Décider quand utiliser parfor
Boucles parfor dans MATLAB
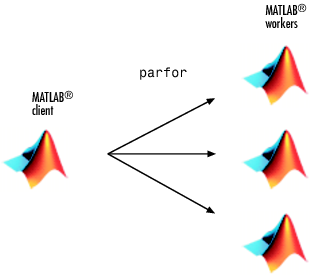
Une boucle parfor dans MATLAB® exécute une série d'instructions dans le corps de la boucle en parallèle. Le client MATLAB émet la commande parfor et se coordonne avec les workers MATLAB pour exécuter les itérations de boucle en parallèle sur les workers dans un pool parallèle. Le client envoie les données nécessaires sur lesquelles parfor opère aux workers, où la plupart des calculs sont exécutés. Les résultats sont renvoyés au client et assemblés.
Une boucle parfor peut fournir des performances nettement meilleures que sa boucle analogue for, car plusieurs workers MATLAB peuvent calculer simultanément sur la même boucle.
Chaque exécution du corps d'une boucle parfor est une itération. Les MATLAB évaluent les itérations sans ordre particulier et indépendamment les uns des autres. Étant donné que chaque itération est indépendante, il n’y a aucune garantie que les itérations soient synchronisées de quelque façon que ce soit, et cela n’est d’ailleurs pas nécessaire. Si le nombre de workers est égal au nombre d'itérations de la boucle, chaque worker effectue une itération de la boucle. S'il y a plus d'itérations que de workers, certains workers effectuent plus d'une itération de boucle ; dans ce cas, un worker peut recevoir plusieurs itérations à la fois pour réduire le temps de communication.
Déterminer quand utiliser parfor
Une boucle parfor peut être utile si vous avez une boucle for lente. Considérez parfor si vous avez :
Certaines itérations de boucle prennent beaucoup de temps à s'exécuter. Dans ce cas, les workers peuvent exécuter les longues itérations simultanément. Assurez-vous que le nombre d'itérations dépasse le nombre de workers. Sinon, vous n'utiliserez pas tous les workers disponibles.
De nombreuses itérations de boucle d'un calcul simple, comme une simulation de Monte Carlo ou un balayage de paramètres,
parfordivise les itérations de boucle en groupes afin que chaque worker exécute une partie du nombre total d'itérations.Plusieurs GPU et vos calculs utilisent des fonctions compatibles GPU. Pour plus d'informations sur l'utilisation de plusieurs GPU dans une boucle
parfor, voir Run MATLAB Functions on Multiple GPUs .
Une boucle parfor peut ne pas être utile si vous avez :
Code qui a vectorisé les boucles
for. En règle générale, si vous souhaitez accélérer l'exécution du code, essayez d'abord de le vectoriser. Pour plus de détails sur la façon de procéder, voir Vectorization . La vectorisation du code vous permet de bénéficier du parallélisme intégré fourni par la nature multithread de nombreuses bibliothèques MATLAB sous-jacentes. Cependant, si vous avez du code vectorisé et que vous n'avez accès qu'aux workers locaux, les bouclesparforpeuvent s'exécuter plus lentement que les bouclesfor. Ne dévectorisez pas le code pour permettreparfor; en général, cette solution ne fonctionne pas bien.Itérations en boucle qui prennent peu de temps à exécuter. Dans ce cas, la surcharge parallèle domine votre calcul.
Itérations en boucle qui utilisent toutes le même GPU. Les GPU contiennent de nombreux microprocesseurs qui peuvent effectuer des calculs en parallèle et essayer de paralléliser davantage les calculs GPU à l'aide d'une boucle
parforest peu susceptible d'accélérer votre code.
Vous ne pouvez pas utiliser une boucle parfor lorsqu'une itération de votre boucle dépend des résultats d'autres itérations. Chaque itération doit être indépendante de toutes les autres. Pour obtenir de l'aide sur la gestion des boucles indépendantes, voir Ensure That parfor-Loop Iterations Are Independent . L'exception à cette règle est d'accumuler des valeurs dans une boucle en utilisant Reduction Variables .
Lorsque vous décidez quand utiliser parfor, tenez compte de la surcharge parallèle. Les frais généraux parallèles incluent le temps requis pour la communication, la coordination et le transfert de données (envoi et réception de données) du client aux workers et vice versa. Si les évaluations d’itération sont rapides, cette surcharge pourrait représenter une partie importante du temps total. Considérez deux types différents d’itérations de boucle :
for-boucles avec une tâche exigeante en termes de calcul. Ces boucles sont généralement de bons candidats pour la conversion en boucleparfor, car le temps nécessaire au calcul domine le temps requis pour le transfert de données.for-boucles avec une task de calcul simple. Ces boucles ne bénéficient généralement pas d'une conversion en boucleparfor, car le temps nécessaire au transfert de données est important par rapport au temps nécessaire au calcul.
Exemple de parfor avec une faible surcharge parallèle
Dans cet exemple, vous démarrez avec une task exigeante en termes de calcul à l'intérieur d'une boucle for. Les boucles for sont lentes et vous accélérez le calcul en utilisant des boucles parfor à la place. parfor divise l'exécution des itérations de boucle for sur les workers d'un pool parallèle.
Cet exemple calcule le rayon spectral d'une matrice et convertit une boucle for en une boucle parfor. Découvrez comment mesurer l’accélération résultante et la quantité de données transférées vers et depuis les workers du pool parallèle.
Dans l'éditeur MATLAB, entrez la boucle
forsuivante. Ajoutezticettocpour mesurer le temps de calcul.tic n = 200; A = 500; a = zeros(1,n); for i = 1:n a(i) = max(abs(eig(rand(A)))); end toc
Exécutez le script et notez le temps écoulé.
Elapsed time is 31.935373 seconds.
Dans le script, remplacez la boucle
forpar une boucleparfor. AjoutezticBytesettocBytespour mesurer la quantité de données transférées vers et depuis les workers du pool parallèle.tic ticBytes(gcp); n = 200; A = 500; a = zeros(1,n); parfor i = 1:n a(i) = max(abs(eig(rand(A)))); end tocBytes(gcp) toc
Exécutez le nouveau script sur quatre workers, puis exécutez-le à nouveau. Notez que la première exécution est plus lente que la deuxième, car le pool parallèle prend un certain temps pour démarrer et rendre le code disponible pour les workers. Notez le transfert de données et le temps écoulé pour la deuxième exécution.
Par défaut, MATLAB ouvre automatiquement un pool parallèle de workers sur votre machine locale.
L'exécution deStarting parallel pool (parpool) using the 'Processes' profile ... connected to 4 workers. ... BytesSentToWorkers BytesReceivedFromWorkers __________________ ________________________ 1 15340 7024 2 13328 5712 3 13328 5704 4 13328 5728 Total 55324 24168 Elapsed time is 10.760068 seconds.parforsur quatre workers est environ trois fois plus rapide que le calcul de boucleforcorrespondant. L'accélération est inférieure à l'accélération idéale d'un facteur quatre sur quatre workers. Cela est dû à la surcharge parallèle, y compris le temps nécessaire pour transférer les données du client vers les workers et vice versa. Utilisez les résultatsticBytesettocBytespour examiner la quantité de données transférées. Supposons que le temps requis pour le transfert de données soit proportionnel à la taille des données. Cette approximation vous permet d'obtenir une indication du temps nécessaire au transfert de données et de comparer votre surcharge parallèle avec d'autres itérations de boucleparfor. Dans cet exemple, le transfert de données et la surcharge parallèle sont faibles par rapport à l'exemple suivant.
L'exemple actuel présente une faible surcharge parallèle et bénéficie de la conversion en boucle parfor. Comparez cet exemple avec l'itération de boucle simple dans l'exemple suivant, voir Exemple de parfor avec une surcharge parallèle élevée .
Pour un autre exemple d'une boucle parfor avec des tasks exigeantes en termes de calcul, voir Boucles imbriquées parfor et for et autres exigences parfor
Exemple de parfor avec une surcharge parallèle élevée
Dans cet exemple, vous écrivez une boucle pour créer une onde sinusoïdale simple. Remplacer la boucle for par une boucle parfor n'accélère pas votre calcul. Cette boucle n'a pas beaucoup d'itérations, elle ne prend pas longtemps à s'exécuter et vous ne remarquez pas d'augmentation de la vitesse d'exécution. Cet exemple présente une surcharge parallèle élevée et ne bénéficie pas de la conversion en boucle parfor.
Écrivez une boucle pour créer une onde sinusoïdale. Utilisez
ticettocpour mesurer le temps écoulé.tic n = 1024; A = zeros(n); for i = 1:n A(i,:) = (1:n) .* sin(i*2*pi/1024); end toc
Elapsed time is 0.012501 seconds.
Remplacez la boucle
forpar une boucleparfor. AjoutezticBytesettocBytespour mesurer la quantité de données transférées vers et depuis les workers du pool parallèle.tic ticBytes(gcp); n = 1024; A = zeros(n); parfor (i = 1:n) A(i,:) = (1:n) .* sin(i*2*pi/1024); end tocBytes(gcp) toc
Exécutez le script sur quatre workers et exécutez à nouveau le code. Notez que la première exécution est plus lente que la deuxième, car le pool parallèle prend un certain temps pour démarrer et rendre le code disponible pour les workers. Notez le transfert de données et le temps écoulé pour la deuxième exécution.
Notez que le temps écoulé est beaucoup plus petit pour la boucle sérieBytesSentToWorkers BytesReceivedFromWorkers __________________ ________________________ 1 13176 2.0615e+06 2 15188 2.0874e+06 3 13176 2.4056e+06 4 13176 1.8567e+06 Total 54716 8.4112e+06 Elapsed time is 0.743855 seconds.forque pour la boucleparforsur quatre workers. Dans ce cas, vous ne bénéficiez d'aucun avantage à transformer votre boucleforen boucleparfor. La raison est que le transfert de données est beaucoup plus important que dans l'exemple précédent, voir Exemple de parfor avec une faible surcharge parallèle . Dans l’exemple actuel, la surcharge parallèle domine le temps de calcul. Par conséquent, l'itération de l'onde sinusoïdale ne bénéficie pas de la conversion en boucleparfor.
Cet exemple illustre pourquoi les calculs à forte charge parallèle ne bénéficient pas de la conversion en boucle parfor. Pour en savoir plus sur l'accélération de votre code, consultez Convertir les boucles for en boucles parfor