incrementalClassificationECOC
Multiclass classification model using binary learners for incremental learning
Since R2022a
Description
The incrementalClassificationECOC function creates an
incrementalClassificationECOC model object, which represents a multiclass error-correcting output codes (ECOC)
classification model that uses binary learners for incremental learning.
Unlike other Statistics and Machine Learning Toolbox™ model objects, incrementalClassificationECOC can be called directly. Also,
you can specify learning options, such as performance metrics configurations and prior class
probabilities, before fitting the model to data. After you create an
incrementalClassificationECOC object, it is prepared for incremental learning.
incrementalClassificationECOC is best suited for incremental learning. For a traditional
approach to training a multiclass classification model (such as creating a model by fitting it
to data, performing cross-validation, tuning hyperparameters, and so on), see fitcecoc.
Creation
You can create an incrementalClassificationECOC model object in several ways:
Call the function directly — Configure incremental learning options, or specify learner-specific options, by calling
incrementalClassificationECOCdirectly. This approach is best when you do not have data yet or you want to start incremental learning immediately. You must specify the maximum number of classes or all class names expected in the response data during incremental learning.Convert a traditionally trained model — To initialize a multiclass ECOC classification model for incremental learning using the model parameters of a trained model object (
ClassificationECOCorCompactClassificationECOC), you can convert the traditionally trained model to anincrementalClassificationECOCmodel object by passing it to theincrementalLearnerfunction.Call an incremental learning function —
fit,updateMetrics, andupdateMetricsAndFitaccept a configuredincrementalClassificationECOCmodel object and data as input, and return anincrementalClassificationECOCmodel object updated with information learned from the input model and data.
Syntax
Description
Mdl = incrementalClassificationECOC(MaxNumClasses=maxNumClasses)Mdl, where MaxNumClasses is the maximum number
of classes expected in the response data during incremental learning. Properties of a
default model contain placeholders for unknown model parameters. You must train a default
model before you can track its performance or generate predictions from it.
Mdl = incrementalClassificationECOC(ClassNames=classNames)ClassNames expected in the response data
during incremental learning, and sets the ClassNames property.
Mdl = incrementalClassificationECOC(___,Name=Value)incrementalClassificationECOC(MaxNumClasses=5,Coding="onevsone",MetricsWarmupPeriod=100)
sets the maximum number of classes expected in the response data to 5,
specifies to use a one-versus-one coding design, and sets the metrics warm-up period to
100.
Input Arguments
Name-Value Arguments
Properties
Object Functions
fit | Train ECOC classification model for incremental learning |
updateMetricsAndFit | Update performance metrics in ECOC incremental learning classification model given new data and train model |
updateMetrics | Update performance metrics in ECOC incremental learning classification model given new data |
loss | Loss of ECOC incremental learning classification model on batch of data |
predict | Predict responses for new observations from ECOC incremental learning classification model |
perObservationLoss | Per observation classification error of model for incremental learning |
reset | Reset incremental classification model |
Examples
To create an ECOC classification model for incremental learning, you must specify the maximum number of classes that you expect the model to process (MaxNumClasses name-value argument). As you fit the model to incoming batches of data by using an incremental fitting function, the model collects new classes in its ClassNames property. If the specified maximum number of classes is inaccurate, one of the following occurs:
Before an incremental fitting function processes the expected maximum number of classes, the model is cold. Consequently, the
updateMetricsandupdateMetricsAndFitfunctions do not measure performance metrics.If the number of classes exceeds the maximum expected, the incremental fitting function issues an error.
This example shows how to create an ECOC model for incremental learning when the only information you specify is the expected maximum number of classes in the data. Also, the example illustrates the consequences when incremental fitting functions process all expected classes early and late in the sample.
For this example, consider training a device to predict whether a subject is sitting, standing, walking, running, or dancing based on biometric data measured on the subject. Therefore, the device has a maximum of 5 classes from which to choose.
Process Expected Maximum Number of Classes Early in Sample
Load the human activity data set. Randomly shuffle the data.
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Create an incremental ECOC model for multiclass learning. Specify a maximum of 5 classes in the data.
MdlEarly = incrementalClassificationECOC(MaxNumClasses=5)
MdlEarly =
incrementalClassificationECOC
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
BinaryLearners: {10×1 cell}
CodingName: 'onevsone'
Decoding: 'lossweighted'
Properties, Methods
MdlEarly is an incrementalClassificationECOC model object. All its properties are read-only. MdlEarly must be fit to data before you can use it to perform any other operations.
Display the coding design matrix.
MdlEarly.CodingMatrix
ans = 5×10
1 1 1 1 0 0 0 0 0 0
-1 0 0 0 1 1 1 0 0 0
0 -1 0 0 -1 0 0 1 1 0
0 0 -1 0 0 -1 0 -1 0 1
0 0 0 -1 0 0 -1 0 -1 -1
Each row of the coding design matrix corresponds to a class, and each column corresponds to a binary learner. For example, the first binary learner is for classes 1 and 2, and the fourth binary learner is for classes 1 and 5, where both learners assume class 1 as a positive class.
Fit the incremental model to the training data by using the updateMetricsAndFit function. Simulate a data stream by processing chunks of 50 observations at a time. At each iteration:
Process 50 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store the first model coefficient of the first binary learner , the cumulative metrics, and the window metrics to see how they evolve during incremental learning.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); mc = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); beta11 = zeros(nchunk+1,1); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; MdlEarly = updateMetricsAndFit(MdlEarly,X(idx,:),Y(idx)); mc{j,:} = MdlEarly.Metrics{"ClassificationError",:}; beta11(j) = MdlEarly.BinaryLearners{1}.Beta(1); end
MdlEarly is an incrementalClassificationECOC model object trained on all the data in the stream. During incremental learning and after the model is warmed up, updateMetricsAndFit checks the performance of the model on the incoming observations, and then fits the model to those observations.
To see how the performance metrics and evolve during training, plot them on separate tiles.
t = tiledlayout(2,1); nexttile plot(beta11) ylabel("\beta_{11}") xlim([0 nchunk]) nexttile plot(mc.Variables) xlim([0 nchunk]) ylabel("Classification Error") xline(MdlEarly.MetricsWarmupPeriod/numObsPerChunk,"--") legend(mc.Properties.VariableNames) xlabel(t,"Iteration")

The plots indicate that updateMetricsAndFit performs the following actions:
Fit during all incremental learning iterations.
Compute the performance metrics after the metrics warm-up period (dashed vertical line) only.
Compute the cumulative metrics during each iteration.
Compute the window metrics after processing 200 observations (4 iterations).
Process Expected Maximum Number of Classes Late in Sample
Rearrange the data set so that only the last 5000 samples contain the observations labeled with class 5.
Move all observations labeled with class 5 to the end of the sample.
idx5 = Y == 5; Xnew = [X(~idx5,:); X(idx5,:)]; Ynew = [Y(~idx5); Y(idx5)]; sum(idx5)
ans = 2653
Shuffle the last 5000 samples.
m = 5000; idx_shuffle = randsample(m,m); Xnew(end-m+1:end,:) = Xnew(end-m+idx_shuffle,:); Ynew(end-m+1:end) = Ynew(end-m+idx_shuffle);
An ECOC model trains a binary learner only when an incoming chunk contains observations for the classes that the binary learner treats as either positive or negative. Therefore, when the labels in incoming data are not well distributed for all expected classes, a good practice is to choose a coding design that does not have zeros in the coding matrix so that the software trains all binary learners for every chunk.
Create a new ECOC model for incremental learning. Specify the onevsall coding design. In this design, one class is positive and the rest are negative for each binary learner.
MdlLate = incrementalClassificationECOC(MaxNumClasses=5,Coding="onevsall")MdlLate =
incrementalClassificationECOC
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
BinaryLearners: {5×1 cell}
CodingName: 'onevsall'
Decoding: 'lossweighted'
Properties, Methods
Display the coding design matrix.
MdlLate.CodingMatrix
ans = 5×5
1 -1 -1 -1 -1
-1 1 -1 -1 -1
-1 -1 1 -1 -1
-1 -1 -1 1 -1
-1 -1 -1 -1 1
Fit the incremental model and plot the results. Store the first model coefficients of the first and fifth binary learners, and .
mcnew = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); beta11new = zeros(nchunk,1); beta51new = zeros(nchunk,1); for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; MdlLate = updateMetricsAndFit(MdlLate,Xnew(idx,:),Ynew(idx)); mcnew{j,:} = MdlLate.Metrics{"ClassificationError",:}; beta11new(j) = MdlLate.BinaryLearners{1}.Beta(1); beta51new(j) = MdlLate.BinaryLearners{5}.Beta(1); end t = tiledlayout(3,1); nexttile plot(beta11new) xline(MdlLate.MetricsWarmupPeriod/numObsPerChunk,"--") xline((n-m)/numObsPerChunk,":") ylabel("\beta_{11}") xlim([0 nchunk]) nexttile plot(beta51new) xline(MdlLate.MetricsWarmupPeriod/numObsPerChunk,"--") xline((n-m)/numObsPerChunk,":") ylabel("\beta_{51}") xlim([0 nchunk]) nexttile plot(mcnew.Variables) xline(MdlLate.MetricsWarmupPeriod/numObsPerChunk,"--") xline((n-m)/numObsPerChunk,":") xlim([0 nchunk]) ylabel("Classification Error") legend(mcnew.Properties.VariableNames,Location="best") xlabel(t,"Iteration")
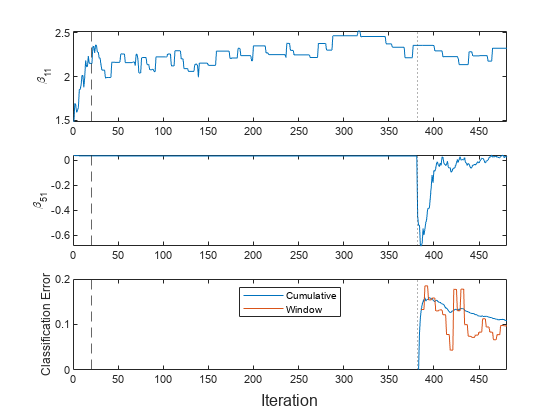
The updateMetricsAndFit function trains the model throughout incremental learning. However, does not change significantly until an incoming chunk contains observations with the fifth class (the dotted vertical line). Also, the function starts tracking performance metrics only after the model is fit to the expected number of classes.
Create an incremental ECOC model when you know all the class names in the data.
Consider training a device to predict whether a subject is sitting, standing, walking, running, or dancing based on biometric data measured on the subject. The class names map 1 through 5 to an activity.
Create an incremental ECOC model for multiclass learning. Specify the class names.
classnames = 1:5; Mdl = incrementalClassificationECOC(ClassNames=classnames)
Mdl =
incrementalClassificationECOC
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
BinaryLearners: {10×1 cell}
CodingName: 'onevsone'
Decoding: 'lossweighted'
Properties, Methods
Mdl is an incrementalClassificationECOC model object. All its properties are read-only.
Mdl must be fit to data before you can use it to perform any other operations.
Load the human activity data set. Randomly shuffle the data.
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Fit the incremental model to the training data by using the updateMetricsAndFit function. Simulate a data stream by processing chunks of 50 observations at a time. At each iteration:
Process 50 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetricsAndFit(Mdl,X(idx,:),Y(idx)); end
In addition to specifying the maximum number of classes, prepare an incremental ECOC learner by specifying a metrics warm-up period and a metrics window size.
Load the human activity data set. Randomly shuffle the data. Orient the observations of the predictor data in columns.
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:)'; Y = actid(idx);
For details on the data set, enter Description at the command line.
Create an incremental ECOC model for multiclass learning. Configure the model as follows:
Set the maximum number of classes to 5.
Specify a metrics warm-up period of 5000 observations.
Specify a metrics window size of 500 observations.
Mdl = incrementalClassificationECOC(MaxNumClasses=5, ...
MetricsWarmupPeriod=5000,MetricsWindowSize=500)Mdl =
incrementalClassificationECOC
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
BinaryLearners: {10×1 cell}
CodingName: 'onevsone'
Decoding: 'lossweighted'
Properties, Methods
Mdl is an incrementalClassificationECOC model object configured for incremental learning. By default, incrementalClassificationECOC uses classification error loss to measure the performance of the model.
Fit the incremental model to the rest of the data by using the updateMetricsAndFit function. At each iteration:
Simulate a data stream by processing a chunk of 50 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations. Specify that the observations are oriented in columns.
Store the first model coefficient of the first binary learner , the cumulative metrics, and the window metrics to see how they evolve during incremental learning.
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); ce = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); beta11 = zeros(nchunk,1); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetricsAndFit(Mdl,X(:,idx),Y(idx),ObservationsIn="columns"); ce{j,:} = Mdl.Metrics{"ClassificationError",:}; beta11(j) = Mdl.BinaryLearners{1}.Beta(1); end
Mdl is an incrementalClassificationECOC model object trained on all the data in the stream. During incremental learning and after the model is warmed up, updateMetricsAndFit checks the performance of the model on the incoming observations, and then fits the model to those observations.
To see how the performance metrics and evolve during training, plot them on separate tiles.
t = tiledlayout(2,1); nexttile plot(beta11) ylabel("\beta_{11}") xlim([0 nchunk]) xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,"--") nexttile plot(ce.Variables) xlim([0 nchunk]) ylabel("Classification Error") xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,"--") legend(ce.Properties.VariableNames) xlabel(t,"Iteration")

The plots indicate that updateMetricsAndFit performs the following actions:
Fit during all incremental learning iterations.
Compute the performance metrics after the metrics warm-up period (dashed vertical line) only.
Compute the cumulative metrics during each iteration.
Compute the window metrics after processing 500 observations (10 iterations).
Train an ECOC model for multiclass classification by using fitcecoc. Then, convert the model to an incremental learner, track its performance, and fit the model to streaming data. Carry over training options from traditional to incremental learning.
Load and Preprocess Data
Load the human activity data set. Randomly shuffle the data.
load humanactivity rng(1) % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
For details on the data set, enter Description at the command line.
Suppose that the data collected when the subject was stationary (Y <= 2) has double the quality than when the subject was moving. Create a weight variable that attributes 2 to observations collected from a stationary subject, and 1 to a moving subject.
W = ones(n,1) + (Y <= 2);
Train ECOC Model
Fit an ECOC model for multiclass classification to a random sample of half the data.
idxtt = randsample([true false],n,true); TTMdl = fitcecoc(X(idxtt,:),Y(idxtt),Weights=W(idxtt))
TTMdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
BinaryLearners: {10×1 cell}
CodingName: 'onevsone'
Properties, Methods
TTMdl is a ClassificationECOC model object representing a traditionally trained ECOC model.
Convert Trained Model
Convert the traditionally trained ECOC model to a model for incremental learning.
IncrementalMdl = incrementalLearner(TTMdl)
IncrementalMdl =
incrementalClassificationECOC
IsWarm: 1
Metrics: [1×2 table]
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
BinaryLearners: {10×1 cell}
CodingName: 'onevsone'
Decoding: 'lossweighted'
Properties, Methods
IncrementalMdl is an incrementalClassificationECOC model object configured for incremental learning.
Separately Track Performance Metrics and Fit Model
Perform incremental learning on the rest of the data by using the updateMetrics and fit functions. Simulate a data stream by processing 50 observations at a time. At each iteration:
Call
updateMetricsto update the cumulative and window classification error of the model given the incoming chunk of observations. Overwrite the previous incremental model to update theMetricsproperty. Note that the function does not fit the model to the chunk of data—the chunk is "new" data for the model. Specify the observation weights.Call
fitto fit the model to the incoming chunk of observations. Overwrite the previous incremental model to update the model parameters. Specify the observation weights.Store the classification error and first model coefficient of the first binary learner .
% Preallocation idxil = ~idxtt; nil = sum(idxil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); ec = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); beta11 = [IncrementalMdl.BinaryLearners{1}.Beta(1); zeros(nchunk+1,1)]; Xil = X(idxil,:); Yil = Y(idxil); Wil = W(idxil); % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetrics(IncrementalMdl,Xil(idx,:),Yil(idx), ... Weights=Wil(idx)); ec{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; IncrementalMdl = fit(IncrementalMdl,Xil(idx,:),Yil(idx),Weights=Wil(idx)); beta11(j+1) = IncrementalMdl.BinaryLearners{1}.Beta(1); end
IncrementalMdl is an incrementalClassificationECOC model object trained on all the data in the stream.
Alternatively, you can use updateMetricsAndFit to update the performance metrics of the model given a new chunk of data, and then fit the model to the data.
Plot a trace plot of the performance metrics and estimated coefficient on separate tiles.
t = tiledlayout(2,1); nexttile plot(ec.Variables) xlim([0 nchunk]) ylabel("Classification Error") legend(ec.Properties.VariableNames) nexttile plot(beta11) ylabel("\beta_{11}") xlim([0 nchunk]) xlabel(t,"Iteration")

The cumulative loss levels quickly and is stable, whereas the window loss jumps throughout the training.
changes abruptly at first, then gradually levels off as fit processes more chunks.
Customize binary learners of an incrementalClassificationECOC model object by specifying the Learners name-value argument.
First, configure binary learner properties by creating an incrementalClassificationLinear object. Set the linear classification model type (Learner) to logistic regression, and specify Standardize as true to standardize the predictor data.
binaryMdl = incrementalClassificationLinear(Learner="logistic", ... Standardize=true)
binaryMdl =
incrementalClassificationLinear
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'logit'
Beta: [0×1 double]
Bias: 0
Learner: 'logistic'
Properties, Methods
Create an incremental ECOC model for multiclass learning. Specify the number of classes in the data as five, and set the binary learner template (Learners) to binaryMdl.
Mdl = incrementalClassificationECOC(MaxNumClasses=5,Learners=binaryMdl)
Mdl =
incrementalClassificationECOC
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
BinaryLearners: {10×1 cell}
CodingName: 'onevsone'
Decoding: 'lossweighted'
Properties, Methods
Display the BinaryLearners property in Mdl.
Mdl.BinaryLearners
ans=10×1 cell array
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
{1×1 incrementalClassificationLinear}
By default, incrementalClassificationECOC uses the one-versus-one coding design, which requires 10 learners for five classes. Therefore, the BinaryLearners property contains 10 binary learners of type incrementalClassificationLinear.
More About
The coding design is a matrix whose elements direct which classes are trained by each binary learner, that is, how the multiclass problem is reduced to a series of binary problems.
Each row of the coding design corresponds to a distinct class, and each column corresponds to a binary learner. In a ternary coding design, for a particular column (or binary learner):
A row containing 1 directs the binary learner to group all observations in the corresponding class into a positive class.
A row containing –1 directs the binary learner to group all observations in the corresponding class into a negative class.
A row containing 0 directs the binary learner to ignore all observations in the corresponding class.
Coding design matrices with large, minimal, pairwise row distances based on the Hamming measure are optimal. For details on the pairwise row distance, see Random Coding Design Matrices and [3].
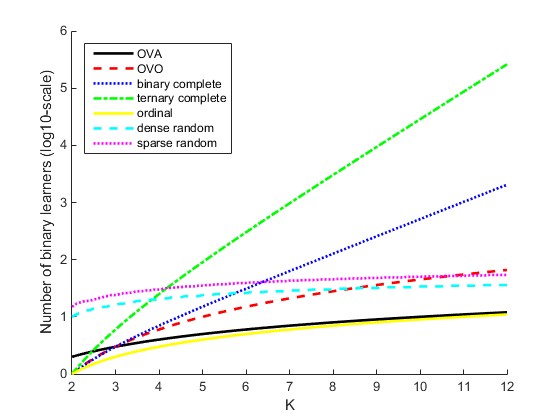
This table describes popular coding designs.
| Coding Design | Description | Number of Learners | Minimal Pairwise Row Distance |
|---|---|---|---|
| one-versus-all (OVA) | For each binary learner, one class is positive and the rest are negative. This design exhausts all combinations of positive class assignments. | K | 2 |
| one-versus-one (OVO) | For each binary learner, one class is positive, one class is negative, and the rest are ignored. This design exhausts all combinations of class pair assignments. | K(K – 1)/2 | 1 |
| binary complete | This design partitions the classes into all binary
combinations, and does not ignore any classes. That is, all class
assignments are | 2K – 1 – 1 | 2K – 2 |
| ternary complete | This design partitions the classes into all ternary
combinations. That is, all class assignments are
| (3K – 2K + 1 + 1)/2 | 3K – 2 |
| ordinal | For the first binary learner, the first class is negative and the rest are positive. For the second binary learner, the first two classes are negative and the rest are positive, and so on. | K – 1 | 1 |
| dense random | For each binary learner, the software randomly assigns classes into positive or negative classes, with at least one of each type. For more details, see Random Coding Design Matrices. | Random, but approximately 10 log2K | Variable |
| sparse random | For each binary learner, the software randomly assigns classes as positive or negative with probability 0.25 for each, and ignores classes with probability 0.5. For more details, see Random Coding Design Matrices. | Random, but approximately 15 log2K | Variable |
This plot compares the number of binary learners for the coding designs with an increasing number of classes (K).