oobQuantilePredict
Quantile predictions for out-of-bag observations from bag of regression trees
Syntax
Description
YFit = oobQuantilePredict(Mdl)Mdl.X, the predictor data, and using Mdl,
which is a bag of regression trees. Mdl must be
a TreeBagger model
object and Mdl.OOBIndices must be nonempty.
YFit = oobQuantilePredict(Mdl,Name,Value)Name,Value pair
arguments. For example, specify quantile probabilities or trees to
include for quantile estimation.
[ also returns a sparse
matrix of response
weights using any of the previous syntaxes.YFit,YW]
= oobQuantilePredict(___)
Input Arguments
Name-Value Arguments
Output Arguments
Examples
Load the carsmall data set. Consider a model that predicts the fuel economy (in MPG) of a car given its engine displacement.
load carsmallTrain an ensemble of bagged regression trees using the entire data set. Specify 100 weak learners and save out-of-bag indices.
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression',... 'OOBPrediction','on');
Mdl is a TreeBagger ensemble.
Perform quantile regression to predict the out-of-bag median fuel economy for all training observations.
oobMedianMPG = oobQuantilePredict(Mdl);
oobMedianMPG is an n-by-1 numeric vector of medians corresponding to the conditional distribution of the response given the sorted observations in Mdl.X. n is the number of observations, size(Mdl.X,1).
Sort the observations in ascending order. Plot the observations and the estimated medians on the same figure. Compare the out-of-bag median and mean responses.
[sX,idx] = sort(Mdl.X); oobMeanMPG = oobPredict(Mdl); figure; plot(Displacement,MPG,'k.'); hold on plot(sX,oobMedianMPG(idx)); plot(sX,oobMeanMPG(idx),'r--'); ylabel('Fuel economy'); xlabel('Engine displacement'); legend('Data','Out-of-bag median','Out-of-bag mean'); hold off;

Load the carsmall data set. Consider a model that predicts the fuel economy of a car (in MPG) given its engine displacement.
load carsmallTrain an ensemble of bagged regression trees using the entire data set. Specify 100 weak learners and save out-of-bag indices.
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression',... 'OOBPrediction','on');
Perform quantile regression to predict the out-of-bag 2.5% and 97.5% percentiles.
oobQuantPredInts = oobQuantilePredict(Mdl,'Quantile',[0.025,0.975]);oobQuantPredInts is an n-by-2 numeric matrix of prediction intervals corresponding to the out-of-bag observations in Mdl.X. n is number of observations, size(Mdl.X,1). The first column contains the 2.5% percentiles and the second column contains the 97.5% percentiles.
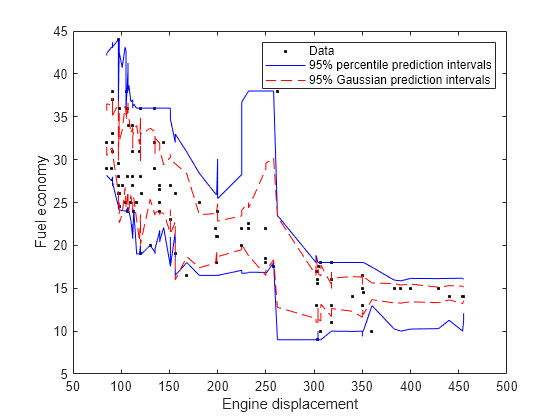
Plot the observations and the estimated medians on the same figure. Compare the percentile prediction intervals and the 95% prediction intervals, assuming the conditional distribution of MPG is Gaussian.
[oobMeanMPG,oobSTEMeanMPG] = oobPredict(Mdl); STDNPredInts = oobMeanMPG + [-1 1]*norminv(0.975).*oobSTEMeanMPG; [sX,idx] = sort(Mdl.X); figure; h1 = plot(Displacement,MPG,'k.'); hold on h2 = plot(sX,oobQuantPredInts(idx,:),'b'); h3 = plot(sX,STDNPredInts(idx,:),'r--'); ylabel('Fuel economy'); xlabel('Engine displacement'); legend([h1,h2(1),h3(1)],{'Data','95% percentile prediction intervals',... '95% Gaussian prediction intervals'}); hold off;
Load the carsmall data set. Consider a model that predicts the fuel economy of a car (in MPG) given its engine displacement.
load carsmallTrain an ensemble of bagged regression trees using the entire data set. Specify 100 weak learners and save the out-of-bag indices.
rng(1); % For reproducibility Mdl = TreeBagger(100,Displacement,MPG,'Method','regression',... 'OOBPrediction','on');
Estimate the out-of-bag response weights.
[~,YW] = oobQuantilePredict(Mdl);
YW is an n-by-n sparse matrix containing the response weights. n is the number of training observations, numel(Y). The response weights for the observation in Mdl.X(j,:) are in YW(:,j). Response weights are independent of any specified quantile probabilities.
Estimate the out-of-bag, conditional cumulative distribution function (ccdf) of the responses by:
Sorting the responses is ascending order, and then sorting the response weights using the indices induced by sorting the responses.
Computing the cumulative sums over each column of the sorted response weights.
[sortY,sortIdx] = sort(Mdl.Y); cpdf = full(YW(sortIdx,:)); ccdf = cumsum(cpdf);
ccdf(:,j) is the empirical out-of-bag ccdf of the response, given observation j.
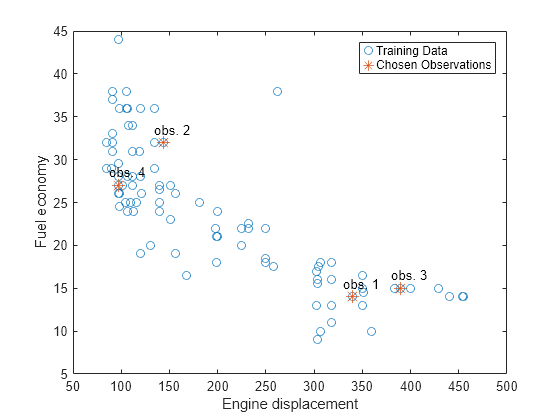
Choose a random sample of four training observations. Plot the training sample and identify the chosen observations.
[randX,idx] = datasample(Mdl.X,4); figure; plot(Mdl.X,Mdl.Y,'o'); hold on plot(randX,Mdl.Y(idx),'*','MarkerSize',10); text(randX-10,Mdl.Y(idx)+1.5,{'obs. 1' 'obs. 2' 'obs. 3' 'obs. 4'}); legend('Training Data','Chosen Observations'); xlabel('Engine displacement') ylabel('Fuel economy') hold off
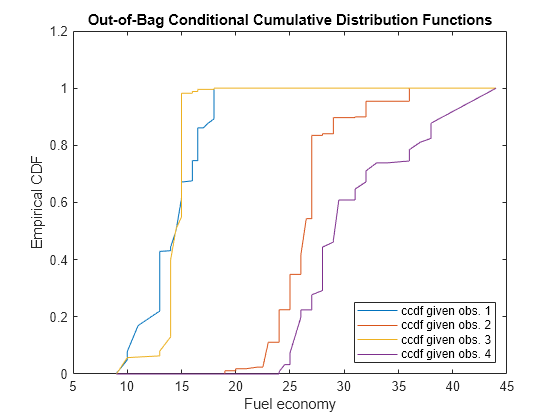
Plot the out-of-bag ccdf for the four chosen responses in the same figure.
figure; plot(sortY,ccdf(:,idx)); legend('ccdf given obs. 1','ccdf given obs. 2',... 'ccdf given obs. 3','ccdf given obs. 4',... 'Location','SouthEast') title('Out-of-Bag Conditional Cumulative Distribution Functions') xlabel('Fuel economy') ylabel('Empirical CDF')
More About
Algorithms
oobQuantilePredict estimates out-of-bag quantiles
by applying quantilePredict to all observations in the
training data (Mdl.X). For each observation, the
method uses only the trees for which the observation is out-of-bag.
For observations that are in-bag for all trees in the ensemble, oobQuantilePredict assigns
the sample quantile of the response data. In other words, oobQuantilePredict does
not use quantile regression for out-of-bag observations. Instead,
it assigns quantile(Mdl.Y,,
where tau)tau is the value of the Quantile name-value
pair argument.
References
[1] Meinshausen, N. “Quantile Regression Forests.” Journal of Machine Learning Research, Vol. 7, 2006, pp. 983–999.
[2] Breiman, L. “Random Forests.” Machine Learning. Vol. 45, 2001, pp. 5–32.
Version History
Introduced in R2016b