Reinforcement Learning for Control Systems Applications
The behavior of a reinforcement learning policy—that is, how the policy observes the environment and generates actions to complete a task in an optimal manner—is similar to the operation of a controller in a control system. Reinforcement learning can be translated to a control system representation using the following mapping.
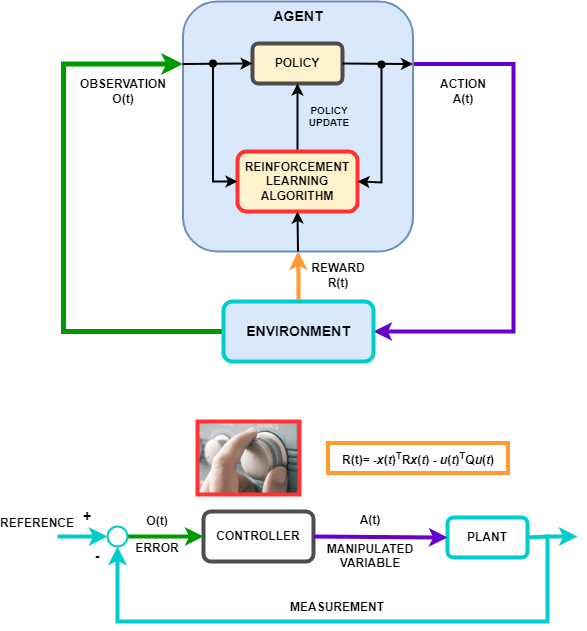
| Reinforcement Learning | Control Systems |
|---|---|
| Policy | Controller |
| Environment | Everything that is not the controller — In the preceding diagram, the environment includes the plant, the reference signal, and the calculation of the error. In general, the environment can also include additional elements, such as:
|
| Observation | Any measurable value from the environment that is visible to the agent — In the preceding diagram, the controller can see the error signal from the environment. You can also create agents that observe, for example, the reference signal, measurement signal, and measurement signal rate of change. |
| Action | Manipulated variables or control actions |
| Reward | Function of the measurement, error signal, or some other performance metric — For
example, you can implement reward functions that minimize the steady-state error while
minimizing control effort. When control specifications such as cost and constraint
functions are available, you can use the generateRewardFunction function to generate a reward function from an MPC object
or model verification blocks. You can then use the generated reward function as a
starting point for reward design, for example, by changing the weights or penalty
functions. |
| Learning Algorithm | Adaptation mechanism of an adaptive controller |
Many control problems encountered in areas such as robotics and automated driving require complex, nonlinear control architectures. Techniques such as gain scheduling, robust control, and nonlinear model predictive control (MPC) can be used for these problems, but often require significant domain expertise from the control engineer. For example, gains and parameters are difficult to tune. The resulting controllers can pose implementation challenges, such as the computational intensity of nonlinear MPC.
You can use deep neural networks, trained using reinforcement learning, to implement such complex controllers. These systems can be self-taught without intervention from an expert control engineer. Also, once the system is trained, you can deploy the reinforcement learning policy in a computationally efficient way.
You can also use reinforcement learning to create an end-to-end controller that generates actions directly from raw data, such as images. This approach is attractive for video-intensive applications, such as automated driving, since you do not have to manually define and select image features.
See Also
Topics
- Compare DDPG Agent to LQR Controller
- Train Default DQN Agent to Balance Discrete Cart-Pole
- Train Default DQN Agent to Swing Up and Balance Discrete Pendulum
- Tune Single PI Controller Gains For Multiple Operating Points Using Reinforcement Learning
- Train Default TD3 Agent to Control Quanser QUBE Pendulum
- What Is Reinforcement Learning?
- Reinforcement Learning Workflow
- Reinforcement Learning Environments
- Create Custom Simulink Environments
- Define Observation and Reward Signals in Custom Environments
- Reinforcement Learning Agents
- Train Reinforcement Learning Agents