La traduction de cette page n'est pas à jour. Cliquez ici pour voir la dernière version en anglais.
Transformée en ondelettes discrète à échantillonnage critique
Le calcul des coefficients d'ondelettes à toutes les échelles possibles représente une somme de travail considérable et génère une quantité impressionnante de données. Et si nous ne choisissions qu'un sous-ensemble d'échelles et de positions pour effectuer nos calculs ?
Il s'avère, de manière assez remarquable, que si nous choisissons des échelles et des positions basées sur des puissances de deux — dites échelles et positions dyadiques — alors notre analyse sera beaucoup plus efficace et tout aussi précise. Nous obtenons une telle analyse à partir de la transformée en ondelettes discrète (DWT). Pour plus d'informations sur la DWT, veuillez consulter Algorithms dans le Guide de l'utilisateur Wavelet Toolbox.
Une manière efficace d'implémenter ce schéma en utilisant des filtres a été développée en 1988 par Mallat (voir [Mal89] dans Références). L'algorithme de Mallat est en effet un schéma classique connu dans la communauté du traitement du signal comme un codeur de sous-bande à deux canaux (voir page 1 du livre Wavelets and Filter Banks, par Strang et Nguyen [StrN96]).
Cet algorithme de filtrage très pratique produit une transformée en ondelettes rapide — une boîte dans laquelle un signal passe et dont sortent rapidement des coefficients d'ondelettes. Examinons cela plus en détail.
Filtrage en une étape : Approximations et détails
Pour de nombreux signaux, le contenu à basse fréquence est la partie la plus importante. C'est ce qui confère au signal son identité. Le contenu haute fréquence, quant à lui, confère une saveur ou une nuance. Prenons la voix humaine. Si vous supprimez les composantes haute fréquence, la voix a un son différent, mais vous pouvez toujours savoir ce qui est dit. Cependant, si vous enlevez suffisamment de composantes de basse fréquence, vous entendez du charabia.
Dans l’analyse par ondelettes, on parle souvent d’approximations et de détails. Les approximations sont les composantes à grande échelle et à basse fréquence du signal. Les détails sont les composantes à petite échelle et à haute fréquence.
Le processus de filtrage, à son niveau le plus élémentaire, ressemble à ceci.
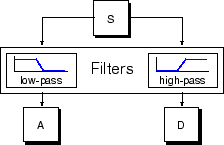
Le signal original, S, passe à travers deux filtres complémentaires et émerge sous la forme de deux signaux.
Malheureusement, si l'on effectue cette opération sur un vrai signal numérique, on se retrouve avec deux fois plus de données qu'au départ. Supposons, par exemple, que le signal d'origine S soit constitué de 1 000 échantillons de données. Les signaux résultants auront chacun 1 000 échantillons, pour un total de 2 000.
Ces signaux A et D sont intéressants, mais nous obtenons 2 000 valeurs au lieu des 1 000 que nous avions. Il existe une manière plus subtile d'effectuer la décomposition en utilisant des ondelettes. En regardant attentivement le calcul, on peut ne garder qu'un point sur deux dans chacun des deux échantillons de 2 000 longueurs pour obtenir l'information complète. Il s’agit de la notion de sous-échantillonage. Nous produisons deux séquences nommées cA et cD.
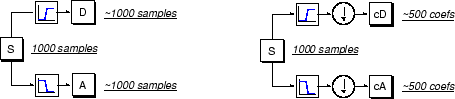
Le processus de droite, qui comprend le sous-échantillonnage, produit des coefficients DWT.
Pour mieux comprendre ce processus, effectuons une transformée en ondelettes discrète en une étape d'un signal. Notre signal sera une sinusoïde pure à laquelle on aura ajouté un bruit haute fréquence.
Voici notre schéma avec des signaux réels insérés dans celui-ci.
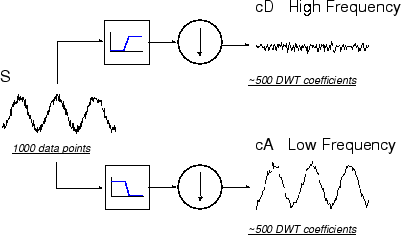
Le code MATLAB® nécessaire pour générer s, cD et cA est
s = sin(20.*linspace(0,pi,1000)) + 0.5.*rand(1,1000); [cA,cD] = dwt(s,'db2');
où db2 est le nom de l'ondelette que nous voulons utiliser pour l'analyse.
Remarquez que les coefficients de détail cD sont petits et consistent principalement en un bruit à haute fréquence, tandis que les coefficients d'approximation cA contiennent beaucoup moins de bruit que le signal d'origine.
[length(cA) length(cD)] ans = 501 501
Vous pouvez observer que les longueurs réelles des vecteurs de coefficients de détail et d'approximation sont légèrement supérieures à la moitié de la longueur du signal d'origine. Ceci est lié au processus de filtrage, qui est implémenté par convolution du signal avec un filtre. La convolution « étale » le signal, en introduisant plusieurs échantillons supplémentaires dans le résultat.
Décomposition à plusieurs niveaux
Le processus de décomposition peut être itéré, les approximations successives étant décomposées à leur tour, de sorte qu'un signal soit décomposé en de nombreuses composantes de résolution inférieure. Il s’agit de l'arbre de décomposition en ondelettes.
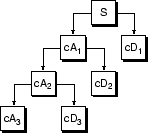
L'examen de l'arbre de décomposition en ondelettes d'un signal peut fournir des informations précieuses.
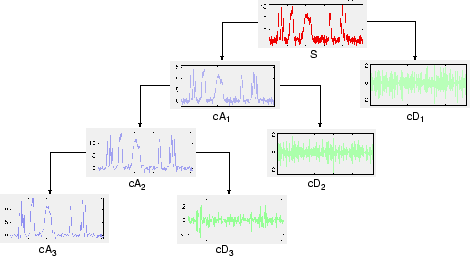
Nombre de niveaux
Le processus d'analyse étant itératif, il peut en théorie être poursuivi indéfiniment. En réalité, la décomposition ne peut se poursuivre que jusqu'à ce que les détails individuels soient constitués d'un seul échantillon ou pixel. En pratique, vous choisirez un nombre approprié de niveaux en fonction de la nature du signal, ou d'un critère approprié tel que l'entropie (voir Choosing Optimal Decomposition dans le Guide de l'utilisateur Wavelet Toolbox).