fitensemble
Fit ensemble of learners for classification and regression
Syntax
Description
fitensemble can boost or bag decision
tree learners or discriminant analysis classifiers. The function can
also train random subspace ensembles of KNN or discriminant analysis
classifiers.
For simpler interfaces that fit classification and regression
ensembles, instead use fitcensemble and fitrensemble, respectively. Also, fitcensemble and fitrensemble provide
options for Bayesian optimization.
Mdl = fitensemble(Tbl,ResponseVarName,Method,NLearn,Learners)NLearn classification or regression
learners (Learners) to all variables in the table Tbl. ResponseVarName is
the name of the response variable in Tbl. Method is
the ensemble-aggregation method.
Mdl = fitensemble(___,Name,Value)Name,Value pair
arguments and any of the previous syntaxes. For example, you can specify
the class order, to implement 10–fold cross-validation, or
the learning rate.
Examples
Estimate the resubstitution loss of a trained, boosting classification ensemble of decision trees.
Load the ionosphere data set.
load ionosphere;Train a decision tree ensemble using AdaBoost, 100 learning cycles, and the entire data set.
ClassTreeEns = fitensemble(X,Y,'AdaBoostM1',100,'Tree');
ClassTreeEns is a trained ClassificationEnsemble ensemble classifier.
Determine the cumulative resubstitution losses (i.e., the cumulative misclassification error of the labels in the training data).
rsLoss = resubLoss(ClassTreeEns,'Mode','Cumulative');
rsLoss is a 100-by-1 vector, where element k contains the resubstitution loss after the first k learning cycles.
Plot the cumulative resubstitution loss over the number of learning cycles.
plot(rsLoss); xlabel('Number of Learning Cycles'); ylabel('Resubstitution Loss');
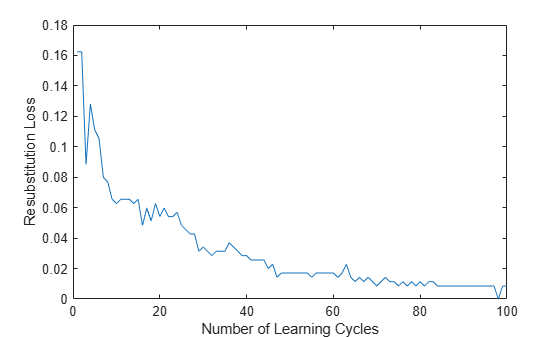
In general, as the number of decision trees in the trained classification ensemble increases, the resubstitution loss decreases.
A decrease in resubstitution loss might indicate that the software trained the ensemble sensibly. However, you cannot infer the predictive power of the ensemble by this decrease. To measure the predictive power of an ensemble, estimate the generalization error by:
Randomly partitioning the data into training and cross-validation sets. Do this by specifying
'holdout',holdoutProportionwhen you train the ensemble usingfitensemble.Passing the trained ensemble to
kfoldLoss, which estimates the generalization error.
Use a trained, boosted regression tree ensemble to predict the fuel economy of a car. Choose the number of cylinders, volume displaced by the cylinders, horsepower, and weight as predictors. Then, train an ensemble using fewer predictors and compare its in-sample predictive accuracy against the first ensemble.
Load the carsmall data set. Store the training data in a table.
load carsmall
Tbl = table(Cylinders,Displacement,Horsepower,Weight,MPG);Specify a regression tree template that uses surrogate splits to improve predictive accuracy in the presence of NaN values.
t = templateTree('Surrogate','On');
Train the regression tree ensemble using LSBoost and 100 learning cycles.
Mdl1 = fitensemble(Tbl,'MPG','LSBoost',100,t);
Mdl1 is a trained RegressionEnsemble regression ensemble. Because MPG is a variable in the MATLAB® Workspace, you can obtain the same result by entering
Mdl1 = fitensemble(Tbl,MPG,'LSBoost',100,t);
Use the trained regression ensemble to predict the fuel economy for a four-cylinder car with a 200-cubic inch displacement, 150 horsepower, and weighing 3000 lbs.
predMPG = predict(Mdl1,[4 200 150 3000])
predMPG = 22.8462
The average fuel economy of a car with these specifications is 21.78 mpg.
Train a new ensemble using all predictors in Tbl except Displacement.
formula = 'MPG ~ Cylinders + Horsepower + Weight'; Mdl2 = fitensemble(Tbl,formula,'LSBoost',100,t);
Compare the resubstitution MSEs between Mdl1 and Mdl2.
mse1 = resubLoss(Mdl1)
mse1 = 6.4721
mse2 = resubLoss(Mdl2)
mse2 = 7.8599
The in-sample MSE for the ensemble that trains on all predictors is lower.
Estimate the generalization error of a trained, boosting classification ensemble of decision trees.
Load the ionosphere data set.
load ionosphere;Train a decision tree ensemble using AdaBoostM1, 100 learning cycles, and half of the data chosen randomly. The software validates the algorithm using the remaining half.
rng(2); % For reproducibility ClassTreeEns = fitensemble(X,Y,'AdaBoostM1',100,'Tree',... 'Holdout',0.5);
ClassTreeEns is a trained ClassificationEnsemble ensemble classifier.
Determine the cumulative generalization error, i.e., the cumulative misclassification error of the labels in the validation data).
genError = kfoldLoss(ClassTreeEns,'Mode','Cumulative');
genError is a 100-by-1 vector, where element k contains the generalization error after the first k learning cycles.
Plot the generalization error over the number of learning cycles.
plot(genError); xlabel('Number of Learning Cycles'); ylabel('Generalization Error');
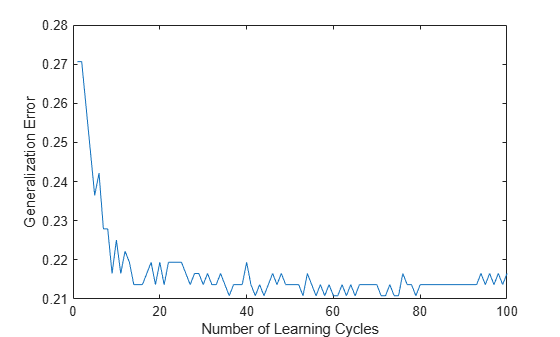
The cumulative generalization error decreases to approximately 7% when 25 weak learners compose the ensemble classifier.
You can control the depth of the trees in an ensemble of decision trees. You can also control the tree depth in an ECOC model containing decision tree binary learners using the MaxNumSplits, MinLeafSize, or MinParentSize name-value pair parameters.
When bagging decision trees,
fitensemblegrows deep decision trees by default. You can grow shallower trees to reduce model complexity or computation time.When boosting decision trees,
fitensemblegrows stumps (a tree with one split) by default. You can grow deeper trees for better accuracy.
Load the carsmall data set. Specify the variables Acceleration, Displacement, Horsepower, and Weight as predictors, and MPG as the response.
load carsmall
X = [Acceleration Displacement Horsepower Weight];
Y = MPG;The default values of the tree depth controllers for boosting regression trees are:
1forMaxNumSplits. This option grows stumps.5forMinLeafSize10forMinParentSize
To search for the optimal number of splits:
Train a set of ensembles. Exponentially increase the maximum number of splits for subsequent ensembles from stump to at most n - 1 splits, where n is the training sample size. Also, decrease the learning rate for each ensemble from 1 to 0.1.
Cross validate the ensembles.
Estimate the cross-validated mean-squared error (MSE) for each ensemble.
Compare the cross-validated MSEs. The ensemble with the lowest one performs the best, and indicates the optimal maximum number of splits, number of trees, and learning rate for the data set.
Grow and cross validate a deep regression tree and a stump. Specify to use surrogate splits because the data contains missing values. These serve as benchmarks.
MdlDeep = fitrtree(X,Y,'CrossVal','on','MergeLeaves','off',... 'MinParentSize',1,'Surrogate','on'); MdlStump = fitrtree(X,Y,'MaxNumSplits',1,'CrossVal','on','Surrogate','on');
Train the boosting ensembles using 150 regression trees. Cross validate the ensemble using 5-fold cross validation. Vary the maximum number of splits using the values in the sequence , where m is such that is no greater than n - 1, where n is the training sample size. For each variant, adjust the learning rate to each value in the set {0.1, 0.25, 0.5, 1};
n = size(X,1); m = floor(log2(n - 1)); lr = [0.1 0.25 0.5 1]; maxNumSplits = 2.^(0:m); numTrees = 150; Mdl = cell(numel(maxNumSplits),numel(lr)); rng(1); % For reproducibility for k = 1:numel(lr); for j = 1:numel(maxNumSplits); t = templateTree('MaxNumSplits',maxNumSplits(j),'Surrogate','on'); Mdl{j,k} = fitensemble(X,Y,'LSBoost',numTrees,t,... 'Type','regression','KFold',5,'LearnRate',lr(k)); end; end;
Compute the cross-validated MSE for each ensemble.
kflAll = @(x)kfoldLoss(x,'Mode','cumulative'); errorCell = cellfun(kflAll,Mdl,'Uniform',false); error = reshape(cell2mat(errorCell),[numTrees numel(maxNumSplits) numel(lr)]); errorDeep = kfoldLoss(MdlDeep); errorStump = kfoldLoss(MdlStump);
Plot how the cross-validated MSE behaves as the number of trees in the ensemble increases for a few of the ensembles, the deep tree, and the stump. Plot the curves with respect to learning rate in the same plot, and plot separate plots for varying tree complexities. Choose a subset of tree complexity levels.
mnsPlot = [1 round(numel(maxNumSplits)/2) numel(maxNumSplits)]; figure; for k = 1:3; subplot(2,2,k); plot(squeeze(error(:,mnsPlot(k),:)),'LineWidth',2); axis tight; hold on; h = gca; plot(h.XLim,[errorDeep errorDeep],'-.b','LineWidth',2); plot(h.XLim,[errorStump errorStump],'-.r','LineWidth',2); plot(h.XLim,min(min(error(:,mnsPlot(k),:))).*[1 1],'--k'); h.YLim = [10 50]; xlabel 'Number of trees'; ylabel 'Cross-validated MSE'; title(sprintf('MaxNumSplits = %0.3g', maxNumSplits(mnsPlot(k)))); hold off; end; hL = legend([cellstr(num2str(lr','Learning Rate = %0.2f'));... 'Deep Tree';'Stump';'Min. MSE']); hL.Position(1) = 0.6;
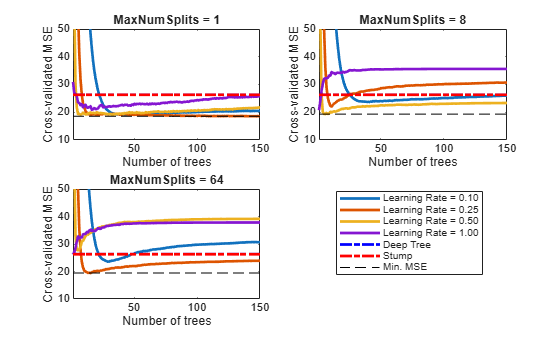
Each curve contains a minimum cross-validated MSE occurring at the optimal number of trees in the ensemble.
Identify the maximum number of splits, number of trees, and learning rate that yields the lowest MSE overall.
[minErr,minErrIdxLin] = min(error(:));
[idxNumTrees,idxMNS,idxLR] = ind2sub(size(error),minErrIdxLin);
fprintf('\nMin. MSE = %0.5f',minErr)Min. MSE = 18.42979
fprintf('\nOptimal Parameter Values:\nNum. Trees = %d',idxNumTrees);Optimal Parameter Values: Num. Trees = 1
fprintf('\nMaxNumSplits = %d\nLearning Rate = %0.2f\n',... maxNumSplits(idxMNS),lr(idxLR))
MaxNumSplits = 4 Learning Rate = 1.00
For a different approach to optimizing this ensemble, see Optimize a Boosted Regression Ensemble.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
NLearncan vary from a few dozen to a few thousand. Usually, an ensemble with good predictive power requires from a few hundred to a few thousand weak learners. However, you do not have to train an ensemble for that many cycles at once. You can start by growing a few dozen learners, inspect the ensemble performance and then, if necessary, train more weak learners usingresumefor classification problems, orresumefor regression problems.Ensemble performance depends on the ensemble setting and the setting of the weak learners. That is, if you specify weak learners with default parameters, then the ensemble can perform poorly. Therefore, like ensemble settings, it is good practice to adjust the parameters of the weak learners using templates, and to choose values that minimize generalization error.
If you specify to resample using
Resample, then it is good practice to resample to entire data set. That is, use the default setting of1forFResample.In classification problems (that is,
Typeis'classification'):If the ensemble-aggregation method (
Method) is'bag'and:The misclassification cost (
Cost) is highly imbalanced, then, for in-bag samples, the software oversamples unique observations from the class that has a large penalty.The class prior probabilities (
Prior) are highly skewed, the software oversamples unique observations from the class that has a large prior probability.
For smaller sample sizes, these combinations can result in a low relative frequency of out-of-bag observations from the class that has a large penalty or prior probability. Consequently, the estimated out-of-bag error is highly variable and it can be difficult to interpret. To avoid large estimated out-of-bag error variances, particularly for small sample sizes, set a more balanced misclassification cost matrix using
Costor a less skewed prior probability vector usingPrior.Because the order of some input and output arguments correspond to the distinct classes in the training data, it is good practice to specify the class order using the
ClassNamesname-value pair argument.To determine the class order quickly, remove all observations from the training data that are unclassified (that is, have a missing label), obtain and display an array of all the distinct classes, and then specify the array for
ClassNames. For example, suppose the response variable (Y) is a cell array of labels. This code specifies the class order in the variableclassNames.Ycat = categorical(Y); classNames = categories(Ycat)
categoricalassigns<undefined>to unclassified observations andcategoriesexcludes<undefined>from its output. Therefore, if you use this code for cell arrays of labels or similar code for categorical arrays, then you do not have to remove observations with missing labels to obtain a list of the distinct classes.To specify that the class order from lowest-represented label to most-represented, then quickly determine the class order (as in the previous bullet), but arrange the classes in the list by frequency before passing the list to
ClassNames. Following from the previous example, this code specifies the class order from lowest- to most-represented inclassNamesLH.Ycat = categorical(Y); classNames = categories(Ycat); freq = countcats(Ycat); [~,idx] = sort(freq); classNamesLH = classNames(idx);
Algorithms
For details of ensemble-aggregation algorithms, see Ensemble Algorithms.
If you specify
Methodto be a boosting algorithm andLearnersto be decision trees, then the software grows stumps by default. A decision stump is one root node connected to two terminal, leaf nodes. You can adjust tree depth by specifying theMaxNumSplits,MinLeafSize, andMinParentSizename-value pair arguments usingtemplateTree.fitensemblegenerates in-bag samples by oversampling classes with large misclassification costs and undersampling classes with small misclassification costs. Consequently, out-of-bag samples have fewer observations from classes with large misclassification costs and more observations from classes with small misclassification costs. If you train a classification ensemble using a small data set and a highly skewed cost matrix, then the number of out-of-bag observations per class can be low. Therefore, the estimated out-of-bag error can have a large variance and can be difficult to interpret. The same phenomenon can occur for classes with large prior probabilities.For the RUSBoost ensemble-aggregation method (
Method), the name-value pair argumentRatioToSmallestspecifies the sampling proportion for each class with respect to the lowest-represented class. For example, suppose that there are two classes in the training data: A and B. A have 100 observations and B have 10 observations. Also, suppose that the lowest-represented class hasmobservations in the training data.If you set
'RatioToSmallest',2, thens*m2*10=20. Consequently,fitensembletrains every learner using 20 observations from class A and 20 observations from class B. If you set'RatioToSmallest',[2 2], then you obtain the same result.If you set
'RatioToSmallest',[2,1], thens1*m2*10=20ands2*m1*10=10. Consequently,fitensembletrains every learner using 20 observations from class A and 10 observations from class B.
For ensembles of decision trees, and for dual-core systems and above,
fitensembleparallelizes training using Intel® Threading Building Blocks (TBB). For details on Intel TBB, see https://www.intel.com/content/www/us/en/developer/tools/oneapi/onetbb.html.
References
[1] Breiman, L. “Bagging Predictors.” Machine Learning. Vol. 26, pp. 123–140, 1996.
[2] Breiman, L. “Random Forests.” Machine Learning. Vol. 45, pp. 5–32, 2001.
[3] Freund, Y. “A more robust boosting algorithm.” arXiv:0905.2138v1, 2009.
[4] Freund, Y. and R. E. Schapire. “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting.” J. of Computer and System Sciences, Vol. 55, pp. 119–139, 1997.
[5] Friedman, J. “Greedy function approximation: A gradient boosting machine.” Annals of Statistics, Vol. 29, No. 5, pp. 1189–1232, 2001.
[6] Friedman, J., T. Hastie, and R. Tibshirani. “Additive logistic regression: A statistical view of boosting.” Annals of Statistics, Vol. 28, No. 2, pp. 337–407, 2000.
[7] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning section edition, Springer, New York, 2008.
[8] Ho, T. K. “The random subspace method for constructing decision forests.” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 20, No. 8, pp. 832–844, 1998.
[9] Schapire, R. E., Y. Freund, P. Bartlett, and W.S. Lee. “Boosting the margin: A new explanation for the effectiveness of voting methods.” Annals of Statistics, Vol. 26, No. 5, pp. 1651–1686, 1998.
[10] Seiffert, C., T. Khoshgoftaar, J. Hulse, and A. Napolitano. “RUSBoost: Improving classification performance when training data is skewed.” 19th International Conference on Pattern Recognition, pp. 1–4, 2008.
[11] Warmuth, M., J. Liao, and G. Ratsch. “Totally corrective boosting algorithms that maximize the margin.” Proc. 23rd Int’l. Conf. on Machine Learning, ACM, New York, pp. 1001–1008, 2006.
Extended Capabilities
Version History
Introduced in R2011a