mle
Maximum likelihood estimates
Description
phat = mle(data,Name=Value)
For example, you can specify the distribution type by using one of these name-value
arguments: Distribution, pdf,
logpdf, or nloglf.
To compute MLEs for a built-in distribution, specify the distribution type by using
Distribution. For example,Distribution="Beta"To compute MLEs for a custom distribution, define the distribution by using
pdf,logpdf, ornloglf, and specify the initial parameter values by usingStart.
Examples
Find MLEs for a built-in distribution that you specify using the Distribution name-value argument.
Load the sample data.
load carbigThe variable MPG contains the miles per gallon for different models of cars.
Draw a histogram of the MPG data.
histogram(MPG)
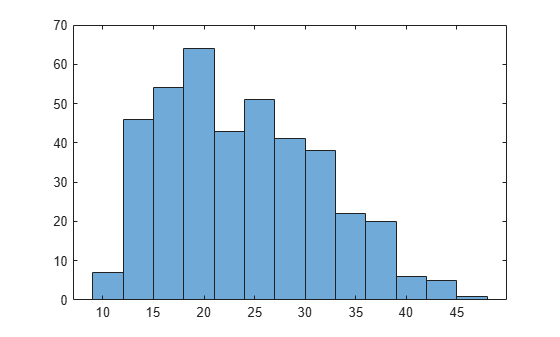
The distribution is somewhat right skewed. A symmetric distribution, such as a normal distribution, might not be a good fit.
Estimate the parameters of the Burr Type XII distribution for the MPG data.
phat = mle(MPG,Distribution="burr")phat = 1×3
34.6447 3.7898 3.5722
The MLE for the scale parameter α is 34.6447. The estimates for the two shape parameters and of the Burr Type XII distribution are 3.7898 and 3.5722, respectively.
Generate 100 random observations from a binomial distribution with the number of trials = 20 and the probability of success = 0.75.
rng("default") % For reproducibility data = binornd(20,0.75,100,1);
Estimate the probability of success and 99% confidence limits using the simulated sample data. You must specify the number of trials (NTrials) for the binomial distribution.
[phat,pci] = mle(data,Distribution="binomial",NTrials=20, ... Alpha=0.01)
phat = 0.7615
pci = 2×1
0.7361
0.7856
The estimate of the probability of success is 0.7615, and the lower and upper limits of the 99% confidence interval are 0.7361 and 0.7856, respectively. This interval covers the true value used to simulate the data.
Generate sample data of size 1000 from a noncentral chi-square distribution with degrees of freedom 8 and noncentrality parameter 3.
rng default % for reproducibility x = ncx2rnd(8,3,1000,1);
Estimate the parameters of the noncentral chi-square distribution from the sample data. The Distribution name-value argument does not support the noncentral chi-square distribution. Therefore, you need to define a custom noncentral chi-square probability density function (pdf) using the pdf name-value argument and the ncx2pdf function. You must also specify the initial parameter values (Start name-value argument) for the custom distribution.
[phat,pci] = mle(x,pdf=@(x,v,d)ncx2pdf(x,v,d),Start=[1,1])
phat = 1×2
8.1052 2.6693
pci = 2×2
7.1121 1.6025
9.0983 3.7362
The estimate for the degrees of freedom is 8.1052 and the noncentrality parameter is 2.6693. The 95% confidence interval for the degrees of freedom is (7.1120,9.0983), and the interval for the noncentrality parameter is (1.6025,3.7362). The confidence intervals include the true parameter values of 8 and 3, respectively.
Load the sample data.
load readmissiontimesThe data includes ReadmissionTime, which has readmission times for 100 patients. This data is simulated.
Define a custom log probability density function (pdf) for a Weibull distribution with the scale parameter lambda and the shape parameter k.
custlogpdf = @(data,lambda,k) ...
log(k)-k*log(lambda)+(k-1)*log(data)-(data/lambda).^k;Estimate the parameters of the custom distribution and specify its initial parameter values (Start name-value argument).
phat = mle(ReadmissionTime,logpdf=custlogpdf,Start=[1,0.75])
phat = 1×2
7.5727 1.4540
The scale and shape parameters of the custom distribution are 7.5727 and 1.4540, respectively.
Load the sample data.
load readmissiontimesThe data includes ReadmissionTime, which has readmission times for 100 patients. This data is simulated.
Define a custom negative loglikelihood function for a Poisson distribution with the parameter lambda, where 1/lambda is the mean of the distribution. You must define the function to accept a logical vector of censorship information and an integer vector of data frequencies, even if you do not use these values in the custom function.
function y = custnloglf(lambda,data,~,~) y = -length(data)*log(lambda)+sum(lambda*data,"omitnan"); end
Estimate the parameter of the custom distribution and specify its initial parameter value (Start name-value argument).
phat = mle(ReadmissionTime,nloglf=@custnloglf,Start=0.05)
phat = 0.1462
Generate sample data of size 1000 from a noncentral chi-square distribution with degrees of freedom 10 and noncentrality parameter 5.
rng("default") % For reproducibility x = ncx2rnd(10,5,1000,1);
Suppose the noncentrality parameter is fixed at the value 5. Estimate the degrees of freedom of the noncentral chi-square distribution from the sample data. To do this, define a custom noncentral chi-square pdf using the pdf name-value argument.
[phat,pci] = mle(x,pdf=@(x,v)ncx2pdf(x,v,5),Start=1)
phat = 9.9307
pci = 2×1
9.5626
10.2989
The estimate for the noncentrality parameter is 9.9307, and the lower and upper limits of the 95% confidence interval are 9.5626 and 10.2989. The confidence interval includes the true parameter value of 10.
Add a scale parameter to the chi-square distribution for adapting to the scale of data, and fit the distribution.
Generate sample data of size 1000 from a chi-square distribution with degrees of freedom 5, and scale the data by a factor of 100.
rng default % For reproducibility x = 100*chi2rnd(5,1000,1);
Estimate the degrees of freedom and the scaling factor. To do this, define a custom chi-square probability density function using the pdf name-value argument. The density function requires a factor for data scaled by .
[phat,pci] = mle(x,pdf=@(x,v,s)chi2pdf(x/s,v)/s,Start=[1,200])
phat = 1×2
5.1079 99.1681
pci = 2×2
4.6862 90.1215
5.5297 108.2146
The estimate for the degrees of freedom is 5.1079 and the scale is 99.1681. The 95% confidence interval for the degrees of freedom is (4.6862,5.5279), and the interval for the scale parameter is (90.1215,108.2146). The confidence intervals include the true parameter values of 5 and 100, respectively.
Load the sample data.
load readmissiontimes;The data includes ReadmissionTime, which has readmission times for 100 patients. The column vector Censored contains the censorship information for each patient, where 1 indicates a right-censored observation, and 0 indicates that the exact readmission time is observed. This data is simulated.
Define a custom probability density function (pdf) and a cumulative distribution function (cdf) for an exponential distribution with the parameter lambda, where 1/lambda is the mean of the distribution. To fit the distribution to a censored data set, you must pass both the pdf and cdf to the mle function.
custpdf = @(data,lambda) lambda*exp(-lambda*data); custcdf = @(data,lambda) 1-exp(-lambda*data);
Estimate the parameter lambda of the custom distribution for the censored sample data. Specify the initial parameter value (Start name-value argument) for the custom distribution.
phat = mle(ReadmissionTime,pdf=custpdf,cdf=custcdf, ...
Start=0.05,Censoring=Censored)phat = 0.1096
Generate double-censored survival data and find the MLEs for a built-in distribution of the data. Then, use the MLEs to create a probability distribution object.
Generate failure times from a Birnbaum-Saunders distribution.
rng("default") % For reproducibility failuretime = random("BirnbaumSaunders",0.3,1,[100,1]);
Assume that the study starts at time 0.1 and ends at time 0.9. The assumption implies that failure times less than 0.1 are left censored, and failure times greater than 0.9 are right censored.
Create a vector in which each element indicates the censorship status of the corresponding observation in failuretime. Use –1, 1, and 0 to indicate left-censored, right-censored, and fully observed observations, respectively.
L = 0.1; U = 0.9; left_censored = (failuretime<L); right_censored = (failuretime>U); c = right_censored - left_censored;
Find MLEs for the double-censored data. Specify the censorship information by using the Censoring name-value argument.
phat = mle(failuretime,Distribution="BirnbaumSaunders",Censoring=c)phat = 1×2
0.2632 1.3040
Create a probability distribution object with the MLEs by using the makedist function.
pd = makedist("BirnbaumSaunders",beta=phat(1),gamma=phat(2))pd =
BirnbaumSaundersDistribution
Birnbaum-Saunders distribution
beta = 0.263184
gamma = 1.304
pd is a BirnbaumSaundersDistribution object. You can use the object functions of pd to evaluate the distribution and generate random numbers. Display the supported object functions.
methods(pd)
Methods for class prob.BirnbaumSaundersDistribution: cdf gather icdf iqr mean median negloglik paramci pdf plot proflik random std truncate var
For example, compute the mean and the variance of the distribution by using the mean and var functions, respectively.
mean(pd)
ans = 0.4869
var(pd)
ans = 0.3681
Generate sample data that represents machine failure times following the Weibull distribution.
rng("default") % For reproducibility failureTimes = wblrnd(5,2,[200,1]);
Specify that observed failure times are values rounded to the nearest second.
observed = round(failureTimes);
observed is interval-censored data. An observation t in observed indicates that the event occurred after time t–0.5 and before time t+0.5.
Create a two-column matrix that includes the censorship information.
intervalTimes = [observed-0.5 observed+0.5];
The failure time must be positive. Find values smaller than eps, and change them to eps.
intervalTimes(intervalTimes < eps) = eps;
Find the MLEs for the Weibull distribution parameters by using intervalTimes.
params = mle(intervalTimes,Distribution="Weibull")params = 1×2
5.0067 2.0049
Plot the results.
figure histogram(observed,Normalization="pdf") hold on x = linspace(0,max(observed)); plot(x,wblpdf(x,params(1),params(2))) legend("Observed Samples","Fitted Distribution") hold off
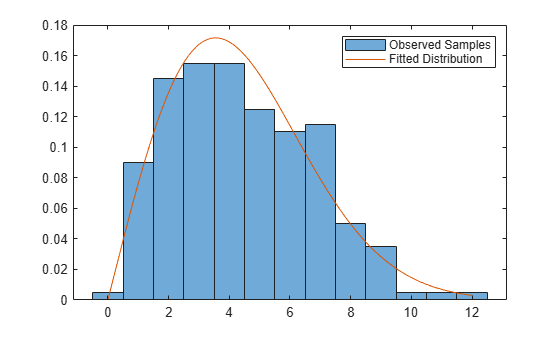
Generate samples from a distribution with finite support, and find the MLEs with customized options for the iterative estimation process.
For a distribution with a region that has zero probability density, mle might try some parameters that have zero density, causing the function to fail to find MLEs. To avoid this problem, you can turn off the option that checks for invalid function values and specify the parameter bounds when you call the mle function.
Generate sample data of size 1000 from a Weibull distribution with the scale parameter 1 and shape parameter 1. Shift the samples by adding 10.
rng("default") % For reproducibility data = wblrnd(1,1,[1000,1]) + 10; histogram(data,Normalization="pdf")
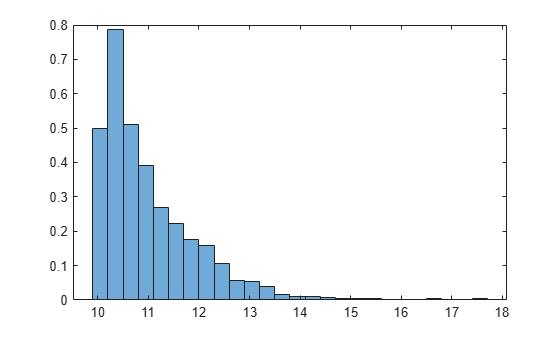
The histogram shows no samples smaller than 10, indicating that the distribution has zero probability in the region smaller than 10. This distribution is a three-parameter Weibull distribution, which includes a third parameter for location (see Three-Parameter Weibull Distribution).
Define a probability density function (pdf) for the three-parameter Weibull distribution.
custompdf = @(x,a,b,c) wblpdf(x-c,a,b);
Find the MLEs by using the mle function. Specify the Options name-value argument to turn off the option that checks for invalid function values. Also, specify the parameter bounds by using the LowerBound and UpperBound name-value arguments. The scale and shape parameters must be positive, and the location parameter must be smaller than the minimum of the sample data.
params = mle(data,pdf=custompdf,Start=[5 5 5], ... Options=statset(FunValCheck="off"), ... LowerBound=[0 0 -Inf],UpperBound=[Inf Inf min(data)])
params = 1×3
1.0258 1.0618 10.0004
The mle function finds accurate estimates for the three parameters. For more details on specifying custom options for the iterative process, see the example Three-Parameter Weibull Distribution.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
When you supply custom distribution functions or use built-in distributions for left-censored, double-censored, interval-censored, or truncated observations,
mlecomputes the parameter estimates using an iterative maximization algorithm. With some models and data, a poor choice for the starting point (Start) can causemleto converge to a local optimum that is not the global maximizer, or to fail to converge entirely. Even in cases for which the loglikelihood is well behaved near the global maximum, the choice of starting point is often crucial to convergence of the algorithm. In particular, if the initial parameter values are far from the MLEs, underflow in the distribution functions can lead to infinite loglikelihoods.
Algorithms
The
mlefunction finds MLEs by minimizing the negative loglikelihood function (that is, maximizing the loglikelihood function) or by using a closed-form solution, if available. The objective function is the negative logarithm value of the product of the sample data (X) probabilities, given the distribution parameters (θ):The probability function P depends on the censorship information for each observation.
Fully observed observation — P(x|θ) = f(x), where f is the probability density function (pdf) with the parameters θ.
Left-censored observation — P(x|θ) = F(x), where F is the cumulative distribution function (cdf) with the parameters θ.
Right-censored observation — P(x|θ) = 1 – F(x).
Interval-censored observation between xL and xU — P(x|θ) = F(xU) – F(xL).
For truncated data,
mlescales the distribution functions so that all the probabilities lie in the truncation bounds [L,U].The
mlefunction computes the confidence intervalspciusing an exact method when it is available, and when the sample data is not truncated and does not include left-censored or interval-censored observations. Otherwise, the function uses the Wald method. An exact method is available for these distributions: binomial, discrete uniform, exponential, normal, lognormal, Poisson, Rayleigh, and continuous uniform.