fit
Fit simple model of local interpretable model-agnostic explanations (LIME)
Syntax
Description
newresults = fit(results,queryPoint,numImportantPredictors)queryPoint) by
using the specified number of important predictors
(numImportantPredictors). The function returns a lime object
newresults that contains the new simple model.
fit uses the simple model options that you specify when you create
the lime object results. You can change the options
using the name-value pair arguments of the fit function.
newresults = fit(results,queryPoint,numImportantPredictors,Name,Value)'SimpleModelType','tree' to fit a decision tree model.
Examples
Train a regression model and create a lime object that uses a linear simple model. When you create a lime object, if you do not specify a query point and the number of important predictors, then the software generates samples of a synthetic data set but does not fit a simple model. Use the object function fit to fit a simple model for a query point. Then display the coefficients of the fitted linear simple model by using the object function plot.
Load the carbig data set, which contains measurements of cars made in the 1970s and early 1980s.
load carbigCreate a table containing the predictor variables Acceleration, Cylinders, and so on, as well as the response variable MPG.
tbl = table(Acceleration,Cylinders,Displacement,Horsepower,Model_Year,Weight,MPG);
Removing missing values in a training set can help reduce memory consumption and speed up training for the fitrkernel function. Remove missing values in tbl.
tbl = rmmissing(tbl);
Create a table of predictor variables by removing the response variable from tbl.
tblX = removevars(tbl,'MPG');Train a blackbox model of MPG by using the fitrkernel function.
rng('default') % For reproducibility mdl = fitrkernel(tblX,tbl.MPG,'CategoricalPredictors',[2 5]);
Create a lime object. Specify a predictor data set because mdl does not contain predictor data.
results = lime(mdl,tblX)
results =
lime with properties:
BlackboxModel: [1×1 RegressionKernel]
DataLocality: 'global'
CategoricalPredictors: [2 5]
Type: 'regression'
X: [392×6 table]
QueryPoint: []
NumImportantPredictors: []
NumSyntheticData: 5000
SyntheticData: [5000×6 table]
Fitted: [5000×1 double]
SimpleModel: []
ImportantPredictors: []
BlackboxFitted: []
SimpleModelFitted: []
results contains the generated synthetic data set. The SimpleModel property is empty ([]).
Fit a linear simple model for the first observation in tblX. Specify the number of important predictors to find as 3.
queryPoint = tblX(1,:)
queryPoint=1×6 table
Acceleration Cylinders Displacement Horsepower Model_Year Weight
____________ _________ ____________ __________ __________ ______
12 8 307 130 70 3504
results = fit(results,queryPoint,3);
Plot the lime object results by using the object function plot.
plot(results)

The plot displays two predictions for the query point, which correspond to the BlackboxFitted property and the SimpleModelFitted property of results.
The horizontal bar graph shows the coefficient values of the simple model, sorted by their absolute values. LIME finds Horsepower, Model_Year, and Cylinders as important predictors for the query point.
Model_Year and Cylinders are categorical predictors that have multiple categories. For a linear simple model, the software creates one less dummy variable than the number of categories for each categorical predictor. The bar graph displays only the most important dummy variable. You can check the coefficients of the other dummy variables using the SimpleModel property of results. Display the sorted coefficient values, including all categorical dummy variables.
[~,I] = sort(abs(results.SimpleModel.Beta),'descend'); table(results.SimpleModel.ExpandedPredictorNames(I)',results.SimpleModel.Beta(I), ... 'VariableNames',{'Expanded Predictor Name','Coefficient'})
ans=17×2 table
Expanded Predictor Name Coefficient
__________________________ ___________
{'Horsepower' } -3.5035e-05
{'Model_Year (74 vs. 70)'} -6.1591e-07
{'Model_Year (80 vs. 70)'} -3.9803e-07
{'Model_Year (81 vs. 70)'} 3.4186e-07
{'Model_Year (82 vs. 70)'} -2.2331e-07
{'Cylinders (6 vs. 8)' } -1.9807e-07
{'Model_Year (76 vs. 70)'} 1.816e-07
{'Cylinders (5 vs. 8)' } 1.7318e-07
{'Model_Year (71 vs. 70)'} 1.5694e-07
{'Model_Year (75 vs. 70)'} 1.5486e-07
{'Model_Year (77 vs. 70)'} 1.5151e-07
{'Model_Year (78 vs. 70)'} 1.3864e-07
{'Model_Year (72 vs. 70)'} 6.8949e-08
{'Cylinders (4 vs. 8)' } 6.3098e-08
{'Model_Year (73 vs. 70)'} 4.9696e-08
{'Model_Year (79 vs. 70)'} -2.4822e-08
⋮
Train a classification model and create a lime object that uses a decision tree simple model. Fit multiple models for multiple query points.
Load the CreditRating_Historical data set. The data set contains customer IDs and their financial ratios, industry labels, and credit ratings.
tbl = readtable('CreditRating_Historical.dat');Create a table of predictor variables by removing the columns of customer IDs and ratings from tbl.
tblX = removevars(tbl,["ID","Rating"]);
Train a blackbox model of credit ratings by using the fitcecoc function.
blackbox = fitcecoc(tblX,tbl.Rating,'CategoricalPredictors','Industry')
blackbox =
ClassificationECOC
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Y'
CategoricalPredictors: 6
ClassNames: {'A' 'AA' 'AAA' 'B' 'BB' 'BBB' 'CCC'}
ScoreTransform: 'none'
BinaryLearners: {21×1 cell}
CodingName: 'onevsone'
Properties, Methods
Create a lime object with the blackbox model.
rng('default') % For reproducibility results = lime(blackbox);
Find two query points whose true rating values are AAA and B, respectively.
queryPoint(1,:) = tblX(find(strcmp(tbl.Rating,'AAA'),1),:); queryPoint(2,:) = tblX(find(strcmp(tbl.Rating,'B'),1),:)
queryPoint=2×6 table
WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry
_____ _____ _______ ________ _____ ________
0.121 0.413 0.057 3.647 0.466 12
0.019 0.009 0.042 0.257 0.119 1
Fit a linear simple model for the first query point. Set the number of important predictors to 4.
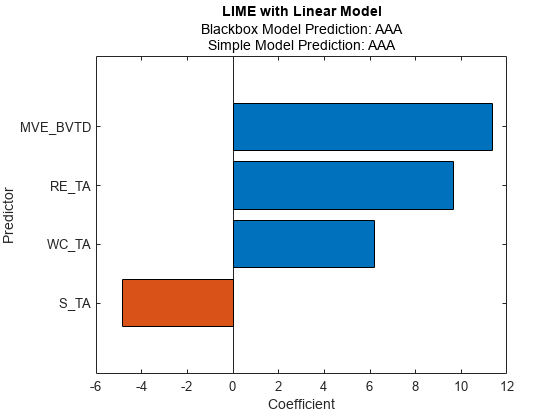
newresults1 = fit(results,queryPoint(1,:),4);
Plot the LIME results newresults1 for the first query point.
plot(newresults1)
Fit a linear decision tree model for the first query point.
newresults2 = fit(results,queryPoint(1,:),6,'SimpleModelType','tree'); plot(newresults2)

The simple models in newresults1 and newresults2 both find MVE_BVTD and RE_TA as important predictors.
Fit a linear simple model for the second query point, and plot the LIME results for the second query point.
newresults3 = fit(results,queryPoint(2,:),4); plot(newresults3)
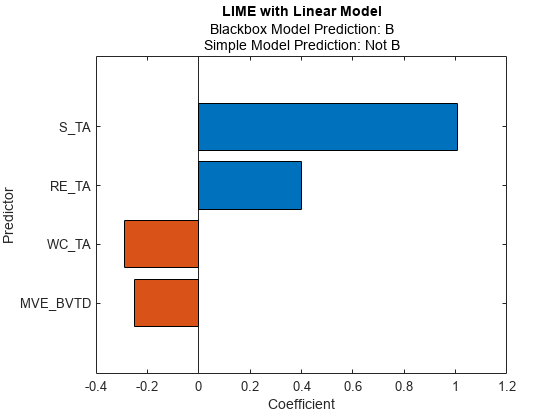
The prediction from the blackbox model is B, but the prediction from the simple model is not B. When the two predictions are not the same, you can specify a smaller 'KernelWidth' value. The software fits a simple model using weights that are more focused on the samples near the query point. If a query point is an outlier or is located near a decision boundary, then the two prediction values can be different, even if you specify a small 'KernelWidth' value. In such a case, you can change other name-value pair arguments. For example, you can generate a local synthetic data set (specify 'DataLocality' of lime as 'local') for the query point and increase the number of samples ('NumSyntheticData' of lime or fit) in the synthetic data set. You can also use a different distance metric ('Distance' of lime or fit).
Fit a linear simple model with a small 'KernelWidth' value.
newresults4 = fit(results,queryPoint(2,:),4,'KernelWidth',0.01);
plot(newresults4)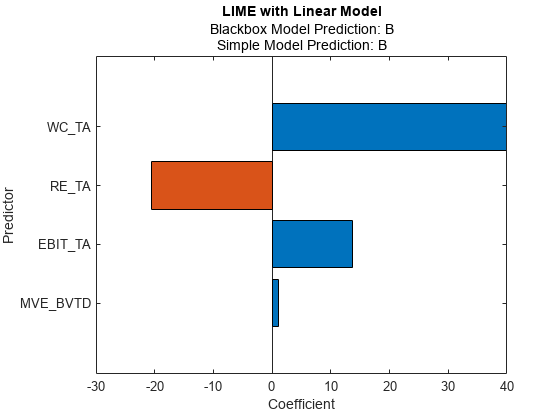
The credit ratings for the first and second query points are AAA and B, respectively. The simple models in newresults1 and newresults4 both find MVE_BVTD, RE_TA, and WC_TA as important predictors. However, their coefficient values are different. The plots show that these predictors act differently depending on the credit ratings.