predict
Predict response of nonlinear regression model
Syntax
Description
Examples
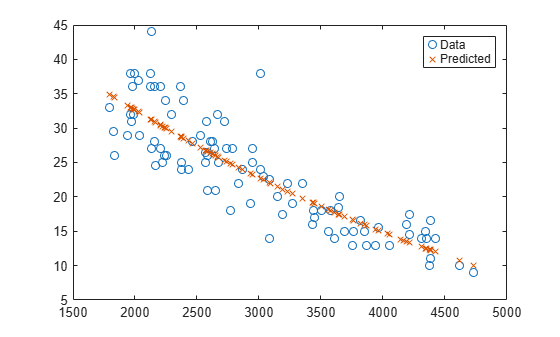
Create a nonlinear model of car mileage as a function of weight, and predict the response.
Create an exponential model of car mileage as a function of weight from the carsmall data. Scale the weight by a factor of 1000 so all the variables are roughly equal in size.
load carsmall X = Weight; y = MPG; modelfun = 'y ~ b1 + b2*exp(-b3*x/1000)'; beta0 = [1 1 1]; mdl = fitnlm(X,y,modelfun,beta0);
Create predicted responses to the data.
Xnew = X; ypred = predict(mdl,Xnew);
Plot the original responses and the predicted responses to see how they differ.
plot(X,y,'o',X,ypred,'x') legend('Data','Predicted')
Create a nonlinear model of car mileage as a function of weight, and examine confidence intervals of some responses.
Create an exponential model of car mileage as a function of weight from the carsmall data. Scale the weight by a factor of 1000 so all the variables are roughly equal in size.
load carsmall X = Weight; y = MPG; modelfun = 'y ~ b1 + b2*exp(-b3*x/1000)'; beta0 = [1 1 1]; mdl = fitnlm(X,y,modelfun,beta0);
Create predicted responses to the smallest, mean, and largest data points.
Xnew = [min(X);mean(X);max(X)]; [ypred,yci] = predict(mdl,Xnew)
ypred = 3×1
34.9469
22.6868
10.0617
yci = 3×2
32.5212 37.3726
21.4061 23.9674
7.0148 13.1086
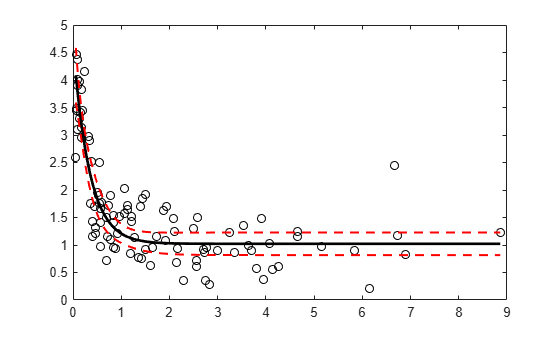
Generate sample data from the nonlinear regression model
where , , and are coefficients, and the error term is normally distributed with mean 0 and standard deviation 0.5.
modelfun = @(b,x)(b(1)+b(2)*exp(-b(3)*x)); rng('default') % For reproducibility b = [1;3;2]; x = exprnd(2,100,1); y = modelfun(b,x) + normrnd(0,0.5,100,1);
Fit the nonlinear model using robust fitting options.
opts = statset('nlinfit'); opts.RobustWgtFun = 'bisquare'; b0 = [2;2;2]; mdl = fitnlm(x,y,modelfun,b0,'Options',opts);
Plot the fitted regression model and simultaneous 95% confidence bounds.
xrange = [min(x):.01:max(x)]'; [ypred,yci] = predict(mdl,xrange,'Simultaneous',true); figure() plot(x,y,'ko') % observed data hold on plot(xrange,ypred,'k','LineWidth',2) plot(xrange,yci','r--','LineWidth',1.5)
Load sample data.
S = load('reaction');
X = S.reactants;
y = S.rate;
beta0 = S.beta;Specify a function handle for observation weights, then fit the Hougen-Watson model to the rate data using the specified observation weights function.
a = 1; b = 1;
weights = @(yhat) 1./((a + b*abs(yhat)).^2);
mdl = fitnlm(X,y,@hougen,beta0,'Weights',weights);Compute the 95% prediction interval for a new observation with reactant levels [100,100,100] using the observation weight function.
[ypred,yci] = predict(mdl,[100,100,100],'Prediction','observation', ... 'Weights',weights)
ypred = 1.8149
yci = 1×2
1.5264 2.1033
Input Arguments
Name-Value Arguments
Output Arguments
Tips
References
[1] Lane, T. P. and W. H. DuMouchel. “Simultaneous Confidence Intervals in Multiple Regression.” The American Statistician. Vol. 48, No. 4, 1994, pp. 315–321. Available at https://doi.org/10.1080/00031305.1994.10476090
[2] Seber, G. A. F., and C. J. Wild. Nonlinear Regression. Hoboken, NJ: Wiley-Interscience, 2003.
Version History
Introduced in R2012a