crosstab
Cross-tabulation
Syntax
Description
tbl = crosstab(___,Name=Value)
Examples
Create two sample data vectors, containing three and four distinct values, respectively.
x = [1 1 2 3 1]; y = [1 2 5 3 1];
Cross-tabulate x and y.
table = crosstab(x,y)
table = 3×4
2 1 0 0
0 0 0 1
0 0 1 0
The rows in table correspond to the three distinct values in x, and the columns correspond to the four distinct values in y.
Generate two independent vectors, x1 and x2, each containing 50 discrete uniform random numbers in the range 1:3.
rng default; % for reproducibility x1 = unidrnd(3,50,1); x2 = unidrnd(3,50,1);
Cross-tabulate x1 and x2.
[table,chi2,p] = crosstab(x1,x2)
table = 3×3
1 6 7
5 5 2
11 7 6
chi2 = 7.5449
p = 0.1097
The returned p value of 0.1097 indicates that, at the 5% significance level, crosstab fails to reject the null hypothesis that table is independent in each dimension.
Load the sample data, which contains measurements of large model cars during the years 1970-1982.
load carbigCross-tabulate the data of four-cylinder cars (cyl4) based on model year (when) and country of origin (org).
[table,chi2,p,labels] = crosstab(cyl4,when,org);
Use labels to determine the index location in table for the number of four-cylinder cars made in the USA during the late period of the data.
labels
labels=3×3 cell array
{'Other' } {'Early'} {'USA' }
{'Four' } {'Mid' } {'Europe'}
{0×0 double} {'Late' } {'Japan' }
The first column of labels corresponds to the data in cyl4, and indicates that row 2 of table contains data on cars with four cylinders. The second column of labels corresponds to the data in when, and indicates that column 3 of table contains data on cars made during the late period. The third column of labels corresponds to the data in org, and indicates that location 1 of the third dimension of table contains data on cars made in the USA.
Therefore, table(2,3,1) contains the number of four-cylinder cars made in the USA during the late period.
table(2,3,1)
ans = 38
The data contains 38 four-cylinder cars made in the USA during the late period.
Load the grouping variables and display the grouping variables table.
load grouping_variables.mat
datatbldatatbl=4×3 table
x y z
___ ___ ___
NaN NaN 5
5 1 5
1 2 1
5 3 NaN
datatbl is a table that contains values for three grouping variables: x, y, and z. All three variables contain a NaN value.
Generate a cross-tabulation table using the grouping variables in datatbl. Include counts for the NaN entries.
tbl = crosstab(datatbl,IncludeMissingGroups=true)
tbl=36×4 table
x y z Counts
___ ___ _ ______
1 1 1 0
5 1 1 0
NaN 1 1 0
1 2 1 1
5 2 1 0
NaN 2 1 0
1 3 1 0
5 3 1 0
NaN 3 1 0
1 NaN 1 0
5 NaN 1 0
NaN NaN 1 0
1 1 5 0
5 1 5 1
NaN 1 5 0
1 2 5 0
⋮
The cross-tabulation table tbl includes counts for every unique combination of the grouping variable values, including NaN values. Each row of the table corresponds to a unique combination, and the last column contains the count for each combination.
Create a contingency table from data, and visualize the table in a heatmap chart.
Load the hospital data.
load hospitalThe hospital dataset array contains data on 100 hospital patients, including last name, gender, age, weight, smoking status, and systolic and diastolic blood pressure measurements.
Convert the dataset array to a MATLAB® table.
Tbl = dataset2table(hospital);
Determine whether smoking status is independent of gender by creating a 2-by-2 contingency table of smokers and nonsmokers, grouped by gender.
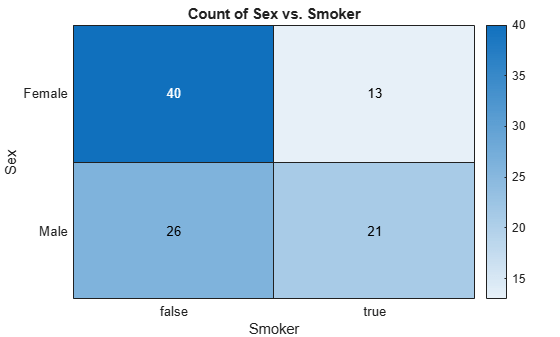
[conttbl,chi2,p,labels] = crosstab(Tbl.Sex,Tbl.Smoker)
conttbl = 2×2
40 13
26 21
chi2 = 4.5083
p = 0.0337
labels = 2×2 cell
{'Female'} {'0'}
{'Male' } {'1'}
The rows of the resulting contingency table conttbl correspond to patient gender, with row 1 containing data for females and row 2 containing data for males. The columns correspond to patient smoking status, with column 1 containing data for nonsmokers and column 2 containing data for smokers. The returned result chi2 = 4.5083 is the value of the chi-squared test statistic for a Pearson's chi-squared test of independence. The -value for the test p = 0.0337 suggests, at a 5% level of significance, rejection of the null hypothesis that gender and smoking status are independent.
Visualize the contingency table in a heatmap. Plot smoking status on the -axis and gender on the -axis.
heatmap(Tbl,'Smoker','Sex')
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
crosstabusesgrp2idxto assign a positive integer to each distinct value.tbl(i,j)is a count of indices wheregrp2idx(x1)isiandgrp2idx(x2)isj. The numerical order ofgrp2idx(x1)andgrp2idx(x2)order rows and columns oftbl, respectively.In this case, the returned value of
tbl(i,j,...,n)is a count of indices wheregrp2idx(x1)isi,grp2idx(x2)isj,grp2idx(x3)isk, and so on.crosstabcomputes the p-value of the chi-square test statistic using a formula that is asymptotically valid for a large sample size. The approximation is less accurate for small samples or samples with uneven marginal distributions. If your sample includes only two variables and each has two levels, you can usefishertestinstead. This function performs Fisher’s exact test, which does not depend on large-sample distribution assumptions.