simBySolution
Simulate approximate solution of diagonal-drift GBM
processes
Description
[
adds optional name-value pair arguments. Paths,Times,Z] = simBySolution(___,Name,Value)
You can perform quasi-Monte Carlo simulations using the name-value arguments for
MonteCarloMethod, QuasiSequence and
BrownianMotionMethod. For more information, see Quasi-Monte Carlo Simulation.
Examples
Use GBM simulation functions. Separable GBM models have two specific simulation functions:
An overloaded Euler simulation function (
simulate), designed for optimal performance.A
simBySolutionfunction that provides an approximate solution of the underlying stochastic differential equation, designed for accuracy.
Load the Data_GlobalIdx2 data set and specify the SDE model as in Represent Market Models Using SDE Models, and the GBM model as in Represent Market Models Using SDELD, CEV, and GBM Objects.
load Data_GlobalIdx2 prices = [Dataset.TSX Dataset.CAC Dataset.DAX ... Dataset.NIK Dataset.FTSE Dataset.SP]; returns = tick2ret(prices); nVariables = size(returns,2); expReturn = mean(returns); sigma = std(returns); correlation = corrcoef(returns); t = 0; X = 100; X = X(ones(nVariables,1)); F = @(t,X) diag(expReturn)* X; G = @(t,X) diag(X) * diag(sigma); SDE = sde(F, G, 'Correlation', ... correlation, 'StartState', X); GBM = gbm(diag(expReturn),diag(sigma), 'Correlation', ... correlation, 'StartState', X);
To illustrate the performance benefit of the overloaded Euler approximation function (simulate), increase the number of trials to 10000.
nPeriods = 249; % # of simulated observations dt = 1; % time increment = 1 day rng(142857,'twister') [X,T] = simulate(GBM, nPeriods, 'DeltaTime', dt, ... 'nTrials', 10000); whos X
Name Size Bytes Class Attributes X 250x6x10000 120000000 double
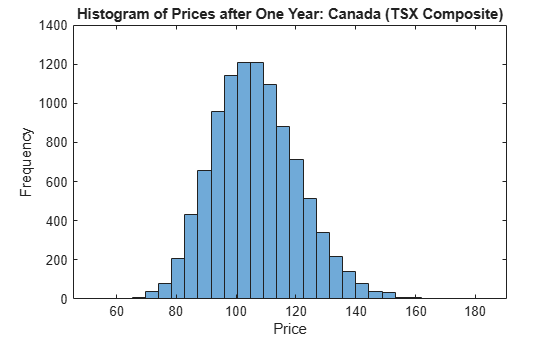
Using this sample size, examine the terminal distribution of Canada's TSX Composite to verify qualitatively the lognormal character of the data.
histogram(squeeze(X(end,1,:)), 30), xlabel('Price'), ylabel('Frequency') title('Histogram of Prices after One Year: Canada (TSX Composite)')
Simulate 10 trials of the solution and plot the first trial:
rng('default') [S,T] = simulate(SDE, nPeriods, 'DeltaTime', dt, 'nTrials', 10); rng('default') [X,T] = simBySolution(GBM, nPeriods,... 'DeltaTime', dt, 'nTrials', 10); subplot(2,1,1) plot(T, S(:,:,1)), xlabel('Trading Day'),ylabel('Price') title('1st Path of Multi-Dim Market Model:Euler Approximation') subplot(2,1,2) plot(T, X(:,:,1)), xlabel('Trading Day'),ylabel('Price') title('1st Path of Multi-Dim Market Model:Analytic Solution')
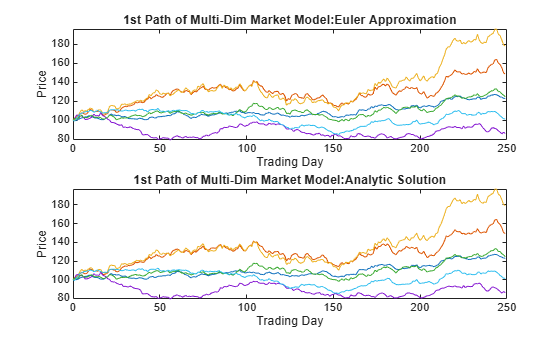
In this example, all parameters are constants, and simBySolution does indeed sample the exact solution. The details of a single index for any given trial show that the price paths of the Euler approximation and the exact solution are close, but not identical.
The following plot illustrates the difference between the two functions:
subplot(1,1,1) plot(T, S(:,1,1) - X(:,1,1), 'blue'), grid('on') xlabel('Trading Day'), ylabel('Price Difference') title('Euler Approx Minus Exact Solution:Canada(TSX Composite)')
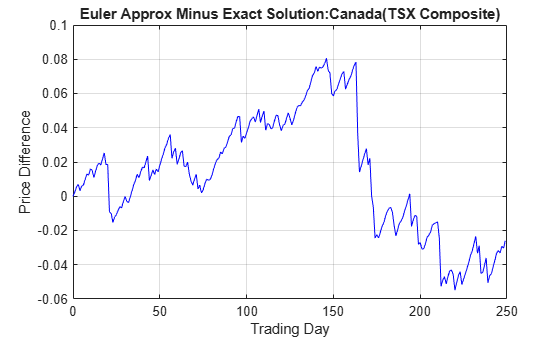
The simByEuler Euler approximation literally evaluates the stochastic differential equation directly from the equation of motion, for some suitable value of the dt time increment. This simple approximation suffers from discretization error. This error can be attributed to the discrepancy between the choice of the dt time increment and what in theory is a continuous-time parameter.
The discrete-time approximation improves as DeltaTime approaches zero. The Euler function is often the least accurate and most general method available. All models shipped in the simulation suite have the simByEuler function.
In contrast, the simBySolution function provides a more accurate description of the underlying model. This function simulates the price paths by an approximation of the closed-form solution of separable models. Specifically, it applies a Euler approach to a transformed process, which in general is not the exact solution to this GBM model. This is because the probability distributions of the simulated and true state vectors are identical only for piecewise constant parameters.
When all model parameters are piecewise constant over each observation period, the simulated process is exact for the observation times at which the state vector is sampled. Since all parameters are constants in this example, simBySolution does indeed sample the exact solution.
For an example of how to use simBySolution to optimize the accuracy of solutions, see Optimizing Accuracy: About Solution Precision and Error.
This example shows how to use simBySolution with a GBM model to perform a quasi-Monte Carlo simulation. Quasi-Monte Carlo simulation is a Monte Carlo simulation that uses quasi-random sequences instead pseudo random numbers.
Load the Data_GlobalIdx2 data set and specify the GBM model as in Represent Market Models Using SDELD, CEV, and GBM Objects.
load Data_GlobalIdx2 prices = [Dataset.TSX Dataset.CAC Dataset.DAX ... Dataset.NIK Dataset.FTSE Dataset.SP]; returns = tick2ret(prices); nVariables = size(returns,2); expReturn = mean(returns); sigma = std(returns); correlation = corrcoef(returns); X = 100; X = X(ones(nVariables,1)); GBM = gbm(diag(expReturn),diag(sigma), 'Correlation', ... correlation, 'StartState', X);
Perform a quasi-Monte Carlo simulation by using simBySolution with the optional name-value arguments for 'MonteCarloMethod','QuasiSequence', and 'BrownianMotionMethod'.
[paths,time,z] = simBySolution(GBM, 10,'ntrials',4096,'MonteCarloMethod','quasi','QuasiSequence','sobol','BrownianMotionMethod','brownian-bridge');
This example shows the workflow to compute the price of a European call option using Monte Carlo simulation with a gbm object.
Set up the parameters for the Geometric Brownian Motion (GBM) model and the European call option.
% Parameters for the GBM model and option S0 = 80; % Initial stock price K = 40; % Strike price T = 1; % Time to maturity in years r = 0.05; % Risk-free interest rate sigma = 0.20; % Volatility nTrials = 10000; % Number of Monte Carlo trials nPeriods = 1; % Number of periods (for one year, this can be set to 1)
Create a gbm object.
% Create GBM object gbmobj = gbm(r,sigma,'StartState',S0);
Use simBySolution to simulate the end-of-year stock prices using the GBM model (gbm) over nTrials trials.
% Simulate stock prices at maturity FuturePrices = simBySolution(gbmobj,nPeriods,'nTrials',nTrials,'DeltaTime',T);
Calculate the payoff for the European call option based on the simulated prices.
% Calculate payoffs for the call option
Payoffs = max(FuturePrices(:, end) - K, 0);Discount the payoff back to the present value and then average the payoff value to estimate the option price.
% Discount payoff back to present value and then average payoff value
DiscountedPayoffs = exp(-r * T) * Payoffs;
OptionPrice = mean(DiscountedPayoffs);Display the estimated price for the call option.
% Display results disp(['Estimated Europen option price using Monte Carlo simulation: ', num2str(OptionPrice)]);
Estimated Europen option price using Monte Carlo simulation: 40.0231
Input Arguments
Name-Value Arguments
Output Arguments
More About
There are inheritance relationships among the SDE classes.
The following figure illustrates the inheritance relationships.

For more information, see SDE Class Hierarchy.
Algorithms
The simBySolution function simulates NTRIALS
sample paths of NVARS correlated state variables, driven by
NBROWNS Brownian motion sources of risk over
NPERIODS consecutive observation periods, approximating
continuous-time GBM short-rate models by an approximation of the closed-form
solution.
Consider a separable, vector-valued GBM model of the form:
where:
Xt is an
NVARS-by-1state vector of process variables.μ is an
NVARS-by-NVARSgeneralized expected instantaneous rate of return matrix.V is an
NVARS-by-NBROWNSinstantaneous volatility rate matrix.dWt is an
NBROWNS-by-1Brownian motion vector.
The simBySolution function simulates the state vector
Xt using an approximation of the
closed-form solution of diagonal-drift models.
When evaluating the expressions, simBySolution assumes that all
model parameters are piecewise-constant over each simulation period.
In general, this is not the exact solution to the models, because the probability distributions of the simulated and true state vectors are identical only for piecewise-constant parameters.
When parameters are piecewise-constant over each observation period, the simulated process is exact for the observation times at which Xt is sampled.
Gaussian diffusion models, such as hwv, allow negative states. By default, simBySolution
does nothing to prevent negative states, nor does it guarantee that the model be
strictly mean-reverting. Thus, the model may exhibit erratic or explosive growth.
References
[1] Aït-Sahalia, Yacine. “Testing Continuous-Time Models of the Spot Interest Rate.” Review of Financial Studies, Vol. 9, No. 2 ( Apr. 1996): 385–426.
[2] Aït-Sahalia, Yacine. “Transition Densities for Interest Rate and Other Nonlinear Diffusions.” The Journal of Finance, Vol. 54, No. 4 (Aug. 1999): 1361–95.
[3] Glasserman, Paul. Monte Carlo Methods in Financial Engineering, New York: Springer-Verlag, 2004.
[4] Hull, John C. Options, Futures and Other Derivatives, 7th ed, Prentice Hall, 2009.
[5] Johnson, Norman Lloyd, Samuel Kotz, and Narayanaswamy Balakrishnan. Continuous Univariate Distributions, 2nd ed. Wiley Series in Probability and Mathematical Statistics. New York: Wiley, 1995.
[6] Shreve, Steven E. Stochastic Calculus for Finance, New York: Springer-Verlag, 2004.
Version History
Introduced in R2008aSee Also
simByEuler | simulate | gbm | simBySolution
Topics
- Simulating Equity Prices
- Simulating Interest Rates
- Stratified Sampling
- Price American Basket Options Using Standard Monte Carlo and Quasi-Monte Carlo Simulation
- Base SDE Models
- Drift and Diffusion Models
- Linear Drift Models
- Parametric Models
- SDEs
- SDE Models
- SDE Class Hierarchy
- Quasi-Monte Carlo Simulation
- Performance Considerations