Object Detection Using YOLO v2 Deep Learning
This example shows how to train a You Only Look Once version 2 (YOLO v2) object detector.
Deep learning is a powerful machine learning technique that you can use to train robust object detectors. Several techniques for object detection exist, including Faster R-CNN and you only look once (YOLO) v2. This example trains a YOLO v2 vehicle detector using the trainYOLOv2ObjectDetector function. For more information, see Getting Started with YOLO v2.
Download Pretrained Detector
Download a pretrained detector to avoid having to wait for training to complete. If you want to train the detector, set the doTraining variable to true.
doTraining = false; if ~doTraining && ~exist("yolov2ResNet50VehicleExample_19b.mat","file") disp("Downloading pretrained detector (98 MB)..."); pretrainedURL = "https://www.mathworks.com/supportfiles/vision/data/yolov2ResNet50VehicleExample_19b.mat"; websave("yolov2ResNet50VehicleExample_19b.mat",pretrainedURL); end
Downloading pretrained detector (98 MB)...
Load Dataset
This example uses a small vehicle dataset that contains 295 images. Many of these images come from the Caltech Cars 1999 and 2001 data sets, created by Pietro Perona and used with permission. Each image contains one or two labeled instances of a vehicle. A small dataset is useful for exploring the YOLO v2 training procedure, but in practice, more labeled images are needed to train a robust detector. Unzip the vehicle images and load the vehicle ground truth data.
unzip vehicleDatasetImages.zip data = load("vehicleDatasetGroundTruth.mat"); vehicleDataset = data.vehicleDataset;
The vehicle data is stored in a two-column table. The first column contain the image file paths and the second column contain the bounding boxes. Display first few rows of the data set.
vehicleDataset(1:4,:)
ans=4×2 table
'vehicleImages/image_00001.jpg' [220,136,35,28]
'vehicleImages/image_00002.jpg' [175,126,61,45]
'vehicleImages/image_00003.jpg' [108,120,45,33]
'vehicleImages/image_00004.jpg' [124,112,38,36]
Add the full path to the local vehicle data folder.
vehicleDataset.imageFilename = fullfile(pwd,vehicleDataset.imageFilename);
Split the dataset into training, validation, and test sets. Select 60% of the data for training, 10% for validation, and the rest for testing the trained detector.
rng("default");
shuffledIndices = randperm(height(vehicleDataset));
idx = floor(0.6 * length(shuffledIndices) );
trainingIdx = 1:idx;
trainingDataTbl = vehicleDataset(shuffledIndices(trainingIdx),:);
validationIdx = idx+1 : idx + 1 + floor(0.1 * length(shuffledIndices) );
validationDataTbl = vehicleDataset(shuffledIndices(validationIdx),:);
testIdx = validationIdx(end)+1 : length(shuffledIndices);
testDataTbl = vehicleDataset(shuffledIndices(testIdx),:);Use imageDatastore and boxLabelDatastore to create datastores for loading the image and label data during training and evaluation.
imdsTrain = imageDatastore(trainingDataTbl{:,"imageFilename"});
bldsTrain = boxLabelDatastore(trainingDataTbl(:,"vehicle"));
imdsValidation = imageDatastore(validationDataTbl{:,"imageFilename"});
bldsValidation = boxLabelDatastore(validationDataTbl(:,"vehicle"));
imdsTest = imageDatastore(testDataTbl{:,"imageFilename"});
bldsTest = boxLabelDatastore(testDataTbl(:,"vehicle"));Combine image and box label datastores.
trainingData = combine(imdsTrain,bldsTrain); validationData = combine(imdsValidation,bldsValidation); testData = combine(imdsTest,bldsTest);
Display one of the training images and box labels.
data = read(trainingData);
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
Create YOLO v2 Object Detection Network
A YOLO v2 object detection network is composed of two subnetworks: a feature extraction network followed by a detection network. The feature extraction network is typically a pretrained CNN (for details, see Pretrained Deep Neural Networks (Deep Learning Toolbox)). This example uses ResNet-50 for feature extraction. You can also use other pretrained networks such as MobileNet v2 or ResNet-18 can also be used depending on application requirements. The detection sub-network is a small CNN compared to the feature extraction network and is composed of a few convolutional layers and layers specific for YOLO v2.
First, specify the network input size and the number of classes. When choosing the network input size, consider the minimum size required by the network itself, the size of the training images, and the computational cost incurred by processing data at the selected size. When feasible, choose a network input size that is close to the size of the training image and larger than the input size required for the network. To reduce the computational cost of running the example, specify a network input size of [224 224 3], which is the minimum size required to run the network.
inputSize = [224 224 3];
specify the names of object classes to detect.
classes = "vehicle";Note that the training images used in this example vary in size and are bigger than the network input size, 224-by-224. To correct this, resize the images in a preprocessing step prior to training.
Next, use estimateAnchorBoxes to estimate anchor boxes based on the size of objects in the training data. To account for the resizing of the images prior to training, resize the training data for estimating anchor boxes. Use transform to preprocess the training data, then define the number of anchor boxes and estimate the anchor boxes. Resize the training data to the input image size of the network using the supporting function preprocessData.
trainingDataForEstimation = transform(trainingData,@(data)preprocessData(data,inputSize)); numAnchors = 7; [anchorBoxes,meanIoU] = estimateAnchorBoxes(trainingDataForEstimation,numAnchors)
anchorBoxes = 7×2
40 38
156 127
74 71
135 121
36 25
56 52
98 89
meanIoU = 0.8383
For more information on choosing anchor boxes, see Estimate Anchor Boxes from Training Data and Anchor Boxes for Object Detection.
Load a pretrained ResNet-50 model.
baseNet = imagePretrainedNetwork("resnet50");Select "activation_40_relu" as the detection network source to replace the layers after "activation_40_relu" with the detection subnetwork. This detection network source layer outputs feature maps that are downsampled by a factor of 16. This amount of downsampling is a good tradeoff between spatial resolution and the strength of the extracted features, as features extracted further down the network encode stronger image features at the cost of spatial resolution. Choosing the optimal feature extraction layer requires empirical analysis.
detectionSource = "activation_40_relu";Create the YOLO v2 object detection network using the yolov2ObjectDetector object.
detector = yolov2ObjectDetector(baseNet,classes,anchorBoxes,DetectionNetworkSource=detectionSource);
You can visualize the network using analyzeNetwork or the Deep Network Designer (Deep Learning Toolbox) app.
Perform Data Augmentation
Data augmentation is used to improve network accuracy by randomly transforming the original data during training. By using data augmentation, you can add more variety to the training data without actually having to increase the number of labeled training samples.
Use transform to augment the training data by randomly flipping the image and associated box labels horizontally. Note that data augmentation is not applied to the test and validation data. Ideally, test and validation data should be representative of the original data and is left unmodified for unbiased evaluation.
augmentedTrainingData = transform(trainingData,@augmentData);
Read the same image multiple times and display the augmented training data.
augmentedData = cell(4,1); for k = 1:4 data = read(augmentedTrainingData); augmentedData{k} = insertShape(data{1},"rectangle",data{2}); reset(augmentedTrainingData); end figure montage(augmentedData,BorderSize=10)

Preprocess Training Data
Preprocess the augmented training data, and the validation data to prepare for training.
preprocessedTrainingData = transform(augmentedTrainingData,@(data)preprocessData(data,inputSize)); preprocessedValidationData = transform(validationData,@(data)preprocessData(data,inputSize));
Read the preprocessed training data.
data = read(preprocessedTrainingData);
Display the image and bounding boxes.
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
Train YOLO v2 Object Detector
Use trainingOptions to specify network training options. Set ValidationData to the preprocessed validation data. Set CheckpointPath to a temporary location. This enables the saving of partially trained detectors during the training process. If training is interrupted, such as by a power outage or system failure, you can resume training from the saved checkpoint.
options = trainingOptions("adam", ... MiniBatchSize=16, .... InitialLearnRate=1e-3, ... MaxEpochs=10, ... CheckpointPath=tempdir, ... ValidationData=preprocessedValidationData);
Use trainYOLOv2ObjectDetector function to train the YOLO v2 object detector if doTraining is true. Otherwise, load the pretrained network.
if doTraining % Train the YOLO v2 detector. [detector,info] = trainYOLOv2ObjectDetector(preprocessedTrainingData,detector,options); else % Load pretrained detector for the example. pretrained = load("yolov2ResNet50VehicleExample_19b.mat"); detector = pretrained.detector; end
Training this network took approximately 7 minutes using an NVIDIA™ Titan X GPU with 12 GB of memory. The training time varies depending on the hardware you use. If your GPU has less memory, you may run out of memory. If this happens, lower the MiniBatchSize using the trainingOptions function.
As a quick test, run the detector on a test image. Make sure you resize the image to the same size as the training images.
I = imread("highway.png");
I = imresize(I,inputSize(1:2));
[bboxes,scores] = detect(detector,I);Display the results.
I = insertObjectAnnotation(I,"rectangle",bboxes,scores);
figure
imshow(I)
Evaluate Detector Performance
Evaluate the trained object detector on a large set of images to measure the performance. In this example, compute the average precision (AP) and precision/recall metrics using the evaluateObjectDetection function to evaluate performance. The AP provides a single number that incorporates the ability of the detector to make correct classifications (precision) and the ability of the detector to find all relevant objects (recall).
Apply the same preprocessing transform to the test data as for the training data. Note that data augmentation is not applied to the test data. Test data should be representative of the original data and be left unmodified for unbiased evaluation.
preprocessedTestData = transform(testData,@(data)preprocessData(data,inputSize));
Run the detector on all the test images. Set the detection threshold to a low value to detect as many objects as possible. This helps you evaluate the detector precision across the full range of recall values.
detectionThreshold = 0.01; detectionResults = detect(detector,preprocessedTestData,Threshold=detectionThreshold);
Visualize and Evaluate Performance Interactively
You can interactively visualize and evaluate the performance of the detector against the ground truth using the Object Detector Analyzer app. The app runs the detector on the test set and computes metrics such as AP and mAP, plots precision-recall curves, and displays the detections on each image in the test set. You can visualize ground truth data alongside correct and incorrect detector predictions and quickly navigate to images where the detector made the most mistakes to better understand the performance. To launch the app, use the objectDetectorAnalyzer function.
objectDetectorAnalyzer(detectionResults,preprocessedTestData)
Compute Performance Metrics
Evaluate the object detector on the test data set using the evaluateObjectDetection function.
metrics = evaluateObjectDetection(detectionResults,preprocessedTestData);
Compute the average precision (AP) metric and the precision/recall (PR) curve. The precision/recall curve highlights how precise a detector is at varying levels of recall. The ideal precision is 1 at all recall levels. The use of more data can help improve the average precision but might require more training time.
AP = averagePrecision(metrics,ClassName="vehicle"); [precision, recall] = precisionRecall(metrics,ClassName="vehicle");
Plot the PR curve and display the AP.
figure
plot(recall{:},precision{:})
xlabel("Recall")
ylabel("Precision")
grid on
title("Average Precision = "+AP)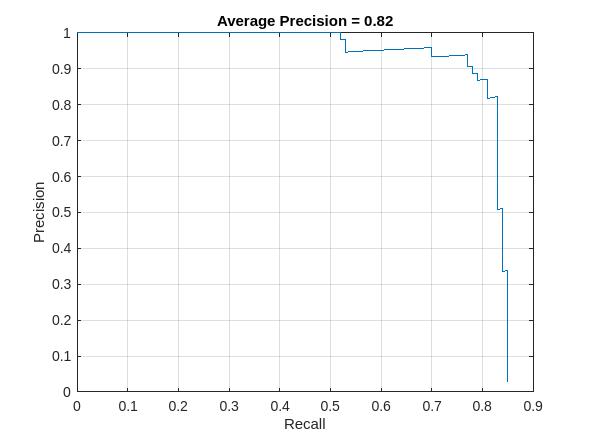
Code Generation
Once the detector is trained and evaluated, you can generate code for the yolov2ObjectDetector using GPU Coder™. See Code Generation for Object Detection by Using YOLO v2 (GPU Coder) example for more details.
Supporting Functions
function B = augmentData(A) % Apply random horizontal flipping, and random X/Y scaling. Boxes that get % scaled outside the bounds are clipped if the overlap is above 0.25. Also, % jitter image color. B = cell(size(A)); I = A{1}; sz = size(I); if numel(sz)==3 && sz(3) == 3 I = jitterColorHSV(I ,... Contrast=0.2, ... Hue=0, ... Saturation=0.1, ... Brightness=0.2); end % Randomly flip and scale image. tform = randomAffine2d(XReflection=true,Scale=[1 1.1]); rout = affineOutputView(sz,tform,BoundsStyle="CenterOutput"); B{1} = imwarp(I,tform,OutputView=rout); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to access this function. A{2} = helperSanitizeBoxes(A{2}); % Apply same transform to boxes. [B{2},indices] = bboxwarp(A{2},tform,rout,OverlapThreshold=0.25); B{3} = A{3}(indices); % Return original data only when all boxes are removed by warping. if isempty(indices) B = A; end end function data = preprocessData(data,targetSize) % Resize image and bounding boxes to the targetSize. sz = size(data{1},[1 2]); scale = targetSize(1:2)./sz; data{1} = imresize(data{1},targetSize(1:2)); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to access this function. data{2} = helperSanitizeBoxes(data{2}); % Resize boxes to new image size. data{2} = bboxresize(data{2},scale); end
References
[1] Redmon, Joseph, and Ali Farhadi. “YOLO9000: Better, Faster, Stronger.” In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517–25. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690.
See Also
yolov2ObjectDetector |
trainYOLOv2ObjectDetector | yoloxObjectDetector