rlNeuralNetworkEnvironment
Description
Use an rlNeuralNetworkEnvironment object to create a
reinforcement learning environment that computes state transitions using deep neural
networks.
Using an rlNeuralNetworkEnvironment object you can:
Create an internal environment model for a model-based policy optimization (MBPO) agent.
Create an environment for training other types of reinforcement learning agents. You can identify the state-transition network using experimental or simulated data.
Such environments can compute environment rewards and termination conditions using deep neural networks or custom functions.
Creation
Syntax
Description
env = rlNeuralNetworkEnvironment(ObservationInfo,ActionInfo,transitionFcn,rewardFcn,isDoneFcn)ObservationInfo and ActionInfo,
respectively. This syntax sets the TransitionFcn,
RewardFcn, and IsDoneFcn properties.
Input Arguments
Properties
Object Functions
rlMBPOAgent | Model-based policy optimization (MBPO) reinforcement learning agent |
Examples
Create an environment object and extract observation and action specifications. Alternatively, you can create specifications using rlNumericSpec and rlFiniteSetSpec. These are going to be the observation and action specification objects for your environment.
env = rlPredefinedEnv("CartPole-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);Get the dimension of the observation and action spaces.
nObs = obsInfo.Dimension(1); nAct = actInfo.Dimension(1);
Create a deterministic transition function based on a deep neural network with two input channels (current observations and actions) and one output channel (predicted next observation).
% Create network layers. statePath = featureInputLayer(nObs, ... Normalization="none",Name="state"); actionPath = featureInputLayer(nAct, ... Normalization="none",Name="action"); commonPath = [concatenationLayer(1,2,Name="concat") fullyConnectedLayer(64,Name="FC1") reluLayer(Name="CriticRelu1") fullyConnectedLayer(64, Name="FC3") reluLayer(Name="CriticCommonRelu2") fullyConnectedLayer(nObs,Name="nextObservation") ]; % Create dlnetwork object and add layers transitionNetwork = dlnetwork(); transitionNetwork = addLayers(transitionNetwork,statePath); transitionNetwork = addLayers(transitionNetwork,actionPath); transitionNetwork = addLayers(transitionNetwork,commonPath); % Connect layers transitionNetwork = connectLayers( ... transitionNetwork,"state","concat/in1"); transitionNetwork = connectLayers( ... transitionNetwork,"action","concat/in2"); % Plot network plot(transitionNetwork)
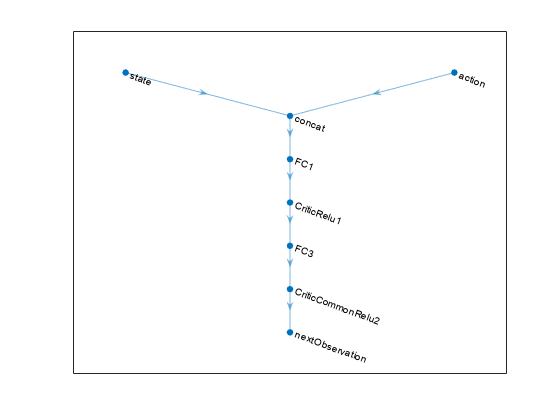
% Initialize dlnetwork object. transitionNetwork = initialize(transitionNetwork); % Create transition function object. transitionFcn = rlContinuousDeterministicTransitionFunction( ... transitionNetwork,obsInfo,actInfo, ... ObservationInputNames="state", ... ActionInputNames="action", ... NextObservationOutputNames="nextObservation");
Create a deterministic reward approximator object with two input channels (current action and next observations) and one output channel (predicted reward value).
% Create network layers. nextStatePath = featureInputLayer( ... nObs,Name="nextState"); commonPath = [concatenationLayer(1,3,Name="concat") fullyConnectedLayer(32,Name="fc") reluLayer(Name="relu1") fullyConnectedLayer(32,Name="fc2")]; meanPath = [reluLayer(Name="rewardMeanRelu") fullyConnectedLayer(1,Name="rewardMean")]; stdPath = [reluLayer(Name="rewardStdRelu") fullyConnectedLayer(1,Name="rewardStdFc") softplusLayer(Name="rewardStd")]; % Assemble dlnetwork object. rewardNetwork = dlnetwork(); rewardNetwork = addLayers(rewardNetwork,statePath); rewardNetwork = addLayers(rewardNetwork,actionPath); rewardNetwork = addLayers(rewardNetwork,nextStatePath); rewardNetwork = addLayers(rewardNetwork,commonPath); rewardNetwork = addLayers(rewardNetwork,meanPath); rewardNetwork = addLayers(rewardNetwork,stdPath); % Connect layers rewardNetwork = connectLayers( ... rewardNetwork,"nextState","concat/in1"); rewardNetwork = connectLayers( ... rewardNetwork,"action","concat/in2"); rewardNetwork = connectLayers( ... rewardNetwork,"state","concat/in3"); rewardNetwork = connectLayers( ... rewardNetwork,"fc2","rewardMeanRelu"); rewardNetwork = connectLayers( ... rewardNetwork,"fc2","rewardStdRelu"); % Plot network plot(rewardNetwork)
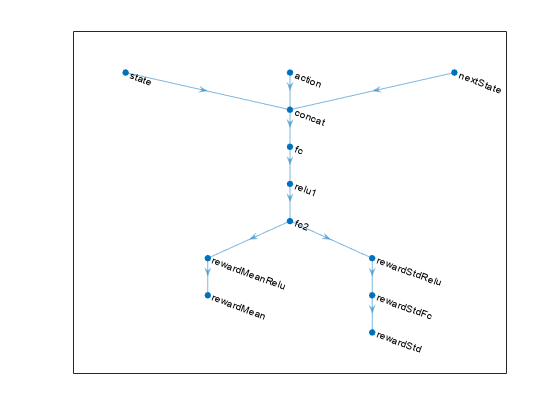
% Initialize dlnetwork object and display the number of parameters
rewardNetwork = initialize(rewardNetwork);
summary(rewardNetwork) Initialized: true
Number of learnables: 1.4k
Inputs:
1 'state' 4 features
2 'action' 1 features
3 'nextState' 4 features
% Create reward function object. rewardFcn = rlContinuousGaussianRewardFunction( ... rewardNetwork,obsInfo,actInfo, ... ObservationInputNames="state", ... ActionInputNames="action", ... NextObservationInputNames="nextState", ... RewardMeanOutputNames="rewardMean", ... RewardStandardDeviationOutputNames="rewardStd");
Create an is-done function approximator object with one input channel (next observations) and one output channel (predicted termination signal).
% Create network layers. isDoneNetwork = [ featureInputLayer(nObs,Name="nextState"); fullyConnectedLayer(64,Name="FC1") reluLayer(Name="CriticRelu1") fullyConnectedLayer(64,Name="FC3") reluLayer(Name="CriticCommonRelu2") fullyConnectedLayer(2,Name="isdone0") softmaxLayer(Name="isdone") ]; % Create dlnetwork object. isDoneNetwork = dlnetwork(isDoneNetwork); % Initialize network and display the number of weights isDoneNetwork = initialize(isDoneNetwork); % Create is-done function approximator object. isDoneFcn = rlIsDoneFunction(isDoneNetwork, ... obsInfo,actInfo, ... NextObservationInputNames="nextState");
Create a neural network environment using the transition, reward, and is-done function approximator objects.
env = rlNeuralNetworkEnvironment( ... obsInfo,actInfo, ... transitionFcn,rewardFcn,isDoneFcn)
env =
rlNeuralNetworkEnvironment with properties:
TransitionFcn: [1×1 rl.function.rlContinuousDeterministicTransitionFunction]
RewardFcn: [1×1 rl.function.rlContinuousGaussianRewardFunction]
IsDoneFcn: [1×1 rl.function.rlIsDoneFunction]
Observation: {[4×1 double]}
TransitionModelNum: 1
To check the environment, you can also call its reset and step functions.
obs0 = reset(env);
obs0{1}ans = 4×1
103 ×
-0.8472
5.1832
8.7759
6.2140
[xn,rn,id]=step(env,{rand(nAct,1)})xn = 1×1 cell array
{4×1 single}
rn = single
410.7173
id = 0
You can use your neural network environment as an internal model for a model based reinforcement learning agent, such as rlMBPOAgent.
Create an environment object and extract observation and action specifications. Alternatively, you can create specifications using rlNumericSpec and rlFiniteSetSpec. These are going to be the observation and action specification objects for your environment.
env = rlPredefinedEnv("CartPole-Continuous");
obsInfo = getObservationInfo(env);
nObs = obsInfo.Dimension(1);
actInfo = getActionInfo(env);
nAct = actInfo.Dimension(1);Create a deterministic transition function approximator based on a deep neural network with two input channels (current observations and actions) and one output channel (predicted next observation).
% Create network layers. statePath = featureInputLayer(nObs, Name="obsInLyr"); actionPath = featureInputLayer(nAct, Name="actInLyr"); commonPath = [ concatenationLayer(1,2,Name="concat") fullyConnectedLayer(64) reluLayer fullyConnectedLayer(64) reluLayer fullyConnectedLayer(nObs,Name="nextObsOutLyr") ]; % Assemble dlnetwork object and connect layers. trnsNet = dlnetwork(); trnsNet = addLayers(trnsNet,statePath); trnsNet = addLayers(trnsNet,actionPath); trnsNet = addLayers(trnsNet,commonPath); trnsNet = connectLayers(trnsNet,"obsInLyr","concat/in1"); trnsNet = connectLayers(trnsNet,"actInLyr","concat/in2"); % Plot network. plot(trnsNet)
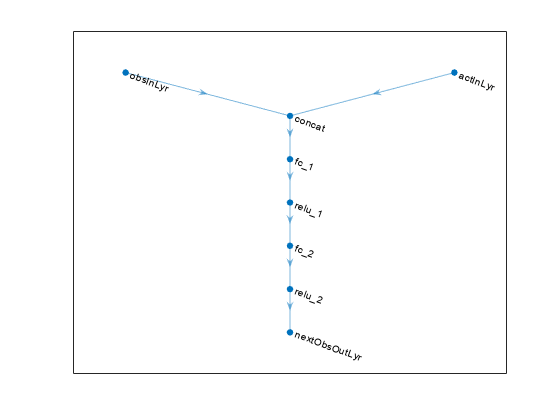
% Initialize network and display the number of weights.
trnsNet = initialize(trnsNet);
summary(trnsNet) Initialized: true
Number of learnables: 4.8k
Inputs:
1 'obsInLyr' 4 features
2 'actInLyr' 1 features
% Create transition function approximator object. transitionFcn = rlContinuousDeterministicTransitionFunction( ... trnsNet,obsInfo,actInfo, ... ObservationInputNames="obsInLyr", ... ActionInputNames="actInLyr", ... NextObservationOutputNames="nextObsOutLyr");
You can define a known reward approximator for your environment using a custom function. Your custom reward approximator must take the observations, actions, and next observations as cell-array inputs and return a scalar reward value. For this example, use the following custom reward function, which computes the reward based on the next observation.
type cartPoleRewardFunction.mfunction reward = cartPoleRewardFunction(obs,action,nextObs)
% Compute reward value based on the next observation.
if iscell(nextObs)
nextObs = nextObs{1};
end
% Distance at which to fail the episode
xThreshold = 2.4;
% Reward each time step the cart-pole is balanced
rewardForNotFalling = 1;
% Penalty when the cart-pole fails to balance
penaltyForFalling = -50;
x = nextObs(1,:);
distReward = 1 - abs(x)/xThreshold;
isDone = cartPoleIsDoneFunction(obs,action,nextObs);
reward = zeros(size(isDone));
reward(logical(isDone)) = penaltyForFalling;
reward(~logical(isDone)) = ...
0.5 * rewardForNotFalling + 0.5 * distReward(~logical(isDone));
end
You can define a known is-done approximator for your environment using a custom function. Your custom is-done function must take the observations, actions, and next observations as cell-array inputs and return a logical termination signal. For this example, use the following custom is-done function, which computes the termination signal based on the next observation.
type cartPoleIsDoneFunction.mfunction isDone = cartPoleIsDoneFunction(obs,action,nextObs)
% Compute termination signal based on next observation.
if iscell(nextObs)
nextObs = nextObs{1};
end
% Angle at which to fail the episode
thetaThresholdRadians = 12 * pi/180;
% Distance at which to fail the episode
xThreshold = 2.4;
x = nextObs(1,:);
theta = nextObs(3,:);
isDone = abs(x) > xThreshold | abs(theta) > thetaThresholdRadians;
end
Create a neural network environment using the transition function object and the custom reward and is-done functions.
env = rlNeuralNetworkEnvironment(obsInfo,actInfo,transitionFcn, ...
@cartPoleRewardFunction,@cartPoleIsDoneFunction)env =
rlNeuralNetworkEnvironment with properties:
TransitionFcn: [1×1 rl.function.rlContinuousDeterministicTransitionFunction]
RewardFcn: @cartPoleRewardFunction
IsDoneFcn: @cartPoleIsDoneFunction
Observation: {[4×1 double]}
TransitionModelNum: 1
To check the environment, you can also call its reset and step functions.
obs0 = reset(env);
obs0{1}ans = 4×1
103 ×
-8.0681
6.9177
8.1879
-9.7732
[xn,rn,id]=step(env,{rand(nAct,1)})xn = 1×1 cell array
{4×1 single}
rn = -50
id = logical
1
You can use your neural network environment as an internal model for a model based reinforcement learning agent, such as rlMBPOAgent.
Version History
Introduced in R2022a