Simulation Acceleration Using Parallel Computing Toolbox
This example showcases the runtime performance effects of using parallel processing (using the parfor (Parallel Computing Toolbox) function) and highlights two ways to use parfor for a communications link simulation. For additional acceleration techniques, see the Tips for Accelerating MATLAB Performance article.
To run the parallel processing section of this example, you must have Parallel Computing Toolbox™ product.
Example Structure
This example examines various implementations of this transceiver system in MATLAB.
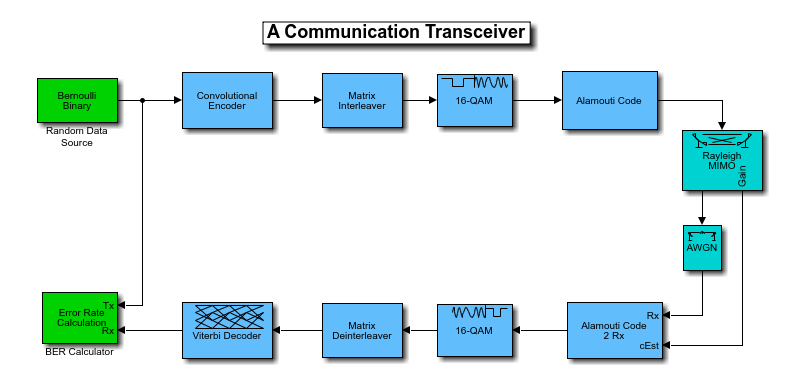
This system is composed of a transmitter, a channel model, and a receiver. The transmitter processes the input bit stream with a convolutional encoder, an interleaver, a modulator, and a MIMO space-time block encoder (see [ 1 ], [ 2 ]). The transmitted signal is then processed by a 2x2 MIMO block fading channel and an additive white gaussian noise (AWGN) channel. The receiver processes its input signal with a 2x2 MIMO space-time block decoder, a demodulator, a deinterleaver, and a Viterbi decoder to recover the best estimate of the input bit stream at the receiver.
The example follows this workflow:
Create a function that runs the simulation algorithms
Use the MATLAB Profiler GUI to identify speed bottlenecks
Achieve faster simulation using parallel processing runs
Create Function that Runs Simulation Algorithms
Start with a function that represents the first version or baseline implementation of this algorithm. The inputs to the helperAccelBaseline function are the value of the current frame (EbNo), minimum number of errors (minNumErr) and the maximum number of bits processed (maxNumBits). is the ratio of energy per bit to noise power spectral density. The function output is the bit error rate (BER) information for each point.
type helperAccelBaselinefunction ber = helperAccelBaseline(EbNo, minNumErr, maxNumBits)
%helperAccelBaseline Simulate a communications link
%
% BER = helperAccelBaseline(EBNO,MINERR,MAXBIT) returns the bit error
% rate (BER) of a communications link that includes convolutional coding,
% interleaving, QAM modulation, an Alamouti space-time block code, and a
% MIMO block fading channel with AWGN. EBNO is the energy per bit to
% noise power spectral density ratio (Eb/No) of the AWGN channel in dB,
% MINERR is the minimum number of errors to collect, and MAXBIT is the
% maximum number of simulated bits so that the simulations do not run
% indefinitely if the Eb/No value is too high.
% Copyright 2011-2025 The MathWorks, Inc.
M = 16; % Modulation Order
k = log2(M); % Bits per Symbol
codeRate = 1/2; % Coding Rate
adjSNR = convertSNR(EbNo,"ebno","BitsPerSymbol",k,"CodingRate",codeRate);
trellis = poly2trellis(7,[171 133]);
tblen = 32;
dataFrameLen = 1998;
% Add 6 zeros to terminate the convolutional code
chanFrameLen=(dataFrameLen+6)/codeRate;
permvec=[1:3:chanFrameLen 2:3:chanFrameLen 3:3:chanFrameLen]';
ostbcEnc = comm.OSTBCEncoder(NumTransmitAntennas=2);
ostbcComb = comm.OSTBCCombiner(NumTransmitAntennas=2,NumReceiveAntennas=2);
mimoChan = comm.MIMOChannel(MaximumDopplerShift=0,PathGainsOutputPort=true);
berCalc = comm.ErrorRate;
% Run Simulation
ber = zeros(3,1);
while (ber(3) <= maxNumBits) && (ber(2) < minNumErr)
data = [randi([0 1],dataFrameLen,1,'int8');zeros(6,1,'int8')];
encOut = convenc(data,trellis); % Convolutional Encoder
intOut = intrlv(encOut,permvec); % Interleaver
modOut = qammod(intOut,M,'InputType','bit', ...
'OutputDataType','single'); % QAM Modulator
stbcOut = ostbcEnc(modOut); % Alamouti Space-Time Block Encoder
[chanOut, pathGains] = mimoChan(stbcOut); % 2x2 MIMO Channel
chEst = squeeze(sum(pathGains,2));
rcvd = awgn(chanOut,adjSNR,'measured'); % AWGN channel
stbcDec = ostbcComb(rcvd,chEst); % Alamouti Space-Time Block Combiner
demodOut = qamdemod(stbcDec,M,'OutputType','bit',...
'OutputDataType','int8'); % QAM Demodulator
deintOut = deintrlv(demodOut,permvec'); % Deinterleaver
decOut = vitdec(deintOut(:),trellis, ... % Viterbi Decoder
tblen,'term','hard');
ber = berCalc(decOut(1:dataFrameLen),double(data(1:dataFrameLen)));
end
As a starting point, measure the time it takes to run this baseline algorithm in MATLAB. Use the MATLAB timing functions (tic and toc) to record the elapsed runtime to complete processing of a for-loop that iterates over values from 0 to 7 dB.
minEbNodB = 0; maxEbNodB = 7; EbNoVec = minEbNodB:maxEbNodB; minNumErr = 5000; maxNumBits = 1e7; N = 1; str = 'Baseline'; % Run the function once to load it into memory and remove overhead from % runtime measurements helperAccelBaseline(3,10,1e4); berBaseline = zeros(size(minEbNodB:maxEbNodB)); disp('Processing the baseline algorithm.');
Processing the baseline algorithm.
tic; for EbNoIdx = 1:length(EbNoVec) EbNo = EbNoVec(EbNoIdx); y = helperAccelBaseline(EbNo,minNumErr,maxNumBits); berBaseline(EbNoIdx) = y(1); end rtBaseline=toc;
The result shows the simulation time (in seconds) of the baseline algorithm. Use this timing measurement to compare with subsequent accelerated simulation runtimes.
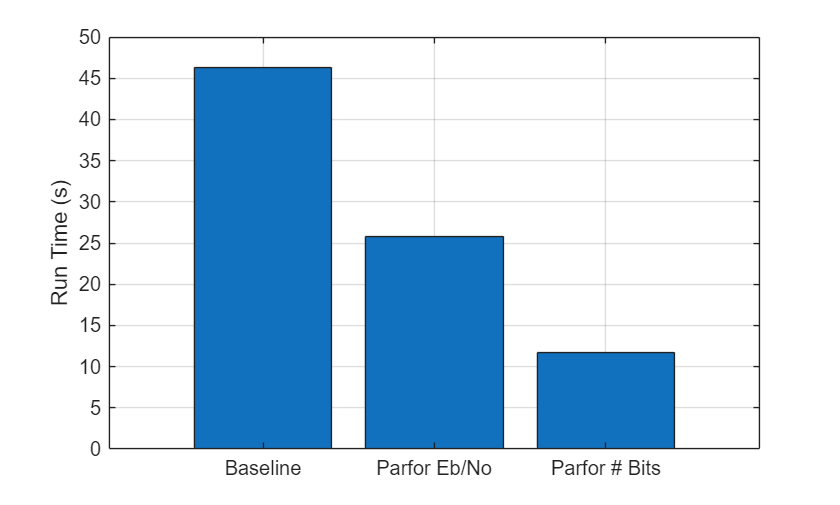
helperAccelReportResults(N,rtBaseline,rtBaseline,str,str);
---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 46.2839 | 1.0000 ----------------------------------------------------------------------------------------------
Identify Speed Bottlenecks by Using MATLAB Profiler App
Identify the processing bottlenecks and problem areas of the baseline algorithm by using the MATLAB Profiler. Obtain the profiler information by executing the following script:
profile on y2 = helperAccelBaseline(6,100,1e6); profile off profile viewer
The Profiler report presents the execution time for each function call of the algorithm. You can sort the functions according to their self-time in a descending order. The first few functions that the Profiler window depicts represent the speed bottleneck of the algorithm. In this case, the vitdec function is identified as the major speed bottleneck.
Achieve Faster Simulation Using Parallel Processing Runs
Utilize multiple cores to increase simulation acceleration by running tasks in parallel. Use parallel processing runs (parfor loops) in MATLAB to perform the work on the number of available workers. Parallel Computing Toolbox enables you to run different iterations of the simulation in parallel. Use the gcp (Parallel Computing Toolbox) function to get the current parallel pool. If a pool is available, the gcp opens the pool and reserves several MATLAB workers to execute iterations of a subsequent parfor-loop. In this example, six workers run locally on a MATLAB client machine.
pool = gcp
Starting parallel pool (parpool) using the 'Processes' profile ...
06-Jan-2026 15:03:26: Job Queued. Waiting for parallel pool job with ID 2 to start ...
Connected to parallel pool with 6 workers.
pool =
ProcessPool with properties:
Connected: true
NumWorkers: 6
Busy: false
Cluster: Processes (Local Cluster)
AttachedFiles: {}
AutoAddClientPath: true
FileStore: [1x1 parallel.FileStore]
ValueStore: [1x1 parallel.ValueStore]
IdleTimeout: 30 minutes (30 minutes remaining)
SpmdEnabled: true
if isempty(pool) pool = parpool end
Run Parallel Over Eb/No Values
Run points in parallel using six workers using a parfor-loop rather than a for-loop as used in the previous cases. Measure the simulation time.
N = N+1; str = 'Parallel runs with parfor over Eb/No'; tag = 'Parfor Eb/No'; helperAccelBaseline(3,10,1e4); berParfor1 = zeros(size(berBaseline)); disp('Processing the algorithm within a parfor-loop.');
Processing the algorithm within a parfor-loop.
tic; parfor EbNoIdx=1:length(EbNoVec) EbNo = EbNoVec(EbNoIdx); y = helperAccelBaseline(EbNo,minNumErr,maxNumBits); berParfor1(EbNoIdx) = y(1); end rt=toc;
The result adds the simulation time of the algorithm executing within a parfor-loop to the previous results. Note that by running the algorithm within a parfor-loop, the elapsed time to complete the simulation is shorter. The basic concept of a parfor-loop is the same as the standard MATLAB for-loop. The difference is that parfor divides the loop iterations into groups so that each worker executes some portion of the total number of iterations. Because several MATLAB workers can be computing concurrently on the same loop, a parfor-loop provides significantly better performance than a normal serial for-loop.
helperAccelReportResults(N,rtBaseline,rt,str,tag);
---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 46.2839 | 1.0000 2. Parallel runs with parfor over Eb/No | 25.8201 | 1.7926 ----------------------------------------------------------------------------------------------
Run Parallel Over Number of Bits
In the previous section, the total simulation time is mainly determined by the highest point. You can further accelerate the simulations by dividing up the number of bits simulated for each point over the workers. Run each point in parallel using six workers using a parfor-loop. Measure the simulation time.
N = N+1; str = 'Parallel runs with parfor over number of bits'; tag = 'Parfor # Bits'; helperAccelBaseline(3,10,1e4); berParfor2 = zeros(size(berBaseline)); disp('Processing the second version of the algorithm within a parfor-loop.');
Processing the second version of the algorithm within a parfor-loop.
tic; % Calculate number of bits to be simulated on each worker minNumErrPerWorker = minNumErr / pool.NumWorkers; maxNumBitsPerWorker = maxNumBits / pool.NumWorkers; for EbNoIdx = 1:length(EbNoVec) EbNo = EbNoVec(EbNoIdx); numErr = zeros(pool.NumWorkers,1); parfor w = 1:pool.NumWorkers y = helperAccelBaseline(EbNo,minNumErrPerWorker,maxNumBitsPerWorker); numErr(w) = y(2); numBits(w) = y(3); end berParfor2(EbNoIdx) = sum(numErr)/sum(numBits); end rt = toc;
The result adds the simulation time of the algorithm executing within a parfor-loop where this time each worker simulates the same point. Note that by running this version within a parfor-loop we get the fastest simulation performance. The difference is that parfor divides the number of bits that needs to be simulated over the workers. This approach reduces the simulation time of even the highest value by evenly distributing load (specifically, the number of bits to simulate) over workers.
helperAccelReportResults(N,rtBaseline,rt,str,tag);
---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 46.2839 | 1.0000 2. Parallel runs with parfor over Eb/No | 25.8201 | 1.7926 3. Parallel runs with parfor over number of bits | 11.6934 | 3.9581 ----------------------------------------------------------------------------------------------
Summary
You can significantly speed up simulations of your communications algorithms with the use of parallel processing runs.
Parallel processing runs can substantially accelerate simulation by computing different iterations of your algorithm concurrently across a number of MATLAB workers.
Parallelizing each point individually can accelerate further by speeding up even the longest running point.
The following shows the run time of all three approaches as a bar graph. The results may vary based on the specific algorithm, available workers, and selection of minimum number of errors and maximum number of bits.
results = helperAccelReportResults;
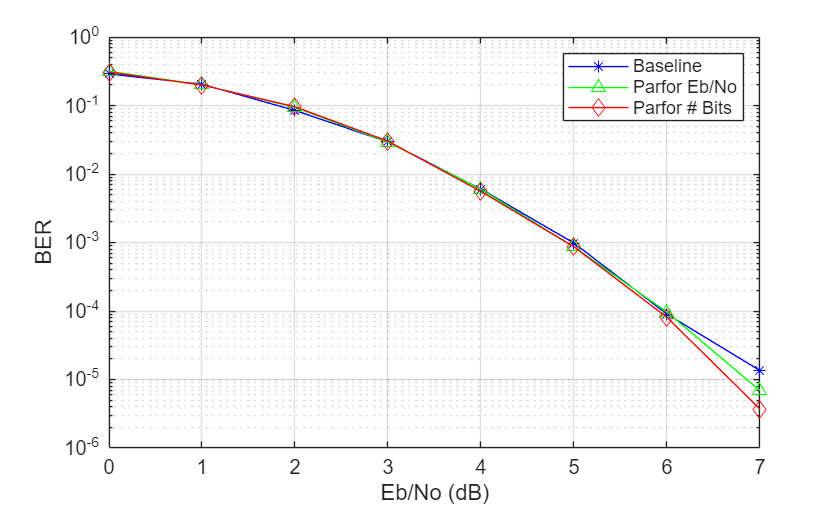
This plot shows the BER curves for the different simulation processing approaches match each other closely. Each plotted point ran with the maximum number of input bits set to ten million (maxNumBits=1e7) and the minimum number of bit errors set to five thousand (minNumErr=5000).
semilogy(EbNoVec, berBaseline, '*-b'); hold on; grid on; semilogy(EbNoVec, berParfor1, '^-g') semilogy(EbNoVec, berParfor2, 'd-r') xlabel('Eb/No (dB)'); ylabel('BER') legend('Baseline','Parfor Eb/No','Parfor # Bits')
Further Exploration
This example uses the gcp function to reserve several MATLAB workers that run locally on your MATLAB client machine. By modifying the parallel configurations, you can accelerate the simulation even further by running the algorithm on a larger cluster of workers that are not on your MATLAB client machine. For a description of how to manage and use parallel configurations, see the Discover Clusters and Use Cluster Profiles (Parallel Computing Toolbox) topic.
The following functions are used in this example:
Selected References
S. M. Alamouti, "A simple transmit diversity technique for wireless communications," IEEE® Journal on Selected Areas in Communications, vol. 16, no. 8, pp. 1451-1458, Oct. 1998.
V. Tarokh, H. Jafarkhami, and A. R. Calderbank, "Space-time block codes from orthogonal designs," IEEE Transactions on Information Theory, vol. 45, no. 5, pp. 1456-1467, Jul. 1999.