smooth
Smooth response data
Syntax
Description
yy = smooth(y)y using a moving average
filter.
The first few elements of yy
follow.
yy(1) = y(1) yy(2) = (y(1) + y(2) + y(3))/3 yy(3) = (y(1) + y(2) + y(3) + y(4) + y(5))/5 yy(4) = (y(2) + y(3) + y(4) + y(5) + y(6))/5 ...
smooth handles endpoints, the result differs from the result
returned by the filter function.Examples
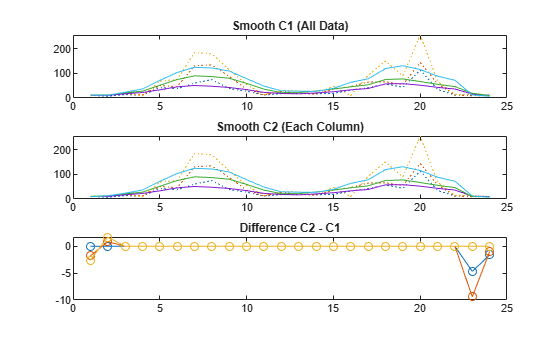
Smooth data by linear index and by each column separately, using a moving average filter. Plot and compare the results.
Load the data in count.dat. The 24-by-3 array count contains traffic counts at three intersections for each hour of the day.
load count.datSuppose that the data are from a single intersection over three consecutive days. Smoothing all the data together would then indicate the overall cycle of traffic flow through the intersection. Use a moving average filter with a 5-hour span to smooth all the data simultaneously (by linear index).
c = smooth(count(:)); C1 = reshape(c,24,3);
However, the data are in fact from three different intersections. Thus, smoothing columnwise gives a more meaningful picture of the traffic through each intersection in a day. Use the same moving average filter to smooth each column of the data separately.
C2 = zeros(24,3); for I = 1:3 C2(:,I) = smooth(count(:,I)); end
Plot the original data and the data smoothed by linear index and by each column separately. Then, plot the difference between the two smoothed data sets. The two methods give different results near the endpoints.
subplot(3,1,1) plot(count,':'); hold on plot(C1,'-'); title('Smooth C1 (All Data)') subplot(3,1,2) plot(count,':'); hold on plot(C2,'-'); title('Smooth C2 (Each Column)') subplot(3,1,3) plot(C2 - C1,'o-') title('Difference C2 - C1')
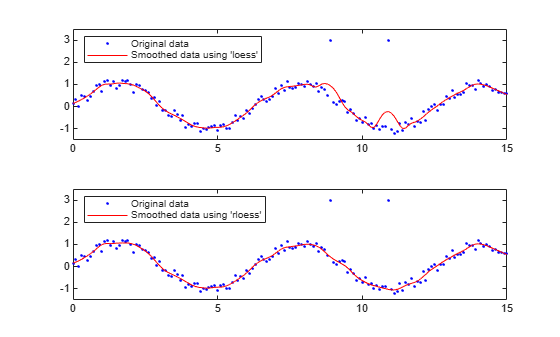
Plot and compare the results of data smoothed using the loess and rloess methods. Then determine which method is less sensitive to outliers.
Create noisy data with two outliers.
x = (0:0.1:15)'; y = sin(x) + 0.5*(rand(size(x))-0.5); y([90,110]) = 3;
Smooth the data with the loess and rloess methods. Use a span of 10% of the total number of data points.
yy1 = smooth(x,y,0.1,'loess'); yy2 = smooth(x,y,0.1,'rloess');
Plot the original and smoothed data. The outliers have less influence with the robust method rloess.
subplot(2,1,1) plot(x,y,'b.',x,yy1,'r-') set(gca,'YLim',[-1.5 3.5]) legend('Original data','Smoothed data using ''loess''',... 'Location','NW') subplot(2,1,2) plot(x,y,'b.',x,yy2,'r-') set(gca,'YLim',[-1.5 3.5]) legend('Original data','Smoothed data using ''rloess''',... 'Location','NW')
Input Arguments
Output Arguments
Tips
You can generate a smooth fit to your data using a smoothing spline. For more information, see
fit.
Alternative Functionality
You can also smooth data by using the MATLAB®
smoothdata function. With the exception of GPU array support, smoothdata includes all the functionality of the
smooth function and has some advantages. Unlike
smooth, the smoothdata function supports:
Matrices, tables, and timetables
Moving median and Gaussian methods
Option to specify how the
NaNvalues are treatedOption to substitute smoothed data for the original matrix or append smoothed data to the original matrix
Tall arrays, C/C++ code generation, and thread-based environments
Extended Capabilities
Version History
Introduced before R2006a