Cette page s'applique à la version précédente. La page correspondante en anglais a été supprimée de la version actuelle.
Boucles d’apprentissage personnalisées
Si la fonction trainingOptions ne propose pas les options d’apprentissage dont vous avez besoin pour votre tâche ou si vous avez une fonction de perte non supportée par la fonction trainnet, vous pouvez définir une boucle d’apprentissage personnalisée. Si un modèle ne peut pas être spécifié comme un réseau de couches, vous pouvez le définir comme une fonction. Pour en savoir plus, veuillez consulter Define Custom Training Loops, Loss Functions, and Networks.
Fonctions
Rubriques
Boucles d’apprentissage personnalisées
- Train Deep Learning Model in MATLAB
Learn how to training deep learning models in MATLAB®. - Define Custom Training Loops, Loss Functions, and Networks
Learn how to define and customize deep learning training loops, loss functions, and models. - Train Sequence Classification Network Using Custom Training Loop
This example shows how to train a network that classifies sequences with a custom learning rate schedule. - Monitor Custom Training Loop Progress
Track and plot custom training loop progress. - Train Network with Multiple Outputs
This example shows how to train a deep learning network with multiple outputs that predict both labels and angles of rotations of handwritten digits. - Train Neural ODE Network
This example shows how to train an augmented neural ordinary differential equation (ODE) network. - Solve ODE Using Physics-Informed Neural Network
This example shows how to train a physics-informed neural network (PINN) to predict the solutions of an ordinary differential equation (ODE). - Speed Up Deep Neural Network Training
Learn how to accelerate deep neural network training.
Différenciation automatique
- Create Bidirectional LSTM (BiLSTM) Function
This example shows how to create a bidirectional long-short term memory (BiLSTM) function for custom deep learning functions. (depuis R2023b) - List of Functions with dlarray Support
View the list of functions that supportdlarrayobjects. - Automatic Differentiation Background
Learn how automatic differentiation works. - Use Automatic Differentiation In Deep Learning Toolbox
How to use automatic differentiation in deep learning.
Sélection d՚exemples

Solve PDE Using Physics-Informed Neural Network
Train a physics-informed neural network (PINN) to predict the solutions of an partial differential equation (PDE).

Train Latent ODE Network with Irregularly Sampled Time-Series Data
Train a latent ordinary differential equation (ODE) autoencoder with time-series data that is sampled at irregular time intervals.

Multivariate Time Series Anomaly Detection Using Graph Neural Network
Detect anomalies in multivariate time series data using a graph neural network (GNN).

Dynamical System Modeling Using Neural ODE
Train a neural network with neural ordinary differential equations (ODEs) to learn the dynamics of a physical system.

Sequence-to-Sequence Translation Using Attention
Convert decimal strings to Roman numerals using a recurrent sequence-to-sequence encoder-decoder model with attention.

Image Captioning Using Attention
Train a deep learning model for image captioning using attention.
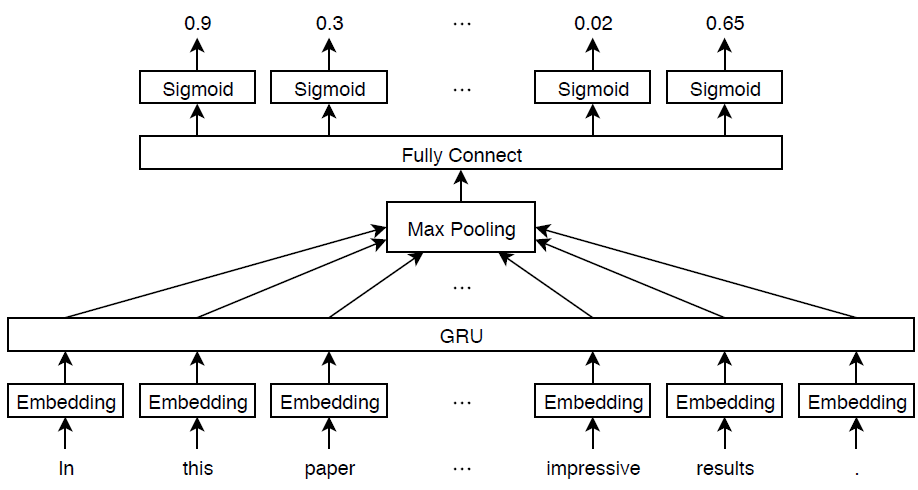
Multilabel Text Classification Using Deep Learning
Classify text data that has multiple independent labels.