RegressionEnsemble
Ensemble regression
Description
RegressionEnsemble combines a set of trained
weak learner models and data on which these learners were trained. It can predict
ensemble response for new data by aggregating predictions from its weak
learners.
Creation
Create a regression ensemble object using fitrensemble.
Properties
Object Functions
compact | Reduce size of machine learning model |
crossval | Cross-validate machine learning model |
cvshrink | Cross-validate pruning and regularization of regression ensemble |
gather | Gather properties of Statistics and Machine Learning Toolbox object from GPU |
lime | Local interpretable model-agnostic explanations (LIME) |
loss | Regression error for regression ensemble model |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict | Predict responses using regression ensemble model |
predictorImportance | Estimates of predictor importance for regression ensemble of decision trees |
regularize | Find optimal weights for learners in regression ensemble |
removeLearners | Remove members of compact regression ensemble |
resubLoss | Resubstitution loss for regression ensemble model |
resubPredict | Predict response of regression ensemble by resubstitution |
resume | Resume training of regression ensemble model |
shapley | Shapley values |
shrink | Prune regression ensemble |
Examples
Load the carsmall data set. Consider a model that explains a car's fuel economy (MPG) using its weight (Weight) and number of cylinders (Cylinders).
load carsmall
X = [Weight Cylinders];
Y = MPG;Train a boosted ensemble of 100 regression trees using the LSBoost method. Specify that Cylinders is a categorical variable.
Mdl = fitrensemble(X,Y,'Method','LSBoost',... 'PredictorNames',{'W','C'},'CategoricalPredictors',2)
Mdl =
RegressionEnsemble
PredictorNames: {'W' 'C'}
ResponseName: 'Y'
CategoricalPredictors: 2
ResponseTransform: 'none'
NumObservations: 94
NumTrained: 100
Method: 'LSBoost'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [100×1 double]
FitInfoDescription: {2×1 cell}
Regularization: []
Properties, Methods
Mdl is a RegressionEnsemble model object that contains the training data, among other things.
Mdl.Trained is the property that stores a 100-by-1 cell vector of the trained regression trees (CompactRegressionTree model objects) that compose the ensemble.
Plot a graph of the first trained regression tree.
view(Mdl.Trained{1},'Mode','graph')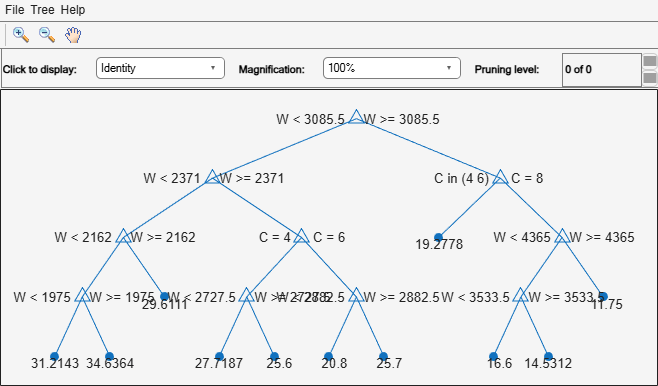
By default, fitrensemble grows shallow trees for boosted ensembles of trees.
Predict the fuel economy of 4,000 pound cars with 4, 6, and 8 cylinders.
XNew = [4000*ones(3,1) [4; 6; 8]]; mpgNew = predict(Mdl,XNew)
mpgNew = 3×1
19.5926
18.6388
15.4810
Tips
For an ensemble of regression trees, the Trained property
contains a cell vector of ens.NumTrained
CompactRegressionTree model objects. For a textual or graphical display of
tree t in the cell vector,
enter
view(ens.Trained{t})Extended Capabilities
Version History
Introduced in R2011aSee Also
ClassificationEnsemble | fitrensemble | CompactRegressionEnsemble | templateTree | view