testckfold
Compare accuracies of two classification models by repeated cross-validation
Syntax
Description
testckfold statistically assesses the accuracies of two
classification models by repeatedly cross-validating the two models, determining the
differences in the classification loss, and then formulating the test statistic by
combining the classification loss differences. This type of test is particularly
appropriate when sample size is limited.
You can assess whether the accuracies of the classification models are different, or
whether one classification model performs better than another. Available tests include a
5-by-2 paired t test, a 5-by-2 paired F test, and
a 10-by-10 repeated cross-validation t test. For more details, see
Repeated Cross-Validation Tests. To speed up computations,
testckfold supports parallel computing (requires a Parallel Computing Toolbox™ license).
h = testckfold(C1,C2,X1,X2)C1 and C2 have
equal accuracy in predicting the true class labels using the predictor
and response data in the tables X1 and X2. h = 1 indicates
to reject the null hypothesis at the 5% significance level.
testckfold conducts the cross-validation
test by applying C1 and C2 to
all predictor variables in X1 and X2,
respectively. The true class labels in X1 and X2 must
be the same. The response variable names in X1, X2, C1.ResponseName,
and C2.ResponseName must be the same.
For examples of ways to compare models, see Tips.
h = testckfold(___,Name,Value)Name,Value pair
arguments. For example, you can specify the type of alternative hypothesis,
the type of test, or the use of parallel computing.
Examples
At each node, fitctree chooses the best predictor to split using an exhaustive search by default. Alternatively, you can choose to split the predictor that shows the most evidence of dependence with the response by conducting curvature tests. This example statistically compares classification trees grown via exhaustive search for the best splits and grown by conducting curvature tests with interaction.
Load the census1994 data set.
load census1994.mat rng(1) % For reproducibility
Grow a default classification tree using the training set, adultdata, which is a table. The response-variable name is 'salary'.
C1 = fitctree(adultdata,'salary')C1 =
ClassificationTree
PredictorNames: {'age' 'workClass' 'fnlwgt' 'education' 'education_num' 'marital_status' 'occupation' 'relationship' 'race' 'sex' 'capital_gain' 'capital_loss' 'hours_per_week' 'native_country'}
ResponseName: 'salary'
CategoricalPredictors: [2 4 6 7 8 9 10 14]
ClassNames: [<=50K >50K]
ScoreTransform: 'none'
NumObservations: 32561
Properties, Methods
C1 is a full ClassificationTree model. Its ResponseName property is 'salary'. C1 uses an exhaustive search to find the best predictor to split on based on maximal splitting gain.
Grow another classification tree using the same data set, but specify to find the best predictor to split using the curvature test with interaction.
C2 = fitctree(adultdata,'salary','PredictorSelection','interaction-curvature')
C2 =
ClassificationTree
PredictorNames: {'age' 'workClass' 'fnlwgt' 'education' 'education_num' 'marital_status' 'occupation' 'relationship' 'race' 'sex' 'capital_gain' 'capital_loss' 'hours_per_week' 'native_country'}
ResponseName: 'salary'
CategoricalPredictors: [2 4 6 7 8 9 10 14]
ClassNames: [<=50K >50K]
ScoreTransform: 'none'
NumObservations: 32561
Properties, Methods
C2 also is a full ClassificationTree model with ResponseName equal to 'salary'.
Conduct a 5-by-2 paired F test to compare the accuracies of the two models using the training set. Because the response-variable names in the data sets and the ResponseName properties are all equal, and the response data in both sets are equal, you can omit supplying the response data.
h = testckfold(C1,C2,adultdata,adultdata)
h = logical
0
h = 0 indicates to not reject the null hypothesis that C1 and C2 have the same accuracies at 5% level.
Conduct a statistical test comparing the misclassification rates of the two models using a 5-by-2 paired F test.
Load Fisher's iris data set.
load fisheriris;Create a naive Bayes template and a classification tree template using default options.
C1 = templateNaiveBayes; C2 = templateTree;
C1 and C2 are template objects corresponding to the naive Bayes and classification tree algorithms, respectively.
Test whether the two models have equal predictive accuracies. Use the same predictor data for each model. testckfold conducts a 5-by-2, two-sided, paired F test by default.
rng(1); % For reproducibility
h = testckfold(C1,C2,meas,meas,species)h = logical
0
h = 0 indicates to not reject the null hypothesis that the two models have equal predictive accuracies.
Conduct a statistical test to assess whether a simpler model has better accuracy than a more complex model using a 10-by-10 repeated cross-validation t test.
Load Fisher's iris data set. Create a cost matrix that penalizes misclassifying a setosa iris twice as much as misclassifying a virginica iris as a versicolor.
load fisheriris;
tabulate(species) Value Count Percent
setosa 50 33.33%
versicolor 50 33.33%
virginica 50 33.33%
Cost = [0 2 2;2 0 1;2 1 0];
ClassNames = {'setosa' 'versicolor' 'virginica'};...
% Specifies the order of the rows and columns in CostThe empirical distribution of the classes is uniform, and the classification cost is slightly imbalanced.
Create two ECOC templates: one that uses linear SVM binary learners and one that uses SVM binary learners equipped with the RBF kernel.
tSVMLinear = templateSVM('Standardize',true); % Linear SVM by default tSVMRBF = templateSVM('KernelFunction','RBF','Standardize',true); C1 = templateECOC('Learners',tSVMLinear); C2 = templateECOC('Learners',tSVMRBF);
C1 and C2 are ECOC template objects. C1 is prepared for linear SVM. C2 is prepared for SVM with an RBF kernel training.
Test the null hypothesis that the simpler model (C1) is at most as accurate as the more complex model (C2) in terms of classification costs. Conduct the 10-by-10 repeated cross-validation test. Request to return p-values and misclassification costs.
rng(1); % For reproducibility [h,p,e1,e2] = testckfold(C1,C2,meas,meas,species,... 'Alternative','greater','Test','10x10t','Cost',Cost,... 'ClassNames',ClassNames)
h = logical
0
p = 0.1077
e1 = 10×10
0 0 0 0.0667 0 0.0667 0.1333 0 0.1333 0
0.0667 0.0667 0 0 0 0 0.0667 0 0.0667 0.0667
0 0 0 0 0 0.0667 0.0667 0.0667 0.0667 0.0667
0.0667 0.0667 0 0.0667 0 0.0667 0 0 0.0667 0
0.0667 0.0667 0.0667 0 0.0667 0.0667 0 0 0 0
0 0 0.1333 0 0 0.0667 0 0 0.0667 0.0667
0.0667 0.0667 0 0 0.0667 0 0 0.0667 0 0.0667
0.0667 0 0.0667 0.0667 0 0.1333 0 0.0667 0 0
0 0.0667 0.1333 0.0667 0.0667 0 0 0 0 0
0 0.0667 0.0667 0.0667 0.0667 0 0 0.0667 0 0
e2 = 10×10
0 0 0 0.1333 0 0.0667 0.1333 0 0.2667 0
0.0667 0.0667 0 0.1333 0 0 0 0.1333 0.1333 0.0667
0.1333 0.1333 0 0 0 0.0667 0 0.0667 0.0667 0.0667
0 0.1333 0 0.0667 0.1333 0.1333 0 0 0.0667 0
0.0667 0.0667 0.0667 0 0.0667 0.1333 0.1333 0 0 0.0667
0.0667 0 0.0667 0.0667 0 0.0667 0.1333 0 0.0667 0.0667
0.2000 0.0667 0 0 0.0667 0 0 0.1333 0 0.0667
0.2000 0 0 0.1333 0 0.1333 0 0.0667 0 0
0 0.0667 0.0667 0.0667 0.1333 0 0.2000 0 0 0
0.0667 0.0667 0 0.0667 0.1333 0 0 0.0667 0.1333 0.0667
The p-value is slightly greater than 0.10, which indicates to retain the null hypothesis that the simpler model is at most as accurate as the more complex model. This result is consistent for any significance level (Alpha) that is at most 0.10.
e1 and e2 are 10-by-10 matrices containing misclassification costs. Row r corresponds to run r of the repeated cross validation. Column k corresponds to test-set fold k within a particular cross-validation run. For example, element (2,4) of e2 is 0.1333. This value means that in cross-validation run 2, when the test set is fold 4, the estimated test-set misclassification cost is 0.1333.
Reduce classification model complexity by selecting a subset of predictor variables (features) from a larger set. Then, statistically compare the accuracy between the two models.
Load the ionosphere data set.
load ionosphereTrain an ensemble of 100 boosted classification trees using AdaBoostM1 and the entire set of predictors. Inspect the importance measure for each predictor.
t = templateTree('MaxNumSplits',1); % Weak-learner template tree object C = fitcensemble(X,Y,'Method','AdaBoostM1','Learners',t); predImp = predictorImportance(C); bar(predImp) h = gca; h.XTick = 1:2:h.XLim(2); title('Predictor Importances') xlabel('Predictor') ylabel('Importance measure')
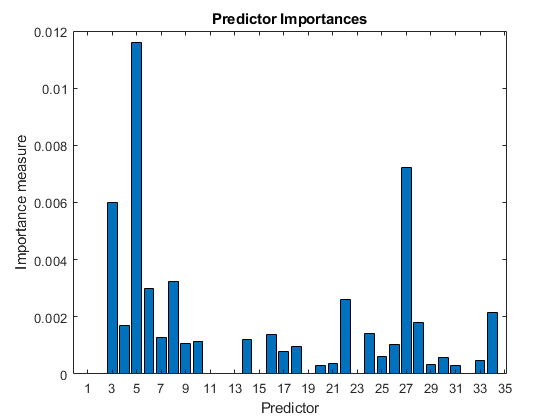
Identify the top five predictors in terms of their importance.
[~,idxSort] = sort(predImp,'descend');
idx5 = idxSort(1:5);Test whether the two models have equal predictive accuracies. Specify the reduced data set and then the full predictor data. Use parallel computing to speed up computations.
s = RandStream('mlfg6331_64'); Options = statset('UseParallel',true,'Streams',s,'UseSubstreams',true); [h,p,e1,e2] = testckfold(C,C,X(:,idx5),X,Y,'Options',Options)
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
h = logical
0
p = 0.4161
e1 = 5×2
0.0686 0.0795
0.0800 0.0625
0.0914 0.0568
0.0400 0.0739
0.0914 0.0966
e2 = 5×2
0.0914 0.0625
0.1257 0.0682
0.0971 0.0625
0.0800 0.0909
0.0914 0.1193
testckfold treats trained classification models as templates, and so it ignores all fitted parameters in C. That is, testckfold cross validates C using only the specified options and the predictor data to estimate the out-of-fold classification losses.
h = 0 indicates to not reject the null hypothesis that the two models have equal predictive accuracies. This result favors the simpler ensemble.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Examples of ways to compare models include:
Compare the accuracies of a simple classification model and a more complex model by passing the same set of predictor data.
Compare the accuracies of two different models using two different sets of predictors.
Perform various types of Feature Selection. For example, you can compare the accuracy of a model trained using a set of predictors to the accuracy of one trained on a subset or different set of predictors. You can arbitrarily choose the set of predictors, or use a feature selection technique like PCA or sequential feature selection (see
pcaandsequentialfs).
If both of these statements are true, then you can omit supplying
Y.Consequently,
testckfolduses the common response variable in the tables.One way to perform cost-insensitive feature selection is:
Create a classification model template that characterizes the first classification model (
C1).Create a classification model template that characterizes the second classification model (
C2).Specify two predictor data sets. For example, specify
X1as the full predictor set andX2as a reduced set.Enter
testckfold(C1,C2,X1,X2,Y,'Alternative','less'). Iftestckfoldreturns1, then there is enough evidence to suggest that the classification model that uses fewer predictors performs better than the model that uses the full predictor set.
Alternatively, you can assess whether there is a significant difference between the accuracies of the two models. To perform this assessment, remove the
'Alternative','less'specification in step 4.testckfoldconducts a two-sided test, andh = 0indicates that there is not enough evidence to suggest a difference in the accuracy of the two models.The tests are appropriate for the misclassification rate classification loss, but you can specify other loss functions (see
LossFun). The key assumptions are that the estimated classification losses are independent and normally distributed with mean 0 and finite common variance under the two-sided null hypothesis. Classification losses other than the misclassification rate can violate this assumption.Highly discrete data, imbalanced classes, and highly imbalanced cost matrices can violate the normality assumption of classification loss differences.
Algorithms
If you specify to conduct the 10-by-10 repeated cross-validation t test
using 'Test','10x10t', then testckfold uses
10 degrees of freedom for the t distribution to
find the critical region and estimate the p-value.
For more details, see [2] and [3].
Alternatives
Use testcholdout:
For test sets with larger sample sizes
To implement variants of the McNemar test to compare two classification model accuracies
For cost-sensitive testing using a chi-square or likelihood ratio test. The chi-square test uses
quadprog(Optimization Toolbox), which requires an Optimization Toolbox™ license.
References
[1] Alpaydin, E. “Combined 5 x 2 CV F Test for Comparing Supervised Classification Learning Algorithms.” Neural Computation, Vol. 11, No. 8, 1999, pp. 1885–1992.
[2] Bouckaert. R. “Choosing Between Two Learning Algorithms Based on Calibrated Tests.” International Conference on Machine Learning, 2003, pp. 51–58.
[3] Bouckaert, R., and E. Frank. “Evaluating the Replicability of Significance Tests for Comparing Learning Algorithms.” Advances in Knowledge Discovery and Data Mining, 8th Pacific-Asia Conference, 2004, pp. 3–12.
[4] Dietterich, T. “Approximate statistical tests for comparing supervised classification learning algorithms.” Neural Computation, Vol. 10, No. 7, 1998, pp. 1895–1923.
[5] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, 2nd Ed. New York: Springer, 2008.
Extended Capabilities
Version History
Introduced in R2015aSee Also
testcholdout | templateECOC | templateEnsemble | templateDiscriminant | templateTree | templateSVM | templateNaiveBayes | templateKNN