La traduction de cette page n'est pas à jour. Cliquez ici pour voir la dernière version en anglais.
Traitement audio
Appliquez le Deep Learning à des applications de traitement audio et de la parole en utilisant Deep Learning Toolbox™ avec Audio Toolbox™. Pour des applications de traitement du signal, veuillez consulter Traitement du signal. Pour des applications de télécommunications, veuillez consulter Télécommunications.
Applications
| Signal Labeler | Label signal attributes, regions, and points of interest |
Fonctions
Blocs
Rubriques
- Deep Learning for Audio Applications (Audio Toolbox)
Learn common tools and workflows to apply deep learning to audio applications.
- Classify Sound Using Deep Learning (Audio Toolbox)
Train, validate, and test a simple long short-term memory (LSTM) to classify sounds.
- Adapt Pretrained Audio Network for New Data Using Deep Network Designer
This example shows how to interactively adapt a pretrained network to classify new audio signals using Deep Network Designer.
- Audio Transfer Learning Using Experiment Manager
Configure an experiment that compares the performance of multiple pretrained networks applied to a speech command recognition task using transfer learning.
- Compare Speaker Separation Models
Compare the performance, size, and speed of multiple deep learning speaker separation models.
- Speaker Identification Using Custom SincNet Layer and Deep Learning
Perform speech recognition using a custom deep learning layer that implements a mel-scale filter bank.
- Dereverberate Speech Using Deep Learning Networks
Train a deep learning model that removes reverberation from speech.
- Sequential Feature Selection for Audio Features
This example shows a typical workflow for feature selection applied to the task of spoken digit recognition.
- Train Spoken Digit Recognition Network Using Out-of-Memory Audio Data
This example trains a spoken digit recognition network on out-of-memory audio data using a transformed datastore.
- Train Spoken Digit Recognition Network Using Out-of-Memory Features
This example trains a spoken digit recognition network on out-of-memory auditory spectrograms using a transformed datastore.
- Investigate Audio Classifications Using Deep Learning Interpretability Techniques
This example shows how to use interpretability techniques to investigate the predictions of a deep neural network trained to classify audio data.
- Accelerate Audio Deep Learning Using GPU-Based Feature Extraction
Leverage GPUs for feature extraction to decrease the time required to train an audio deep learning model.
- AI for Speech Command Recognition (Audio Toolbox)
Build, train, compress, and deploy a deep learning model for speech command recognition.
- ÉTAPE 1: Train Deep Learning Network for Speech Command Recognition (Audio Toolbox)
- ÉTAPE 2: Prune and Quantize Speech Command Recognition Network (Audio Toolbox)
- ÉTAPE 3: Apply Speech Command Recognition Network in Simulink (Audio Toolbox)
- ÉTAPE 4: Apply Speech Command Recognition Network in Smart Speaker Simulink Model (Audio Toolbox)
- ÉTAPE 5: Deploy Smart Speaker Model on Raspberry Pi (Audio Toolbox)
Informations connexes
Sélection d՚exemples

Compress Machine Fault Recognition Neural Network Using Projection
Compress a pretrained acoustics-based machine fault recognition neural network using projection and principal component analysis.

Audio-Based Anomaly Detection for Machine Health Monitoring
Design an autoencoder neural network to perform anomaly detection for machine sounds using unsupervised learning.

3-D Speech Enhancement Using Trained Filter and Sum Network
Perform speech enhancement using a pretrained filter and sum network (FaSNet) with ambisonic data.

3-D Sound Event Localization and Detection Using Trained Recurrent Convolutional Neural Network
Perform 3-D sound event localization and detection using a pretrained deep learning model.
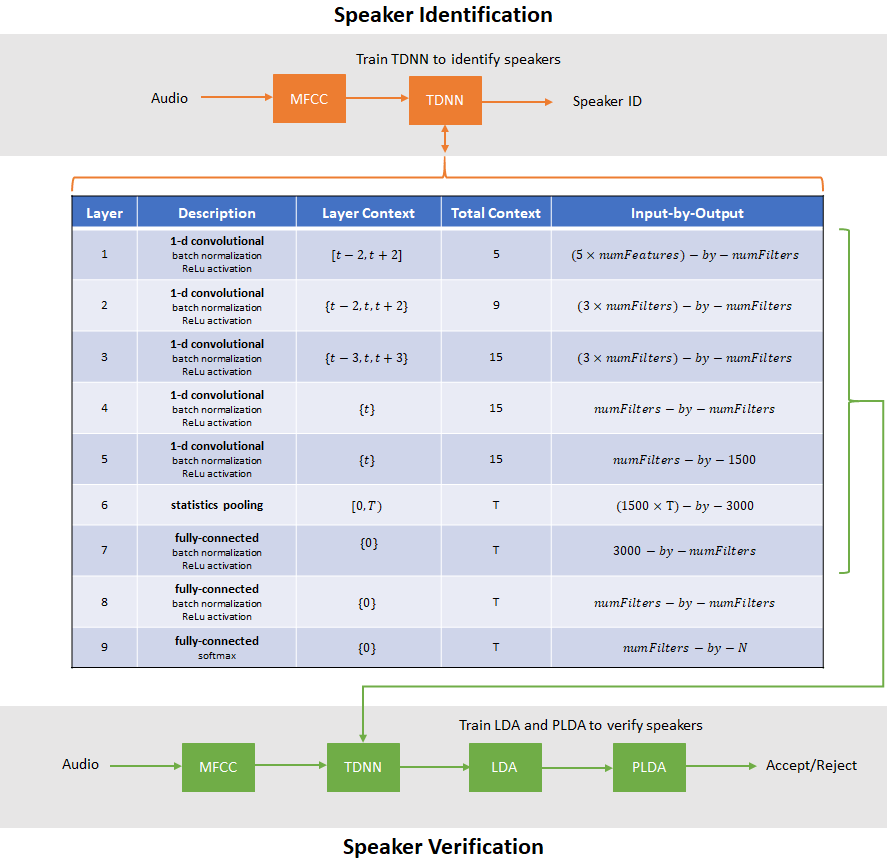
Speaker Recognition Using x-vectors
Develop an x-vector system to perform speaker recognition.
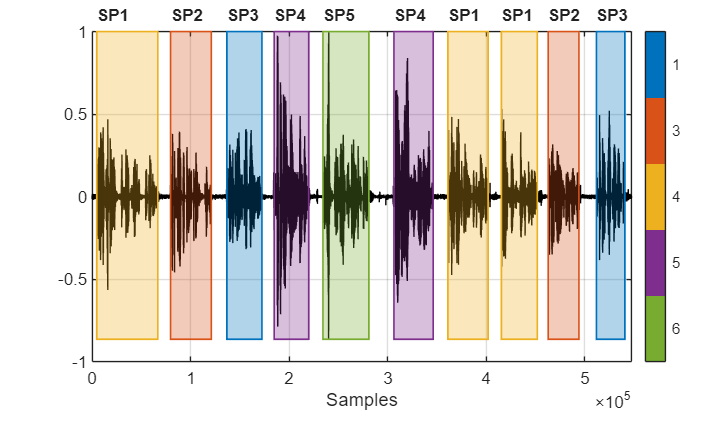
Speaker Diarization Using x-vectors
Speaker diarization is the process of partitioning an audio signal into segments according to speaker identity. It answers the question "who spoke when" without prior knowledge of the speakers and, depending on the application, without prior knowledge of the number of speakers.

Train Speech Command Recognition Model Using Deep Learning
Train a deep learning model that detects the presence of speech commands in audio. The example uses the Speech Commands Dataset [1] to train a convolutional neural network to recognize a set of commands.
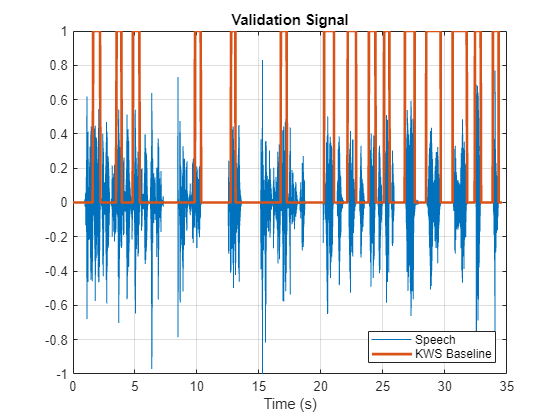
Keyword Spotting in Noise Using MFCC and LSTM Networks
Identify a keyword in noisy speech using a deep learning network. In particular, the example uses a Bidirectional Long Short-Term Memory (BiLSTM) network and mel frequency cepstral coefficients (MFCC).

Denoise Speech Using Deep Learning Networks
Denoise speech signals using deep learning networks. The example compares two types of networks applied to the same task: fully connected, and convolutional.
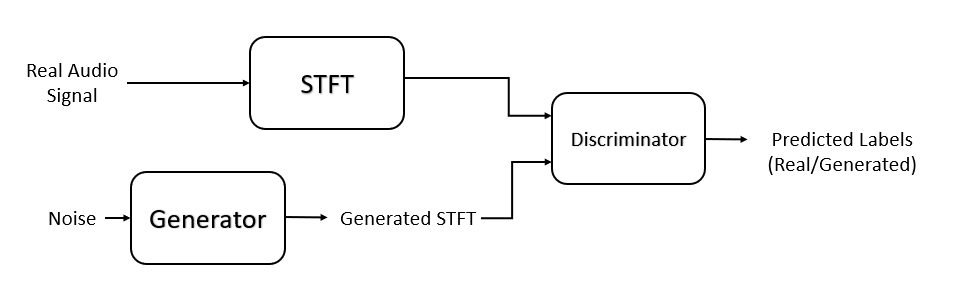
Train Generative Adversarial Network (GAN) for Sound Synthesis
Train and use a generative adversarial network (GAN) to generate sounds.

Voice Activity Detection in Noise Using Deep Learning
In this example, you perform batch and streaming voice activity detection (VAD) in a low SNR environment using a pretrained deep learning model. For details about the model and how it was trained, see Train Voice Activity Detection in Noise Model Using Deep Learning (Audio Toolbox).

Speech Emotion Recognition
Illustrates a simple speech emotion recognition (SER) system using a BiLSTM network. You begin by downloading the data set and then testing the trained network on individual files. The network was trained on a small German-language database [1].

Acoustic Scene Recognition Using Late Fusion
Create a multi-model late fusion system for acoustic scene recognition. The example trains a convolutional neural network (CNN) using mel spectrograms and an ensemble classifier using wavelet scattering. The example uses the TUT dataset for training and evaluation [1].

Train End-to-End Speaker Separation Model
Use an end-to-end deep learning network for speaker-independent speech separation.

Acoustics-Based Machine Fault Recognition
Develop a deep learning model to detect faults in an air compressor and package the system to operate on streaming data.

Audio Event Classification Using TensorFlow Lite on Raspberry Pi
Perform audio event classification on Raspberry Pi® using the YAMNet pretrained deep neural network from the TensorFlow™ Lite library.

Keyword Spotting in Noise Code Generation on Raspberry Pi
Demonstrates code generation for keyword spotting using a Bidirectional Long Short-Term Memory (BiLSTM) network and mel frequency cepstral coefficient (MFCC) feature extraction on Raspberry Pi®. MATLAB® Coder™ with Deep Learning Support enables the generation of a standalone executable (.elf) file on Raspberry Pi. Communication between MATLAB (.mlx) file and the generated executable file occurs over asynchronous User Datagram Protocol (UDP). The incoming speech signal is displayed using a timescope. A mask is shown as a blue rectangle surrounding spotted instances of the keyword, YES. For more details on MFCC feature extraction and deep learning network training, visit Keyword Spotting in Noise Using MFCC and LSTM Networks (Audio Toolbox).

Speech Command Recognition Code Generation on Desktop
Deploy feature extraction and a convolutional neural network (CNN) for speech command recognition. In this example, the generated code is a MATLAB executable (MEX) function, which is called by a MATLAB script that displays the predicted speech command along with the time domain signal and auditory spectrogram. For details about audio preprocessing and network training, see Train Deep Learning Network for Speech Command Recognition (Audio Toolbox).

Acoustics-Based Machine Fault Recognition Code Generation
Generate a MATLAB® standalone executable for acoustics-based machine fault recognition.

Speech Command Recognition on Raspberry Pi Using Simulink
Deploy feature extraction and a convolutional neural network for speech command recognition on Raspberry Pi.