templateECOC
Error-correcting output codes learner template
Description
t = templateECOC()
If you specify a default template, then the software uses default values for all input arguments during training.
t = templateECOC(Name,Value)
For example, you can specify a coding design, whether to fit posterior probabilities, or the types of binary learners.
If you display t in the Command Window, then
all options appear empty ([]), except those that
you specify using name-value pair arguments. During training, the
software uses default values for empty options.
Examples
Use templateECOC to create a default ECOC template.
t = templateECOC()
t =
Fit template for classification ECOC.
BinaryLearners: ''
Coding: ''
FitPosterior: []
Options: []
VerbosityLevel: []
NumConcurrent: []
Version: 1
Method: 'ECOC'
Type: 'classification'
All properties of the template object are empty except for Method and Type. When you pass t to testckfold, the software fills in the empty properties with their respective default values. For example, the software fills the BinaryLearners property with 'SVM'. For details on other default values, see fitcecoc.
t is a plan for an ECOC learner. When you create it, no computation occurs. You can pass t to testckfold to specify a plan for an ECOC classification model to statistically compare with another model.
One way to select predictors or features is to train two models where one that uses a subset of the predictors that trained the other. Statistically compare the predictive performances of the models. If there is sufficient evidence that model trained on fewer predictors performs better than the model trained using more of the predictors, then you can proceed with a more efficient model.
Load Fisher's iris data set. Plot all 2-dimensional combinations of predictors.
load fisheriris d = size(meas,2); % Number of predictors pairs = nchoosek(1:d,2)
pairs = 6×2
1 2
1 3
1 4
2 3
2 4
3 4
for j = 1:size(pairs,1) subplot(3,2,j) gscatter(meas(:,pairs(j,1)),meas(:,pairs(j,2)),species) xlabel(sprintf('meas(:,%d)',pairs(j,1))) ylabel(sprintf('meas(:,%d)',pairs(j,2))) legend off end
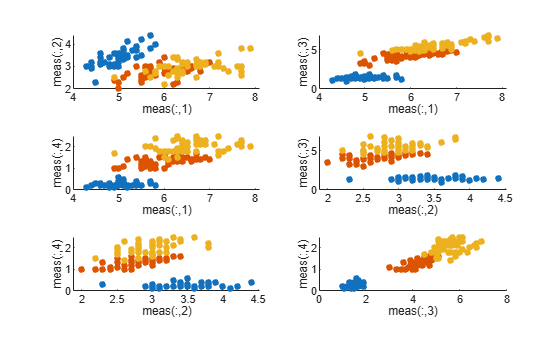
Based on the scatterplot, meas(:,3) and meas(:,4) seem like they separate the groups well.
Create an ECOC template. Specify to use a one-versus-all coding design.
t = templateECOC('Coding','onevsall');
By default, the ECOC model uses linear SVM binary learners. You can choose other, supported algorithms by specifying them using the 'Learners' name-value pair argument.
Test whether an ECOC model that is just trained using predictors 3 and 4 performs at most as well as an ECOC model that is trained using all predictors. Rejecting this null hypothesis means that the ECOC model trained using predictors 3 and 4 performs better than the ECOC model trained using all predictors. Suppose represents the classification error of the ECOC model trained using predictors 3 and 4 and represents the classification error of the ECOC model trained using all predictors, then the test is:
By default, testckfold conducts a 5-by-2 k-fold F test, which is not appropriate as a one-tailed test. Specify to conduct a 5-by-2 k-fold t test.
rng(1); % For reproducibility [h,pValue] = testckfold(t,t,meas(:,pairs(6,:)),meas,species,... 'Alternative','greater','Test','5x2t')
h = logical
0
pValue = 0.8940
The h = 0 indicates that there is not enough evidence to suggest that the model trained using predictors 3 and 4 is more accurate than the model trained using all predictors.
Name-Value Arguments
Output Arguments
Algorithms
References
Version History
Introduced in R2015a
See Also
ClassificationECOC | fitcecoc | designecoc | templateDiscriminant | templateEnsemble | templateKNN | templateSVM | templateTree | predict | testckfold