update
Syntax
Description
update efficiently updates the state distribution in
real time by applying one recursion of the Kalman filter to compute
state-distribution moments for the final period of the specified response data.
To compute state-distribution moments by recursive application of the Kalman filter for
each period in the specified response data, use filter instead.
[
returns the updated state-distribution moments at the final time T,
conditioned on the current state distribution, by applying one recursion of the Kalman
filter to the fully specified, standard state-space
model
nextState,NextStateCov] = update(Mdl,Y)Mdl given T observed responses
Y. nextState and
NextStateCov are the mean and covariance, respectively, of the
updated state distribution.
[
initializes the Kalman filter at the current state distribution with mean
nextState,NextStateCov] = update(Mdl,Y,currentState,CurrentStateCov)currentState and covariance matrix
CurrentStateCov.
[
uses additional options specified by one or more name-value arguments, and uses any of the
input-argument combinations in the previous syntaxes. For example,
nextState,NextStateCov] = update(___,Name,Value)update(Mdl,Y,Params=params,SquareRoot=true) sets unknown parameters in
the partially specified model Mdl to the values in
params, and specifies use of the square-root Kalman filter variant for
numerical stability.
[
also returns the loglikelihoods computed for each observation in
nextState,NextStateCov,logL] = update(___)Y.
Examples
Suppose that a latent process is an AR(1). The state equation is
where is Gaussian with mean 0 and standard deviation 1.
Generate a random series of 100 observations from , assuming that the series starts at 1.5.
T = 100;
ARMdl = arima(AR=0.5,Constant=0,Variance=1);
x0 = 1.5;
rng(1); % For reproducibility
x = simulate(ARMdl,T,Y0=x0);Suppose further that the latent process is subject to additive measurement error. The observation equation is
where is Gaussian with mean 0 and standard deviation 0.75. Together, the latent process and observation equations compose a state-space model.
Use the random latent state process (x) and the observation equation to generate observations.
y = x + 0.75*randn(T,1);
Specify the four coefficient matrices.
A = 0.5; B = 1; C = 1; D = 0.75;
Specify the state-space model using the coefficient matrices.
Mdl = ssm(A,B,C,D)
Mdl =
State-space model type: ssm
State vector length: 1
Observation vector length: 1
State disturbance vector length: 1
Observation innovation vector length: 1
Sample size supported by model: Unlimited
State variables: x1, x2,...
State disturbances: u1, u2,...
Observation series: y1, y2,...
Observation innovations: e1, e2,...
State equation:
x1(t) = (0.50)x1(t-1) + u1(t)
Observation equation:
y1(t) = x1(t) + (0.75)e1(t)
Initial state distribution:
Initial state means
x1
0
Initial state covariance matrix
x1
x1 1.33
State types
x1
Stationary
Mdl is an ssm model. Verify that the model is correctly specified using the display in the Command Window. The software infers that the state process is stationary. Subsequently, the software sets the initial state mean and covariance to the mean and variance of the stationary distribution of an AR(1) model.
Filter the observations through the state-space model, in real time, to obtain the state distribution for period 100.
[rtfX100,rtfXVar100] = update(Mdl,y)
rtfX100 = 1.2073
rtfXVar100 = 0.3714
update applies the Kalman filter to all observations in y, and returns the state estimate of only period 100.
Compare the result to the results of filter.
[fX,~,output] = filter(Mdl,y); size(fX)
ans = 1×2
100 1
fX100 = fX(100)
fX100 = 1.2073
fXVar100 = output(end).FilteredStatesCov
fXVar100 = 0.3714
tol = 1e-10; discrepancyMeans = fX100 - rtfX100; discrepancyVars = fXVar100 - rtfXVar100; areMeansEqual = norm(discrepancyMeans) < tol
areMeansEqual = logical
1
areVarsEqual = norm(discrepancyVars) < tol
areVarsEqual = logical
1
Like update, the filter function filters the observations through the model, but it returns all intermediate state estimates. Because update returns only the final state estimate, it is more suited to real-time calculations than filter.
Consider the simulated data and state-space model in Compute Only Final State Distribution from Kalman Filter.
T = 100;
ARMdl = arima(AR=0.5,Constant=0,Variance=1);
x0 = 1.5;
rng(1); % For reproducibility
x = simulate(ARMdl,T,Y0=x0);
y = x + 0.75*randn(T,1);
A = 0.5;
B = 1;
C = 1;
D = 0.75;
Mdl = ssm(A,B,C,D);Suppose observations are available sequentially, and consider obtaining the updated state distribution by filtering each new observation as it is available.
Simulate the following procedure using a loop.
Create variables that store the initial state distribution moments.
Filter the incoming observation through the model specifying the current initial state distribution moments.
Overwrite the current state distribution moments with the new state distribution moments.
Repeat steps 2 and 3 as new observations are available.
currentState = Mdl.Mean0; currentStateCov = Mdl.Cov0; newState = zeros(T,1); newStateCov = zeros(T,1); for j = 1:T [newState(j),newStateCov(j)] = update(Mdl,y(j),currentState,currentStateCov); currentState = newState(j); currentStateCov = newStateCov(j); end
Plot the observations, true state values, and new state means of each period.
figure plot(1:T,x,'-k',1:T,y,'*g',1:T,newState,':r','LineWidth',2) xlabel("Period") legend(["True state values" "Observations" "New state values"])
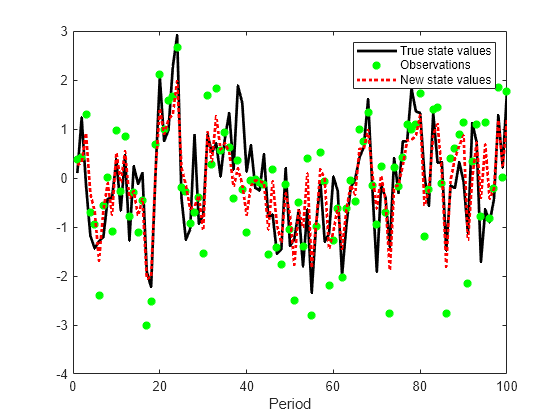
Compare the results to the results of filter.
tol = 1e-10; [fX,~,output] = filter(Mdl,y); discrepancyMeans = fX - newState; discrepancyVars = [output.FilteredStatesCov]' - newStateCov; areMeansEqual = norm(discrepancyMeans) < tol
areMeansEqual = logical
1
areVarsEqual = norm(discrepancyVars) < tol
areVarsEqual = logical
1
The real-time filter update, applied to the entire data set sequentially, returns the same state distributions as filter.
Consider that the linear relationship between the change in the unemployment rate and the nominal gross national product (nGNP) growth rate is of interest. Suppose the innovations of a mismeasured regression of the first difference of the unemployment rate onto the nGNP growth rate is an ARMA(1,1) series with Gaussian disturbances (that is, a regression model with ARMA(1,1) errors and measurement error). Symbolically, and in state-space form, the model is
where:
is the ARMA error series in the regression model.
is a dummy state for the MA(1) effect.
is the observed change in the unemployment rate being deflated by the growth rate of nGNP ().
is a Gaussian series of disturbances having mean 0 and standard deviation 1.
is a Gaussian series of measurement errors with scale .
Load the Nelson-Plosser data set, which contains the unemployment rate and nGNP series, among other measurements.
load Data_NelsonPlosserPreprocess the data by following this procedure:
Remove the leading missing observations.
Convert the nGNP series to a return series by using
price2ret.Apply the first difference to the unemployment rate series.
vars = ["GNPN" "UR"]; DT = rmmissing(DataTable(:,vars)); T = size(DT,1) - 1; % Sample size after differencing Z = [ones(T,1) price2ret(DT.GNPN)]; y = diff(DT.UR);
Though this example removes missing values, the Kalman filter accommodates series containing missing values.
Specify the coefficient matrices.
A = [NaN NaN; 0 0]; B = [1; 1]; C = [1 0]; D = NaN;
Specify the state-space model using ssm.
Mdl = ssm(A,B,C,D);
Fit the model to all observations except for the final 10 observations (a holdout sample). Use a random set of initial parameter values for optimization. Specify the regression component and its initial value for optimization using the 'Predictors' and 'Beta0' name-value arguments, respectively. Restrict the estimate of to all positive, real numbers.
fh = 10; params0 = [0.3 0.2 0.2]; [EstMdl,estParams] = estimate(Mdl,y(1:T-fh),params0,'Predictors',Z(1:T-fh,:), ... 'Beta0',[0.1 0.2],'lb',[-Inf,-Inf,0,-Inf,-Inf]);
Method: Maximum likelihood (fmincon)
Sample size: 51
Logarithmic likelihood: -87.2409
Akaike info criterion: 184.482
Bayesian info criterion: 194.141
| Coeff Std Err t Stat Prob
----------------------------------------------------------
c(1) | -0.31780 0.37357 -0.85071 0.39493
c(2) | 1.21242 0.82223 1.47455 0.14034
c(3) | 0.45583 1.32970 0.34281 0.73174
y <- z(1) | 1.32407 0.26525 4.99179 0
y <- z(2) | -24.48733 1.89161 -12.94520 0
|
| Final State Std Dev t Stat Prob
x(1) | -0.38117 0.42842 -0.88971 0.37363
x(2) | 0.23402 0.66222 0.35339 0.72380
EstMdl is an ssm model.
Nowcast the unemployment rate into the forecast horizon. Simulate this procedure using a loop:
Compute the current state distribution moments by filtering all in-sample observations through the estimated model.
When an observation is available in the forecast horizon, filter it through the model.
EstMdldoes not store the regression coefficients, so you must pass them in using the name-value argumentBeta.Set the current state distribution state moments to the nowcasts.
Repeat steps 2 and 3 when new observations are available.
[currentState,currentStateCov] = update(EstMdl,y(1:T-fh), ... Predictors=Z(1:T-fh,:),Beta=estParams(end-1:end)); unrateF = zeros(fh,2); unrateCovF = cell(fh,1); for j = 1:fh [unrateF(j,:),unrateCovF{j}] = update(EstMdl,y(T-fh+j),currentState,currentStateCov, ... Predictors=Z(T-fh+j,:),Beta=estParams(end-1:end)); currentState = unrateF(j,:)'; currentStateCov = unrateCovF{j}; end
Plot the estimated, filtered states. Recall that the first state is the change in the unemployment rate, and the second state helps build the first.
figure plot(dates((end-fh+1):end),[unrateF(:,1) y((end-fh+1):end)]); xlabel('Period') ylabel('Change in the unemployment rate') title('Filtered Change in the Unemployment Rate')
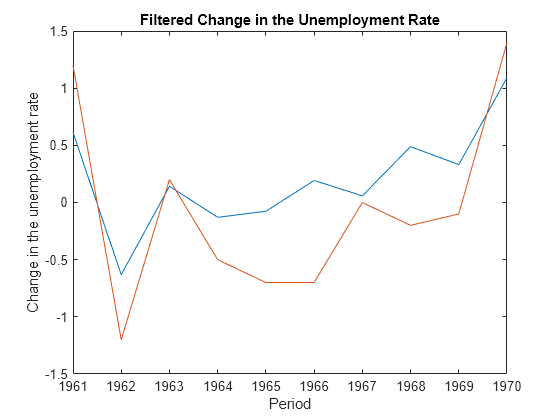
The filter function returns only the sum of the loglikelihoods for specified observations. To efficiently compute the loglikelihood of each observation, which can be convenient for custom estimation techniques, use update instead.
Consider the simulated data and state-space model in Compute Only Final State Distribution from Kalman Filter.
T = 100;
ARMdl = arima(AR=0.5,Constant=0,Variance=1);
x0 = 1.5;
rng(1); % For reproducibility
x = simulate(ARMdl,T,Y0=x0);
y = x + 0.75*randn(T,1);
A = 0.5;
B = 1;
C = 1;
D = 0.75;
Mdl = ssm(A,B,C,D);Evaluate the likelihood function for each observation.
[~,~,logLj] = update(Mdl,y);
logL is a 100-by-1 vector; logL(j) is the loglikelihood evaluated at observation j.
Use filter to evaluate the likelihood for the entire data set.
[~,logL] = filter(Mdl,y);
logL is a scalar representing the full data likelihood.
Because the software assumes the sample is randomly drawn, the likelihood for all observations is the sum of the individual loglikelihood values. Confirm this fact.
tol = 1e-10; discrepancy = logL - sum(logLj); areEqual = discrepancy < tol
areEqual = logical
1
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
The Kalman filter accommodates missing data by not updating filtered state estimates corresponding to missing observations. In other words, suppose there is a missing observation at period t. Then, the state forecast for period t based on the previous t – 1 observations and filtered state for period t are equivalent.
For explicitly defined state-space models,
updateapplies all predictors to each response series. However, each response series has its own set of regression coefficients.For efficiency,
updatedoes minimal input validation.In theory, the state covariance matrix must be symmetric and positive semi-definite.
updateforces symmetry of the covariance matrix before it applies the Kalman filter, but it does not check whether the matrix is positive semi-definite.
Alternative Functionality
To obtain filtered states for each period in the response data, call the filter function instead. Unlike update,
filter performs comprehensive input validation.
References
Version History
Introduced in R2021b