By contrast, a multiprocessor system has multiple processors on the motherboard or chip. A multiprocessor system might include a Field-Programmable Gate Array (FPGA). An FPGA is an integrated circuit containing an array of programmable logic blocks and a hierarchy of reconfigurable interconnects. A processing node processes input data to produce outputs. It can be a processor in a multicore or multiprocessor system, or an FPGA.
The multicore programming approach can help when:
You want to take advantage of multicore and FPGA processing to increase the performance of an embedded system.
You want to achieve scalability so your deployed system can take advantage of increasing numbers of cores and FPGA processing power over time.
Concurrent systems that you create using multicore programming have multiple tasks executing in parallel. This is known as concurrent execution. When a processor executes multiple parallel tasks, it is known as multitasking. A CPU has firmware called a scheduler, which handles the tasks that execute in parallel. The CPU implements tasks using operating system threads. Your tasks can execute independently but have some data transfer between them, such as data transfer between a data acquisition module and controller for the system. Data transfer between tasks means that there is a data dependency.
Multicore programming is commonly used in signal processing and plant-control systems. In signal processing, you can have a concurrent system that processes multiple frames in parallel. In plant-control systems, the controller and the plant can execute as two separate tasks. Using multicore programming helps to split your system into multiple parallel tasks which run simultaneously.
Simulink® tries to optimize the host computer performance regardless of the modeling method you use. For more information on the ways that Simulink helps you to improve performance, see Optimize Performance.
To model a concurrently executing system, see Partitioning Guidelines.
Types of Parallelism
The concept of multicore programming is to have multiple system tasks executing in parallel. Types of parallelism include:
Data parallelism
Task parallelism
Pipelining
Data Parallelism
Data parallelism involves processing multiple pieces of data independently in parallel. The processor performs the same operation on each piece of data. You achieve parallelism by feeding the data in parallel.
The figure shows the timing diagram for this parallelism. The
input is divided into four chunks, A, B, C, and D. The same operation F() is
applied to each of these pieces and the output is OA,
OB, OC, and OD respectively.
All four tasks are identical, and they run in parallel.


The time taken per processor cycle, known as cycle time, is t = tF.
The total processing time is also tF, since
all four tasks run simultaneously. In the absence of parallelism,
all four pieces of data are processed by one processing node. The
cycle time is tF for each task but the total processing
time is 4*tF, since the pieces are processed in
succession.
You can use data parallelism in scenarios where it is possible to process each piece of input data independently. For example, a web database with independent data sets for processing or processing frames of a video independently are good candidates for data parallelism.
Task Parallelism
In contrast to data parallelism, task parallelism doesn’t split up the input data. Instead, it achieves parallelism by splitting up an application into multiple tasks. Task parallelism involves distributing tasks within an application across multiple processing nodes. Some tasks can have data dependency on others, so all tasks do not run at exactly the same time.
Consider a system that involves four functions. Functions F2a() and F2b() are in parallel, that is, they can run simultaneously. In task parallelism, you can divide your computation into two tasks. Function F2b() runs on a separate processing node after it gets data Out1 from Task 1, and it outputs back to F3() in Task 1.
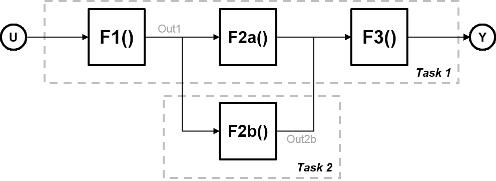
The figure shows the timing diagram for this parallelism. Task 2 does not run until it gets data Out1 from Task 1. Hence, these tasks do not run completely in parallel. The time taken per processor cycle, known as cycle time, is
t = tF1 + max(tF2a, tF2b) + tF3.

You can use task parallelism in scenarios such as a factory where the plant and controller run in parallel.
Model Pipeline Execution (Pipelining)
Use model pipeline execution, or pipelining, to work around the problem of task parallelism where threads do not run completely in parallel. This approach involves modifying your system model to introduce delays between tasks where there is a data dependency.
In this figure, the system is divided into three tasks to run on three different processing nodes, with delays introduced between functions. At each time step, each task takes in the value from the previous time step by way of the delay.

Each task can start processing at the same time, as this timing diagram shows. These tasks are truly parallel and they are no longer serially dependent on each other in one processor cycle. The cycle time does not have any additions but is the maximum processing time of all the tasks.
t = max(Task1, Task2, Task3) = max(tF1, tF2a, tF2b, tF3).

You can use pipelining wherever you can introduce delays artificially in your concurrently executing system. The resulting overhead due to this introduction must not exceed the time saved by pipelining.
System Partitioning for Parallelism
Partitioning methods help you to designate areas of your system for concurrent execution. Partitioning allows you to create tasks independently of the specifics of the target system on which the application is deployed.
Consider this system. F1–F6 are functions of the system that can be executed independently. An arrow between two functions indicates a data dependency. For example, the execution of F5 has a data dependency on F3.
Execution of these functions is assigned to the different processor nodes in the target system. The gray arrows indicate assignment of the functions to be deployed on the CPU or the FPGA. The CPU scheduler determines when individual tasks run. The CPU and FPGA communicate via a common communication bus.

The figure shows one possible configuration for partitioning. In general, you test different configurations and iteratively improve until you get the optimal distribution of tasks for your application.
Challenges in Multicore Programming
Manually coding your application onto a multicore processor or an FPGA poses challenges beyond the problems caused by manual coding. In concurrent execution, you must track:
Scheduling of the tasks that execute on the embedded processing system multicore processor
Data transfers to and from the different processing nodes
Simulink manages the implementation of tasks and data transfer between tasks. It also generates the code that is deployed for the application. For more information, see Multicore Programming with Simulink.
In addition to these challenges, there are challenges when you want to deploy your application to different architectures and when you want to improve the performance of the deployed application.
Portability: Deployment to Different Architectures
The hardware configuration that runs the deployed application is known as the architecture. It can contain multicore processors, multiprocessor systems, FPGAs, or a combination of these. Deployment of the same application to different architectures can require effort due to:
Different number and types of processor nodes on the architecture
Communication and data transfer standards for the architecture
Standards for certain events, synchronization, and data protection in each architecture
To deploy the application manually, you must reassign tasks to different processing nodes for each architecture. You might also need to reimplement your application if each architecture uses different standards.
Simulink helps overcome these problems by offering portability across architectures. For more information, see How Simulink Helps You to Overcome Challenges in Multicore Programming.
Deployment Efficiency
You can improve the performance of your deployed application by balancing the load of the different processing nodes in the multicore processing environment. You must iterate and improve upon your distribution of tasks during partitioning, as mentioned in System Partitioning for Parallelism. This process involves moving tasks between different processing nodes and testing the resulting performance. Since it is an iterative process, it takes time to find the most efficient distribution.
Simulink helps you to overcome these problems using profiling. For more information, see How Simulink Helps You to Overcome Challenges in Multicore Programming.
Cyclic Data Dependency
Some tasks of a system depend on the output of other tasks. The data dependency between tasks determines their processing order. Two or more partitions containing data dependencies in a cycle creates a data dependency loop, also known as an algebraic loop.
Simulink identifies loops in your system before deployment. For more information, see How Simulink Helps You to Overcome Challenges in Multicore Programming.