Generate Text Using Autoencoders
This example shows how to generate text data using autoencoders.
An autoencoder is a type of deep learning network that is trained to replicate its input. An autoencoder consists of two smaller networks: and encoder and a decoder. The encoder maps the input data to a feature vector in some latent space. The decoder reconstructs data using vectors in this latent space.
The training process is unsupervised. In other words, the model does not require labeled data. To generate text, you can use the decoder to reconstruct text from arbitrary input.
This example trains an autoencoder to generate text. The encoder uses a word embedding and an LSTM operation to map the input text into latent vectors. The decoder uses an LSTM operation and the same embedding to reconstruct the text from the latent vectors.
Load Data
The file sonnets.txt contains all of Shakespeare's sonnets in a single text file.
Read the Shakespeare's Sonnets data from the file "sonnets.txt".
filename = "sonnets.txt";
textData = fileread(filename);The sonnets are indented by two whitespace characters. Remove the indentations using replace and split the text into separate lines using the split function. Remove the header from the first nine elements and the short sonnet titles.
textData = replace(textData," ",""); textData = split(textData,newline); textData(1:9) = []; textData(strlength(textData)<5) = [];
Prepare Data
Create a function that tokenizes and preprocesses the text data. The function preprocessText, listed at the end of the example, performs these steps:
Prepends and appends each input string with the specified start and stop tokens, respectively.
Tokenize the text using
tokenizedDocument.
Preprocess the text data and specify the start and stop tokens "<start>" and "<stop>", respectively.
startToken = "<start>"; stopToken = "<stop>"; documents = preprocessText(textData,startToken,stopToken);
Create a word encoding object from the tokenized documents.
enc = wordEncoding(documents);
When training a deep learning model, the input data must be a numeric array containing sequences of a fixed length. Because the documents have different lengths, you must pad the shorter sequences with a padding value.
Recreate the word encoding to also include a padding token and determine the index of that token.
paddingToken = "<pad>";
newVocabulary = [enc.Vocabulary paddingToken];
enc = wordEncoding(newVocabulary);
paddingIdx = word2ind(enc,paddingToken)paddingIdx = 3595
Initialize Model Parameters
Initialize the parameters for the following model.
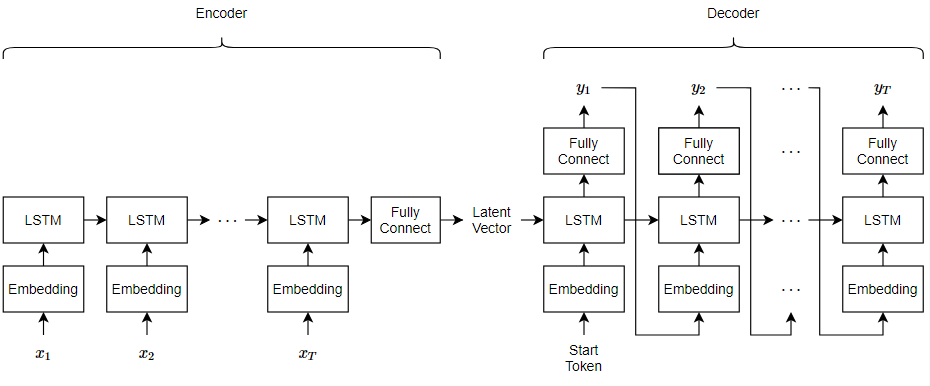
Here, is the sequence length, is the input sequence of word indices, and is the reconstructed sequence.
The encoder maps sequences of word indices to a latent vector by converting the input to sequences of word vectors using an embedding, inputting the word vector sequences into an LSTM operation, and applying a fully connected operation to the last time step of the LSTM output. The decoder reconstructs the input using an LSTM initialized the encoder output. For each time step, the decoder predicts the next time step and uses the output for the next time-step predictions. Both the encoder and the decoder use the same embedding.
Specify the dimensions of the parameters.
embeddingDimension = 100; numHiddenUnits = 150; latentDimension = 75; vocabularySize = enc.NumWords;
Create a struct for the parameters.
parameters = struct;
Initialize the weights of the embedding using the Gaussian using the initializeGaussian function which is attached to this example as a supporting file. Specify a mean of 0 and a standard deviation of 0.01. To learn more, see Gaussian Initialization.
sz = [embeddingDimension vocabularySize]; mu = 0; sigma = 0.01; parameters.emb.Weights = initializeGaussian(sz,mu,sigma);
Initialize the learnable parameters for the encoder LSTM operation:
Initialize the input weights with the Glorot initializer using the
initializeGlorotfunction which is attached to this example as a supporting file. To learn more, see Glorot Initialization.Initialize the recurrent weights with the orthogonal initializer using the
initializeOrthogonalfunction which is attached to this example as a supporting file. To learn more, see Orthogonal Initialization.Initialize the bias with the unit forget gate initializer using the
initializeUnitForgetGatefunction which is attached to this example as a supporting file. To learn more, see Unit Forget Gate Initialization.
sz = [4*numHiddenUnits embeddingDimension]; numOut = 4*numHiddenUnits; numIn = embeddingDimension; parameters.lstmEncoder.InputWeights = initializeGlorot(sz,numOut,numIn); parameters.lstmEncoder.RecurrentWeights = initializeOrthogonal([4*numHiddenUnits numHiddenUnits]); parameters.lstmEncoder.Bias = initializeUnitForgetGate(numHiddenUnits);
Initialize the learnable parameters for the encoder fully connected operation:
Initialize the weights with the Glorot initializer.
Initialize the bias with zeros using the
initializeZerosfunction which is attached to this example as a supporting file. To learn more, see Zeros Initialization.
sz = [latentDimension numHiddenUnits]; numOut = latentDimension; numIn = numHiddenUnits; parameters.fcEncoder.Weights = initializeGlorot(sz,numOut,numIn); parameters.fcEncoder.Bias = initializeZeros([latentDimension 1]);
Initialize the learnable parameters for the decoder LSTM operation:
Initialize the input weights with the Glorot initializer.
Initialize the recurrent weights with the orthogonal initializer.
Initialize the bias with the unit forget gate initializer.
sz = [4*latentDimension embeddingDimension]; numOut = 4*latentDimension; numIn = embeddingDimension; parameters.lstmDecoder.InputWeights = initializeGlorot(sz,numOut,numIn); parameters.lstmDecoder.RecurrentWeights = initializeOrthogonal([4*latentDimension latentDimension]); parameters.lstmDecoder.Bias = initializeZeros([4*latentDimension 1]);
Initialize the learnable parameters for the decoder fully connected operation:
Initialize the weights with the Glorot initializer.
Initialize the bias with zeros.
sz = [vocabularySize latentDimension]; numOut = vocabularySize; numIn = latentDimension; parameters.fcDecoder.Weights = initializeGlorot(sz,numOut,numIn); parameters.fcDecoder.Bias = initializeZeros([vocabularySize 1]);
To learn more about weight initialization, see Initialize Learnable Parameters for Model Function.
Define Model Encoder Function
Create the function modelEncoder, listed in the Encoder Model Function section of the example, that computes the output of the encoder model. The modelEncoder function, takes as input sequences of word indices, the model parameters, and the sequence lengths, and returns the corresponding latent feature vector. To learn more about defining a model encoder function, see Define Text Encoder Model Function.
Define Model Decoder Function
Create the function modelDecoder, listed in the Decoder Model Function section of the example, that computes the output of the decoder model. The modelDecoder function, takes as input sequences of word indices, the model parameters, and the sequence lengths, and returns the corresponding latent feature vector. To learn more about defining a model decoder function, see Define Text Decoder Model Function.
Define Model Loss Function
The modelLoss function, listed in the Model Loss Function section of the example, takes as input the model learnable parameters, the input data and a vector of sequence lengths for masking, and returns the loss, and the gradients of the loss with respect to the learnable parameters. To learn more about defining a model loss function, see Custom Training Loop Model Loss Functions.
Specify Training Options
Specify the options for training.
Train for 100 epochs with a mini-batch size of 128.
miniBatchSize = 128; numEpochs = 100;
Train with a learning rate of 0.01.
learnRate = 0.01;
Train Network
Train the network using a custom training loop.
Initialize the parameters for the Adam optimizer.
trailingAvg = []; trailingAvgSq = [];
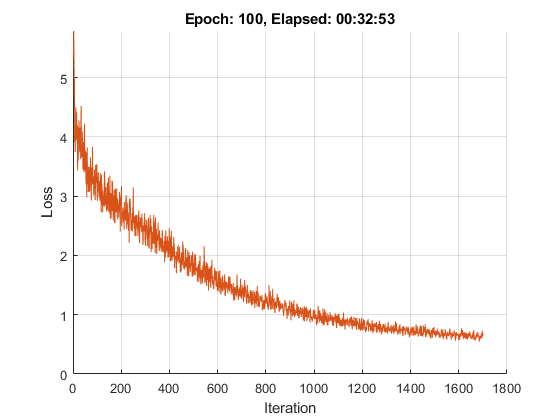
Initialize the training progress plot. Create an animated line that plots the loss against the corresponding iteration.
figure C = colororder; lineLossTrain = animatedline(Color=C(2,:)); xlabel("Iteration") ylabel("Loss") ylim([0 inf]) grid on
Train the model. For the first epoch, shuffle the data and loop over mini-batches of data.
For each mini-batch:
Convert the text data to sequences of word indices.
Convert the data to
dlarray.For GPU training, convert the data to
gpuArrayobjects.Compute loss and gradients.
Update the learnable parameters using the
adamupdatefunction.Update the training progress plot.
Train on a GPU if one is available. Using a GPU requires Parallel Computing Toolbox™ and a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox).
Training can take some time to run.
numObservations = numel(documents); numIterationsPerEpoch = floor(numObservations / miniBatchSize); iteration = 0; start = tic; for epoch = 1:numEpochs % Shuffle. idx = randperm(numObservations); documents = documents(idx); for i = 1:numIterationsPerEpoch iteration = iteration + 1; % Read mini-batch. idx = (i-1)*miniBatchSize+1:i*miniBatchSize; documentsBatch = documents(idx); % Convert to sequences. X = doc2sequence(enc,documentsBatch, ... PaddingDirection="right", ... PaddingValue=paddingIdx); X = cat(1,X{:}); % Convert to dlarray. X = dlarray(X,"BTC"); % If training on a GPU, then convert data to gpuArray. if canUseGPU X = gpuArray(X); end % Calculate sequence lengths. sequenceLengths = doclength(documentsBatch); % Evaluate model loss and gradients. [loss,gradients] = dlfeval(@modelLoss, parameters, X, sequenceLengths); % Update learnable parameters. [parameters,trailingAvg,trailingAvgSq] = adamupdate(parameters,gradients, ... trailingAvg,trailingAvgSq,iteration,learnRate); % Display the training progress. D = duration(0,0,toc(start),Format="hh:mm:ss"); loss = double(loss); addpoints(lineLossTrain,iteration,loss) title("Epoch: " + epoch + ", Elapsed: " + string(D)) drawnow end end
Generate Text
Generate text using closed loop generation by initializing the decoder with different random states. Closed loop generation is when the model generates data one time-step at a time and uses the previous prediction as input for the next prediction.
Specify to generate 3 sequences of length 16.
numGenerations = 3; sequenceLength = 16;
Create an array of random values to initialize the decoder state.
Z = dlarray(randn(latentDimension,numGenerations),"CB");If predicting on a GPU, then convert data to gpuArray.
if canUseGPU Z = gpuArray(Z); end
Make predictions using the modelPredictions function, listed at the end of the example. The modelPredictions function returns the output scores of the decoder given the model parameters, decoder initial state, maximum sequence length, word encoding, start token, and mini-batch size.
Y = modelDecoderPredictions(parameters,Z,sequenceLength,enc,startToken,miniBatchSize);
Find the word indices with the highest scores.
[~,idx] = max(Y,[],1); idx = squeeze(idx);
Convert the numeric indices to words and join them using the join function.
strGenerated = join(enc.Vocabulary(idx));
Extract the text before the first stop token using the extractBefore function. To prevent the function from returning missing when there are no stop tokens, append a stop token to the end of each sequence.
strGenerated = extractBefore(strGenerated+stopToken,stopToken);
Remove padding tokens.
strGenerated = erase(strGenerated,paddingToken);
The generation process introduces whitespace characters between each prediction, which means that some punctuation characters appear with unnecessary spaces before and after. Reconstruct the generated text by removing the spaces before and after the appropriate punctuation characters.
Remove the spaces that appear before the specified punctuation characters.
punctuationCharacters = ["." "," "’" ")" ":" ";" "?" "!"]; strGenerated = replace(strGenerated," " + punctuationCharacters,punctuationCharacters);
Remove the spaces that appear after the specified punctuation characters.
punctuationCharacters = ["(" "‘"]; strGenerated = replace(strGenerated,punctuationCharacters + " ",punctuationCharacters);
Remove leading and trailing white space using the strip function and view the generated text.
strGenerated = strip(strGenerated)
strGenerated = 3×1 string array
"me whose fool black grounded less waning travels less pine pine sing cool thrive kindness this"
"perjur'd outward a looks black, here might."
"birds him antique side his hours age,"
Encoder Model Function
The modelEncoder function, takes as input the model parameters, sequences of word indices, and the sequence lengths, and returns the corresponding latent feature vector.
Because the input data contains padded sequences of different lengths, the padding can have adverse effects on loss calculations. For the LSTM operation, instead of returning the output of the last time step of the sequence (which likely corresponds to the LSTM state after processing lots of padding values), determine the actual last time step given by the sequenceLengths input.
function Z = modelEncoder(parameters,X,sequenceLengths) % Embedding. weights = parameters.emb.Weights; Z = embed(X,weights); % LSTM. inputWeights = parameters.lstmEncoder.InputWeights; recurrentWeights = parameters.lstmEncoder.RecurrentWeights; bias = parameters.lstmEncoder.Bias; numHiddenUnits = size(recurrentWeights,2); hiddenState = zeros(numHiddenUnits,1,"like",X); cellState = zeros(numHiddenUnits,1,"like",X); Z1 = lstm(Z,hiddenState,cellState,inputWeights,recurrentWeights,bias); % Output mode 'last' with masking. miniBatchSize = size(Z1,2); Z = zeros(numHiddenUnits,miniBatchSize,"like",Z1); for n = 1:miniBatchSize t = sequenceLengths(n); Z(:,n) = Z1(:,n,t); end % Fully connect. weights = parameters.fcEncoder.Weights; bias = parameters.fcEncoder.Bias; Z = fullyconnect(Z,weights,bias,DataFormat="CB"); end
Decoder Model Function
The modelDecoder function, takes as input the model parameters, sequences of word indices, and the network state, and returns the decoded sequences.
Because the lstm function is stateful (when given a time series as input, the function propagates and updates the state between each time step) and that the embed and fullyconnect functions are time-distributed by default (when given a time series as input, the functions operate on each time step independently), the modelDecoder function supports both sequence and single time-step inputs.
function [Y,state] = modelDecoder(parameters,X,state) % Embedding. weights = parameters.emb.Weights; X = embed(X,weights); % LSTM. inputWeights = parameters.lstmDecoder.InputWeights; recurrentWeights = parameters.lstmDecoder.RecurrentWeights; bias = parameters.lstmDecoder.Bias; hiddenState = state.HiddenState; cellState = state.CellState; [Y,hiddenState,cellState] = lstm(X,hiddenState,cellState, ... inputWeights,recurrentWeights,bias); state.HiddenState = hiddenState; state.CellState = cellState; % Fully connect. weights = parameters.fcDecoder.Weights; bias = parameters.fcDecoder.Bias; Y = fullyconnect(Y,weights,bias); % Softmax. Y = softmax(Y); end
Model Loss Function
The modelLoss function takes as input the model learnable parameters, the input data X, and a vector of sequence lengths for masking, and returns the loss and the gradients of the loss with respect to the learnable parameters.
To calculate the masked loss, the model loss function uses the maskedCrossEntropy function, listed at the end of the example. To train the decoder to predict the next time-step of the sequence, specify the targets to be the input sequences shifted by one time-step.
To learn more about defining a model loss function, see Custom Training Loop Model Loss Functions.
function [loss,gradients] = modelLoss(parameters,X,sequenceLengths) % Model encoder. Z = modelEncoder(parameters,X,sequenceLengths); % Initialize LSTM state. state = struct; state.HiddenState = Z; state.CellState = zeros(size(Z),"like",Z); % Teacher forcing. Y = modelDecoder(parameters,X,state); % Loss. Y = Y(:,:,1:end-1); T = X(:,:,2:end); loss = mean(maskedCrossEntropy(Y,T,sequenceLengths)); % Gradients. gradients = dlgradient(loss,parameters); % Normalize loss for plotting. sequenceLength = size(X,3); loss = loss / sequenceLength; end
Model Predictions Function
The modelPredictions function returns the output scores of the decoder given the model parameters, decoder initial state, maximum sequence length, word encoding, start token, and mini-batch size.
function Y = modelDecoderPredictions(parameters,Z,maxLength,enc,startToken,miniBatchSize) numObservations = size(Z,2); numIterations = ceil(numObservations / miniBatchSize); startTokenIdx = word2ind(enc,startToken); vocabularySize = enc.NumWords; Y = zeros(vocabularySize,numObservations,maxLength,"like",Z); % Loop over mini-batches. for i = 1:numIterations idxMiniBatch = (i-1)*miniBatchSize+1:min(i*miniBatchSize,numObservations); miniBatchSize = numel(idxMiniBatch); % Initialize state. state = struct; state.HiddenState = Z(:,idxMiniBatch); state.CellState = zeros(size(Z(:,idxMiniBatch)),"like",Z); % Initialize decoder input. decoderInput = dlarray(repmat(startTokenIdx,[1 miniBatchSize]),"CBT"); % Loop over time steps. for t = 1:maxLength % Predict next time step. [Y(:,idxMiniBatch,t), state] = modelDecoder(parameters,decoderInput,state); % Closed loop generation. [~,idx] = max(Y(:,idxMiniBatch,t)); decoderInput = dlarray(idx,"CB"); end end end
Masked Cross Entropy Loss Function
The maskedCrossEntropy function calculates the loss between the specified input sequences and target sequences ignoring any time steps containing padding using the specified vector of sequence lengths.
function maskedLoss = maskedCrossEntropy(Y,T,sequenceLengths) numClasses = size(Y,1); miniBatchSize = size(Y,2); sequenceLength = size(Y,3); maskedLoss = zeros(sequenceLength,miniBatchSize,"like",Y); for t = 1:sequenceLength T1 = single(oneHot(T(:,:,t),numClasses)); mask = (t<=sequenceLengths)'; maskedLoss(t,:) = mask .* crossentropy(Y(:,:,t),T1); end maskedLoss = sum(maskedLoss,1); end
Text Preprocessing Function
The function preprocessText performs these steps:
Prepends and appends each input string with the specified start and stop tokens, respectively.
Tokenize the text using
tokenizedDocument.
function documents = preprocessText(textData,startToken,stopToken) % Add start and stop tokens. textData = startToken + textData + stopToken; % Tokenize the text. documents = tokenizedDocument(textData,'CustomTokens',[startToken stopToken]); end
One-Hot Encoding Function
The oneHot function converts an array of numeric indices to one-hot encoded vectors.
function oh = oneHot(idx, outputSize) miniBatchSize = numel(idx); oh = zeros(outputSize,miniBatchSize); for n = 1:miniBatchSize c = idx(n); oh(c,n) = 1; end end
See Also
dlfeval | dlgradient | dlarray