isanomaly
Syntax
Description
tf = isanomaly(forest,Tbl)Tbl using the IsolationForest
object forest and returns the logical array tf,
whose elements are true when an anomaly is detected in the corresponding
row of Tbl. You must use this syntax if you create
forest by passing a table to the iforest
function.
tf = isanomaly(___,Name=Value)ScoreThreshold=0.5
Examples
Create an IsolationForest object for uncontaminated training observations by using the iforest function. Then detect novelties (anomalies in new data) by passing the object and the new data to the object function isanomaly.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year.
load census1994census1994 contains the training data set adultdata and the test data set adulttest.
Train an isolation forest model for adultdata. Assume that adultdata does not contain outliers.
rng("default") % For reproducibility [Mdl,tf,s] = iforest(adultdata);
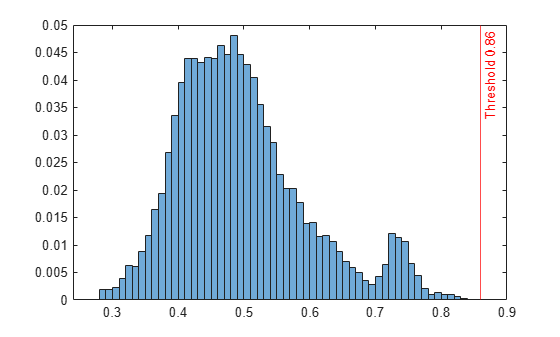
Mdl is an IsolationForest object. iforest also returns the anomaly indicators tf and anomaly scores s for the training data adultdata. If you do not specify the ContaminationFraction name-value argument as a value greater than 0, then iforest treats all training observations as normal observations, meaning all the values in tf are logical 0 (false). The function sets the score threshold to the maximum score value. Display the threshold value.
Mdl.ScoreThreshold
ans = 0.8600
Find anomalies in adulttest by using the trained isolation forest model.
[tf_test,s_test] = isanomaly(Mdl,adulttest);
The isanomaly function returns the anomaly indicators tf_test and scores s_test for adulttest. By default, isanomaly identifies observations with scores above the threshold (Mdl.ScoreThreshold) as anomalies.
Create histograms for the anomaly scores s and s_test. Create a vertical line at the threshold of the anomaly scores.
histogram(s,Normalization="probability") hold on histogram(s_test,Normalization="probability") xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold])) legend("Training Data","Test Data",Location="northwest") hold off

Display the observation index of the anomalies in the test data.
find(tf_test)
ans = 15655
The anomaly score distribution of the test data is similar to that of the training data, so isanomaly detects a small number of anomalies in the test data with the default threshold value. You can specify a different threshold value by using the ScoreThreshold name-value argument. For an example, see Specify Anomaly Score Threshold.
Specify the threshold value for anomaly scores by using the ScoreThreshold name-value argument of isanomaly.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year.
load census1994census1994 contains the training data set adultdata and the test data set adulttest.
Train an isolation forest model for adultdata.
rng("default") % For reproducibility [Mdl,tf,scores] = iforest(adultdata);
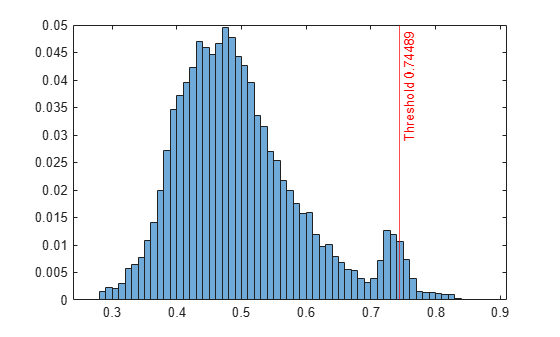
Plot a histogram of the score values. Create a vertical line at the default score threshold.
histogram(scores,Normalization="probability"); xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold]))
Find the anomalies in the test data using the trained isolation forest model. Use a different threshold from the default threshold value obtained when training the isolation forest model.
First, determine the score threshold by using the isoutlier function.
[~,~,U] = isoutlier(scores)
U = 0.7449
Specify the value of the ScoreThreshold name-value argument as U.
[tf_test,scores_test] = isanomaly(Mdl,adulttest,ScoreThreshold=U); histogram(scores_test,Normalization="probability") xline(U,"r-",join(["Threshold" U]))
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
isanomaly considers NaN, '' (empty character vector), "" (empty string), <missing>, and <undefined> values in Tbl and NaN values in X to be missing values.
isanomaly uses observations with missing values to find splits on
variables for which these observations have valid values. The function might place
these observations in a branch node, not a leaf node. Then
isanomaly computes anomaly scores by using the
distance from the root node to the branch node. The function places an observation
with all missing values in the root node, so the score value becomes 1.
References
[1] Liu, F. T., K. M. Ting, and Z. Zhou. "Isolation Forest," 2008 Eighth IEEE International Conference on Data Mining. Pisa, Italy, 2008, pp. 413-422.
Extended Capabilities
Version History
Introduced in R2021b