plotDiagnostics
Plot observation diagnostics of linear regression model
Syntax
Description
plotDiagnostics creates a plot of observation diagnostics
such as leverage, Cook's distance, and delete-1 statistics to identify outliers and
influential observations.
plotDiagnostics( creates a leverage
plot of the linear regression model (mdl)mdl) observations. A
dotted line in the plot represents the recommended threshold values.
plotDiagnostics(___,
specifies additional options using one or more name-value arguments in addition to
any of the input argument combinations in the previous syntaxes. For example, you
can specify the marker symbol and size for the data points.Name,Value)
h = plotDiagnostics(___)h to modify the properties of a specific line or contour
after you create the plot. For a list of properties, see Line Properties and Contour Properties.
Examples
Plot the leverage values and Cook's distances of observations and find the outliers.
Load the carsmall data set and fit a linear regression model of the mileage as a function of model year, weight, and weight squared.
load carsmall tbl = table(MPG,Weight); tbl.Year = categorical(Model_Year); mdl = fitlm(tbl,'MPG ~ Year + Weight^2');
Plot the leverage values.
plotDiagnostics(mdl) legend('show') % Show the legend
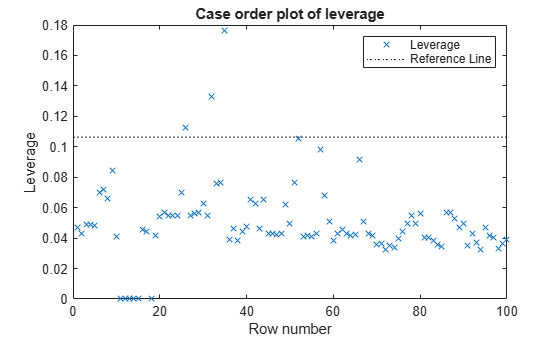
The dotted line represents the recommended threshold value 2*p/n, where p is the number of coefficients, and n is the number of observations. Find the threshold value using the NumCoefficients and NumObservations properties.
t_leverage = 2*mdl.NumCoefficients/mdl.NumObservations
t_leverage = 0.1064
Find the observations with leverage values that exceed the threshold value.
find(mdl.Diagnostics.Leverage > t_leverage)
ans = 3×1
26
32
35
You can also find an observation number by using a data tip. Select the data points above the threshold line to display their data tips. The data tip includes the x-axis and y-axis values for the selected point, along with the observation number.
Plot the Cook's distance values.
plotDiagnostics(mdl,'cookd')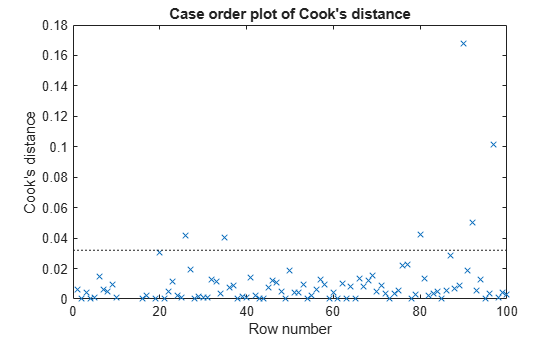
The dotted line represents the recommended threshold value. Compute the threshold value t_cookd.
t_cookd = 3*mean(mdl.Diagnostics.CooksDistance,'omitnan')t_cookd = 0.0320
Find the observations with the Cook's distance values that exceed the threshold value.
find(mdl.Diagnostics.CooksDistance > t_cookd)
ans = 6×1
26
35
80
90
92
97
Two observations (26 and 35) are outliers by both measures, but some points (32, 80, 90, 92, and 97) are outliers by only one measure.
Input Arguments
Name-Value Arguments
Specify optional pairs of arguments as
Name1=Value1,...,NameN=ValueN, where Name is
the argument name and Value is the corresponding value.
Name-value arguments must appear after other arguments, but the order of the
pairs does not matter.
Before R2021a, use commas to separate each name and value, and enclose
Name in quotes.
Example: 'Color','blue','Marker','o'
Note
The graphical properties listed here are only a subset. For a complete list, see Line Properties. The specified properties determine the appearance of diagnostic data points.
Line color, specified an RGB triplet, hexadecimal color code, color name, or short name for one of the color options listed in the following table.
The Color name-value argument also determines marker outline color and
marker fill color if MarkerEdgeColor is
"auto" (default) and MarkerFaceColor is
"auto".
For a custom color, specify an RGB triplet or a hexadecimal color code.
An RGB triplet is a three-element row vector whose elements specify the intensities of the red, green, and blue components of the color. The intensities must be in the range
[0,1], for example,[0.4 0.6 0.7].A hexadecimal color code is a string scalar or character vector that starts with a hash symbol (
#) followed by three or six hexadecimal digits, which can range from0toF. The values are not case sensitive. Therefore, the color codes"#FF8800","#ff8800","#F80", and"#f80"are equivalent.
Alternatively, you can specify some common colors by name. This table lists the named color options, the equivalent RGB triplets, and the hexadecimal color codes.
| Color Name | Short Name | RGB Triplet | Hexadecimal Color Code | Appearance |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan"
| "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|
"none" | Not applicable | Not applicable | Not applicable | No color |
This table lists the default color palettes for plots in the light and dark themes.
| Palette | Palette Colors |
|---|---|
Before R2025a: Most plots use these colors by default. |
|
|
|
You can get the RGB triplets and hexadecimal color codes for these palettes using the orderedcolors and rgb2hex functions. For example, get the RGB triplets for the "gem" palette and convert them to hexadecimal color codes.
RGB = orderedcolors("gem");
H = rgb2hex(RGB);Before R2023b: Get the RGB triplets using RGB =
get(groot,"FactoryAxesColorOrder").
Before R2024a: Get the hexadecimal color codes using H =
compose("#%02X%02X%02X",round(RGB*255)).
Example: Color="blue"
Data Types: single | double | string | char
Line width, specified as a positive value in points. If the line has markers, then the line width also affects the marker edges.
Example: LineWidth=0.75
Data Types: single | double
Marker symbol, specified as one of the values in this table.
| Marker | Description | Resulting Marker |
|---|---|---|
"o" | Circle |
|
"+" | Plus sign |
|
"*" | Asterisk |
|
"." | Point |
|
"x" | Cross |
|
"_" | Horizontal line |
|
"|" | Vertical line |
|
"square" | Square |
|
"diamond" | Diamond |
|
"^" | Upward-pointing triangle |
|
"v" | Downward-pointing triangle |
|
">" | Right-pointing triangle |
|
"<" | Left-pointing triangle |
|
"pentagram" | Pentagram |
|
"hexagram" | Hexagram |
|
"none" | No markers | Not applicable |
Example: Marker="+"
Data Types: string | char
Marker outline color, specified an RGB triplet, hexadecimal color code, color
name, or short name for one of the color options listed in the
Color name-value argument.
The default value "auto" uses the same color specified by using
the Color name-value argument. You can also specify
"none" for no color.
Example: MarkerEdgeColor="blue"
Data Types: single | double | string | char
Marker fill color, specified as an RGB triplet, hexadecimal color code, color name, or short
name for one of the color options listed in the Color
name-value argument. The default value "none" specifies no
color.
The "auto" value uses the same color specified by using the
Color name-value argument.
Example: MarkerFaceColor="blue"
Data Types: single | double | string | char
Marker size, specified as a positive value in points.
Example: MarkerSize=2
Data Types: single | double
Output Arguments
More About
Tips
The data cursor displays the values of the selected plot point in a data tip (small text box located next to the data point). The data tip includes the x-axis and y-axis values for the selected point, along with the observation name or number.
Use
legend('show')to show the pre-populated legend.
Alternative Functionality
A
LinearModelobject provides multiple plotting functions.When creating a model, use
plotAddedto understand the effect of adding or removing a predictor variable.When verifying a model, use
plotDiagnosticsto find questionable data and to understand the effect of each observation. Also, useplotResidualsto analyze the residuals of the model.After fitting a model, use
plotAdjustedResponse,plotPartialDependence, andplotEffectsto understand the effect of a particular predictor. UseplotInteractionto understand the interaction effect between two predictors. Also, useplotSliceto plot slices through the prediction surface.
References
[1] Neter, J., M. H. Kutner, C. J. Nachtsheim, and W. Wasserman. Applied Linear Statistical Models, Fourth Edition. Chicago: McGraw-Hill Irwin, 1996.