Visualize LDA Topic Probabilities of Documents
This example shows how to visualize the topic probabilities of documents using a latent Dirichlet allocation (LDA) topic model.
A latent Dirichlet allocation (LDA) model is a topic model which discovers underlying topics in a collection of documents and infers word probabilities in topics. You can use an LDA model to transform documents into a vector of topic probabilities, also known as a topic mixture. You can visualize the LDA topics using stacked bar charts.
Load LDA Model
Load the LDA model factoryReportsLDAModel which is trained using a data set of factory reports detailing different failure events. For an example showing how to fit an LDA model to a collection of text data, see Analyze Text Data Using Topic Models.
load factoryReportsLDAModel
mdlmdl =
ldaModel with properties:
NumTopics: 7
WordConcentration: 1
TopicConcentration: 0.5755
CorpusTopicProbabilities: [0.1587 0.1573 0.1551 0.1534 0.1340 0.1322 0.1093]
DocumentTopicProbabilities: [480×7 double]
TopicWordProbabilities: [158×7 double]
Vocabulary: ["item" "occasionally" "get" "stuck" "scanner" "spool" "loud" "rattling" "sound" "come" "assembler" "piston" "cut" "power" "start" "plant" "capacitor" "mixer" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
Visualize Topics Using Word Clouds
Visualize the topics using the wordcloud function.
numTopics = mdl.NumTopics; figure t = tiledlayout("flow"); title(t,"LDA Topics") for i = 1:numTopics nexttile wordcloud(mdl,i); title("Topic " + i) end

View Mixtures of Topics in Documents
Create an array of tokenized documents for a set of previously unseen documents using the same preprocessing function used when fitting the model.
The function preprocessText, listed in the Preprocessing Function section of the example, performs the following steps in order:
Tokenize the text using
tokenizedDocument.Lemmatize the words using
normalizeWords.Erase punctuation using
erasePunctuation.Remove a list of stop words (such as "and", "of", and "the") using
removeStopWords.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.
Prepare the text data for analysis using the preprocessText function.
str = [
"Coolant is pooling underneath assembler."
"Sorter blows fuses at start up."
"There are some very loud rattling sounds coming from the assembler."];
documents = preprocessText(str);Transform the documents into vectors of topic probabilities using the transform function. Note that for very short documents, the topic mixtures may not be a strong representation of the document content.
topicMixtures = transform(mdl,documents);
Visualize the first topic mixture in a bar chart and label the bars using the top three words from each topic.
numTopics = mdl.NumTopics; for i = 1:numTopics top = topkwords(mdl,3,i); topWords(i) = join(top.Word,", "); end figure bar(categorical(topWords),topicMixtures(1,:)) xlabel("Topic") ylabel("Probability") title("Document Topic Probabilities")

To visualize the proportions of the topics in each document, or to visualize multiple topic mixtures, use a stacked bar chart.
figure barh(topicMixtures,"stacked") title("Topic Mixtures") xlabel("Topic Probability") ylabel("Document") legend(topWords, ... Location="southoutside", ... NumColumns=2)
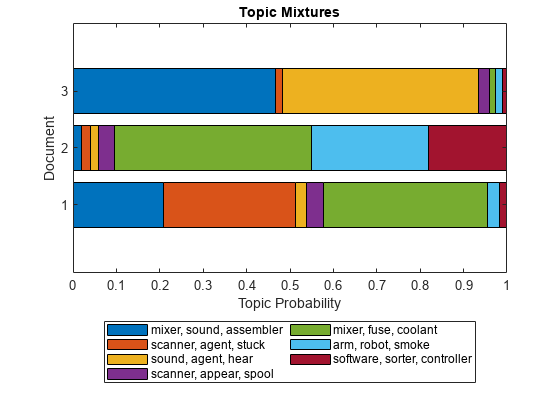
The regions of the stacked bar chart represent the proportion of the document belonging to the corresponding topic.
Preprocessing Function
The function preprocessText, performs the following steps in order:
Tokenize the text using
tokenizedDocument.Lemmatize the words using
normalizeWords.Erase punctuation using
erasePunctuation.Remove a list of stop words (such as "and", "of", and "the") using
removeStopWords.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.
function documents = preprocessText(textData) % Tokenize the text. documents = tokenizedDocument(textData); % Lemmatize the words. documents = addPartOfSpeechDetails(documents); documents = normalizeWords(documents,Style="lemma"); % Erase punctuation. documents = erasePunctuation(documents); % Remove a list of stop words. documents = removeStopWords(documents); % Remove words with 2 or fewer characters, and words with 15 or greater % characters. documents = removeShortWords(documents,2); documents = removeLongWords(documents,15); end
See Also
tokenizedDocument | fitlda | ldaModel | wordcloud