Object Detection Using YOLO v3 Deep Learning
This example shows how to detect objects in images using a You Only Look Once version 3 (YOLO v3) deep learning network. In this example, you will
Configure a dataset for training and testing of YOLO v3 object detection network. You will also perform data augmentation on the training dataset to improve the network efficiency.
Create a YOLO v3 object detector by using the
yolov3ObjectDetectorfunction and train the detector by using thetrainYOLOv3ObjectDetectorfunction.
This example also provides a pretrained YOLO v3 object detector to use for detecting vehicles in an image. The pretrained network uses squeezenet as the backbone network and is trained on a vehicle dataset. For more information about YOLO v3 object detection network, see Getting Started with YOLO v3.
Load Data
This example uses a small labeled data set that contains 295 images. Many of these images come from the Caltech Cars 1999 and 2001 data sets, created by Pietro Perona and used with permission. Each image contains one or two labeled instances of a vehicle. A small data set is useful for exploring the YOLO v3 training procedure, but in practice, more labeled images are needed to train a robust network.
Unzip the vehicle images and load the vehicle ground truth data.
unzip vehicleDatasetImages.zip data = load("vehicleDatasetGroundTruth.mat"); vehicleDataset = data.vehicleDataset;
The vehicle data is stored in a two-column table. The first column contain the image file paths and the second column contain the bounding boxes.
Display first few rows of the data set.
vehicleDataset(1:4,:)
ans=4×2 table
'vehicleImages/image_00001.jpg' [220,136,35,28]
'vehicleImages/image_00002.jpg' [175,126,61,45]
'vehicleImages/image_00003.jpg' [108,120,45,33]
'vehicleImages/image_00004.jpg' [124,112,38,36]
Add the full path to the local vehicle data folder.
vehicleDataset.imageFilename = fullfile(pwd,vehicleDataset.imageFilename);
Split the dataset into training, validation, and test sets. Select 60% of the data for training, 10% for validation, and the rest for testing the trained detector.
rng(0); shuffledIndices = randperm(height(vehicleDataset)); idx = floor(0.6 * length(shuffledIndices) ); trainingIdx = 1:idx; trainingDataTbl = vehicleDataset(shuffledIndices(trainingIdx),:); validationIdx = idx+1 : idx + 1 + floor(0.1 * length(shuffledIndices) ); validationDataTbl = vehicleDataset(shuffledIndices(validationIdx),:); testIdx = validationIdx(end)+1 : length(shuffledIndices); testDataTbl = vehicleDataset(shuffledIndices(testIdx),:);
Use the imageDatastore and boxLabelDatastore objects to create datastores for loading the image and label data during training and evaluation.
imdsTrain = imageDatastore(trainingDataTbl{:,"imageFilename"});
bldsTrain = boxLabelDatastore(trainingDataTbl(:,"vehicle"));
imdsValidation = imageDatastore(validationDataTbl{:,"imageFilename"});
bldsValidation = boxLabelDatastore(validationDataTbl(:,"vehicle"));
imdsTest = imageDatastore(testDataTbl{:,"imageFilename"});
bldsTest = boxLabelDatastore(testDataTbl(:,"vehicle"));Combine the image and box label datastores.
trainingData = combine(imdsTrain,bldsTrain); validationData = combine(imdsValidation,bldsValidation); testData = combine(imdsTest,bldsTest);
Use the validateInputData supporting function which is attached to this example to detect invalid input data, such as:
Images with invalid formats or which contain NaNs
Bounding boxes containing zeros/NaNs/Infs/empty
Missing/non-categorical labels
The values of the bounding boxes should be finite, positive, non-fractional, non-NaN, and within the image boundary with a positive height and width. Any invalid input data must either be discarded or fixed for proper training.
validateInputData(trainingData); validateInputData(validationData); validateInputData(testData);
Data Augmentation
Data augmentation is used to improve network accuracy by randomly transforming the original data during training. By using data augmentation, you can add more variety to the training data without actually having to increase the number of labeled training samples.
Use the transform function to apply custom data augmentations to the training data. The augmentData helper function applies the following augmentations to the input data.
Color jitter augmentation in HSV space
Random horizontal flip
Random scaling by 10 percent
augmentedTrainingData = transform(trainingData,@augmentData);
Read the same image four times and display the augmented training data.
augmentedData = cell(4,1); for k = 1:4 data = read(augmentedTrainingData); augmentedData{k} = insertShape(data{1,1},"Rectangle",data{1,2}); reset(augmentedTrainingData); end figure montage(augmentedData,BorderSize=10)

reset(augmentedTrainingData);
Define YOLO v3 Object Detector
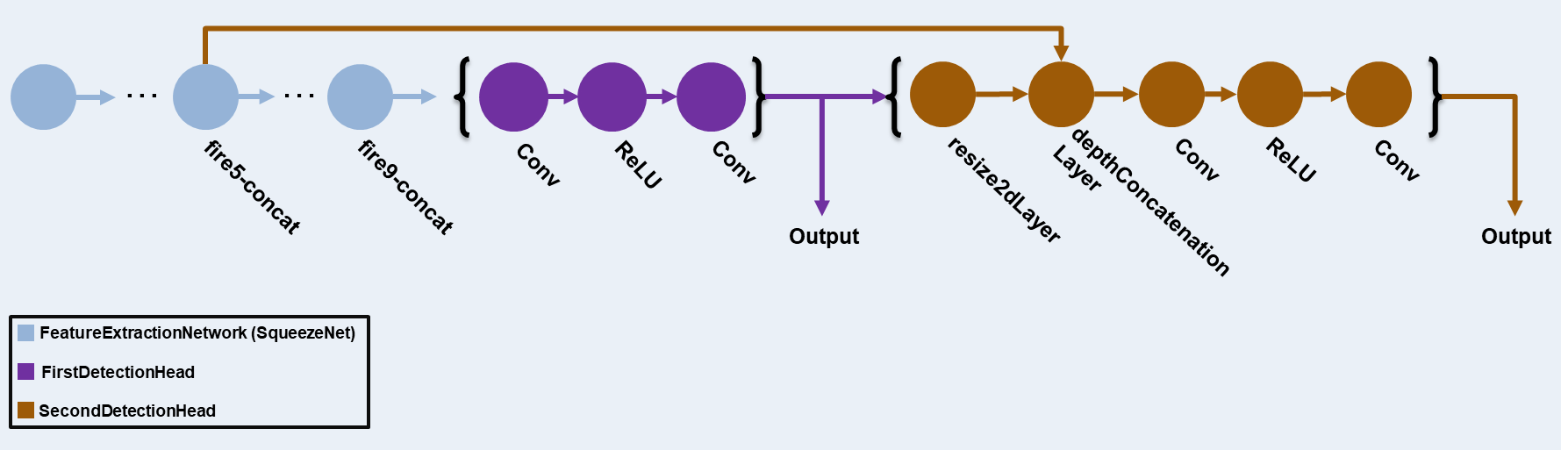
The YOLO v3 detector in this example is based on SqueezeNet, and uses the feature extraction network in SqueezeNet with the addition of two detection heads at the end. The second detection head is twice the size of the first detection head, so it is better able to detect small objects. Note that you can specify any number of detection heads of different sizes based on the size of the objects that you want to detect. The YOLO v3 detector uses anchor boxes estimated using training data to have better initial priors corresponding to the type of data set and to help the detector learn to predict the boxes accurately. For information about anchor boxes, see Anchor Boxes for Object Detection.
The YOLO v3 network present in the YOLO v3 detector is illustrated in the following diagram.
You can use Deep Network Designer (Deep Learning Toolbox) to create the network shown in the diagram.
Specify the network input size. When choosing the network input size, consider the minimum size required to run the network itself, the size of the training images, and the computational cost incurred by processing data at the selected size. When feasible, choose a network input size that is close to the size of the training image and larger than the input size required for the network. To reduce the computational cost of running the example, specify a network input size of [227 227 3].
networkInputSize = [227 227 3];
First, use the transform function to preprocess the training data for computing the anchor boxes, as the training images used in this example are bigger than 227-by-227 and vary in size. Specify the number of anchors as 6 to achieve a good tradeoff between number of anchors and mean intersection-over-union (IoU). Use the estimateAnchorBoxes function to estimate the number of anchor boxes and their mean IoU value. For details on estimating anchor boxes, see Estimate Anchor Boxes from Training Data. In case of using a pretrained YOLOv3 object detector, the anchor boxes calculated on that particular training dataset need to be specified. Note that the estimation process is not deterministic. To prevent the estimated anchor boxes from changing while tuning other hyperparameters, set the random seed prior to estimation using the rng function.
rng(0) trainingDataForEstimation = transform(trainingData,@(data)preprocessData(data,networkInputSize)); numAnchors = 6; [anchors,meanIoU] = estimateAnchorBoxes(trainingDataForEstimation,numAnchors)
anchors = 6×2
42 37
160 130
96 92
141 123
35 25
69 66
meanIoU = 0.8430
Specify anchorBoxes to use in both the detection heads. anchorBoxes is a cell array of [Mx1], where M denotes the number of detection heads. Each detection head consists of a [Nx2] matrix of anchors, where N is the number of anchors to use. Select anchorBoxes for each detection head based on the feature map size. Use larger anchors at lower scale and smaller anchors at higher scale. To do so, sort the anchors with the larger anchor boxes first and assign the first three to the first detection head and the next three to the second detection head.
area = anchors(:,1).*anchors(:,2);
[~,idx] = sort(area,"descend");
anchors = anchors(idx,:);
anchorBoxes = {anchors(1:3,:)
anchors(4:6,:)
};Load the SqueezeNet network pretrained on the ImageNet data set and then specify the class names. You can also choose to load a different pretrained network trained on COCO data set such as tiny-yolov3-coco or darknet53-coco, or one trained on the ImageNet data set such as MobileNet-v2 or ResNet-18. YOLO v3 performs better and trains faster when you use a pretrained network.
baseNetwork = imagePretrainedNetwork("squeezenet");
classNames = trainingDataTbl.Properties.VariableNames(2:end);Next, create the yolov3ObjectDetector object by adding the detection network source. Choosing the optimal detection network source requires trial and error, and you can use analyzeNetwork to find the names of potential detection network source within a network. Specify the DetectionNetworkSource input argument as the fire9-concat and fire5-concat layers.
yolov3Detector = yolov3ObjectDetector(baseNetwork,classNames,anchorBoxes, ... DetectionNetworkSource=["fire9-concat","fire5-concat"],InputSize=networkInputSize);
Alternatively, instead of the network created above using SqueezeNet, you can use other pretrained YOLO v3 architectures trained using larger datasets like MS-COCO to train the detector on custom object detection task. To perform transfer learning, modify the classNames and anchorBoxes name-value argument values.
Specify Training Options
Use trainingOptions to specify network training options. Train the object detector using the Adam solver for 80 epochs with a constant learning rate 0.001. Specify the ValidationData name-value argument as the validation data and the ValidationFrequency name-value argumenExecutionEnvironmentt as 1000. To validate the data more often, you can reduce the ValidationFrequency which also increases the training time. Specify the Metrics argument using the mAPObjectDetectionMetric function to monitor the mean average precision (mAP) of the detector during training. To save the partially trained detector during the training process, specify the CheckpointPath name-value argument as a temporary location, tempdir. If training is interrupted, for instance by a power outage or system failure, you can resume training from the saved checkpoint.
options = trainingOptions("adam", ... GradientDecayFactor=0.9, ... SquaredGradientDecayFactor=0.999, ... InitialLearnRate=0.001, ... LearnRateSchedule="none", ... MiniBatchSize=8, ... L2Regularization=0.0005, ... MaxEpochs=80, ... DispatchInBackground=true, ... ResetInputNormalization=true, ... Shuffle="every-epoch", ... VerboseFrequency=20, ... ValidationFrequency=1000, ... CheckpointPath=tempdir, ... ValidationData=validationData, ... Metrics = mAPObjectDetectionMetric(Name="map50"));
Train YOLO v3 Object Detector
Use the trainYOLOv3ObjectDetector function to train the YOLO v3 object detector. Instead of training the network, you can also use a pretrained YOLO v3 object detector.
Download a pretrained network by using the helper function downloadPretrainedYOLOv3Detector. If you want to train the network with a new set of data, set the doTraining variable to true.
doTraining = false; if doTraining % Train the YOLO v3 detector. [yolov3Detector,info] = trainYOLOv3ObjectDetector(augmentedTrainingData,yolov3Detector,options); else % Load pretrained detector for the example. yolov3Detector = downloadPretrainedYOLOv3Detector(); end
Evaluate Detector Performance
Run the detector on all the test images. Set the detection threshold to a low value to detect as many objects as possible. This helps you evaluate the detector precision across the full range of recall values.
results = detect(yolov3Detector,testData,MiniBatchSize=8,Threshold=0.01);
Visualize and Evaluate Performance Interactively
You can interactively visualize and evaluate the performance of the detector against the ground truth using the Object Detector Analyzer app. The app runs the detector on the test set and computes metrics such as AP and mAP, plots precision-recall curves, and displays the detections on each image in the test set. You can visualize ground truth data alongside correct and incorrect detector predictions and quickly navigate to images where the detector made the most mistakes to better understand the performance. To launch the app, use the objectDetectorAnalyzer function.
objectDetectorAnalyzer(results,testData)
Compute Performance Metrics
Compute the object detection performance metrics on the test set detection results using the evaluateObjectDetection function. To learn more about performace metrics, see Evaluate Object Detector Performance.
metrics = evaluateObjectDetection(results,testData);
The average precision (AP) provides a single number that incorporates the ability of the detector to make correct classifications (precision) and the ability of the detector to find all relevant objects (recall). The precision-recall (PR) curve shows how precise a detector is at varying levels of recall. Ideally, the precision is 1 at all recall levels. Plot the PR curve and also display the average precision.
[precision,recall] = precisionRecall(metrics);
AP = averagePrecision(metrics);
figure
plot(recall{:},precision{:})
xlabel("Recall")
ylabel("Precision")
grid on
title("Average Precision = "+AP)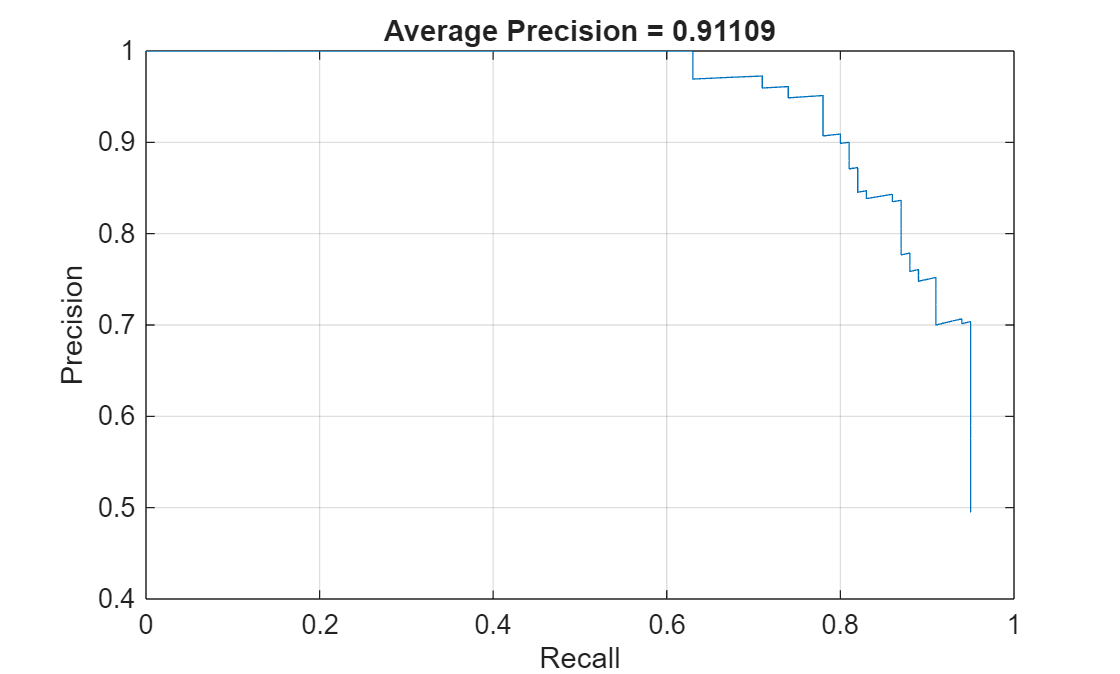
Detect Objects Using YOLO v3
Perform inference on a test image using the trained YOLO v3 object detector.
Read the test datastore, and select a sample image.
data = read(testData);
I = data{1};Predict the mask, labels, and confidence scores for each object using the detect object function.
[bboxes,scores,labels] = detect(yolov3Detector,I);
Display the object annotations overlaid on the image using the insertObjectAnnotation function.
I = insertObjectAnnotation(I,"rectangle",bboxes,scores);
figure
imshow(I)
Supporting Functions
augmentData
function data = augmentData(A) % Apply random horizontal flipping, and random X/Y scaling. Boxes that get % scaled outside the bounds are clipped if the overlap is above 0.25. Also, % jitter image color. data = cell(size(A)); for ii = 1:size(A,1) I = A{ii,1}; bboxes = A{ii,2}; labels = A{ii,3}; sz = size(I); if numel(sz) == 3 && sz(3) == 3 I = jitterColorHSV(I, ... Contrast=0, ... Hue=0.1, ... Saturation=0.2, ... Brightness=0.2); end % Randomly flip image. tform = randomAffine2d(XReflection=true,Scale=[1 1.1]); rout = affineOutputView(sz,tform,BoundsStyle="centerOutput"); I = imwarp(I,tform,OutputView=rout); % Apply same transform to boxes. [bboxes,indices] = bboxwarp(bboxes,tform,rout,OverlapThreshold=0.25); bboxes = round(bboxes); labels = labels(indices); % Return original data only when all boxes are removed by warping. if isempty(indices) data(ii,:) = A(ii,:); else data(ii,:) = {I,bboxes,labels}; end end end
preprocessData
function data = preprocessData(data,targetSize) % Resize the images and scale the pixels to between 0 and 1. Also scale the % corresponding bounding boxes. for ii = 1:size(data,1) I = data{ii,1}; imgSize = size(I); % Convert an input image with single channel to 3 channels. if numel(imgSize) < 3 I = repmat(I,1,1,3); end bboxes = data{ii,2}; I = im2single(imresize(I,targetSize(1:2))); scale = targetSize(1:2)./imgSize(1:2); bboxes = bboxresize(bboxes,scale); data(ii,1:2) = {I,bboxes}; end end
downloadPretrainedYOLOv3Detector
function detector = downloadPretrainedYOLOv3Detector() % Download a pretrained yolov3 detector. if ~exist("yolov3SqueezeNetVehicleExample_21aSPKG.mat","file") if ~exist("yolov3SqueezeNetVehicleExample_21aSPKG.zip","file") disp("Downloading pretrained detector..."); pretrainedURL = "https://ssd.mathworks.com/supportfiles/vision/data/yolov3SqueezeNetVehicleExample_21aSPKG.zip"; websave("yolov3SqueezeNetVehicleExample_21aSPKG.zip",pretrainedURL); end unzip("yolov3SqueezeNetVehicleExample_21aSPKG.zip"); end pretrained = load("yolov3SqueezeNetVehicleExample_21aSPKG.mat"); detector = pretrained.detector; end
References
[1] Redmon, Joseph, and Ali Farhadi. “YOLOv3: An Incremental Improvement.” Preprint, submitted April 8, 2018. https://arxiv.org/abs/1804.02767.
See Also
Apps
Functions
preprocess|forward|yolov3ObjectDetector|analyzeNetwork(Deep Learning Toolbox) |evaluateObjectDetection|yoloxObjectDetector
Topics
- Getting Started with YOLO v3
- Evaluate Object Detector Performance
- Get Started with Object Detector Analyzer
- Object Detection in Large Satellite Imagery Using Deep Learning
- Choose an Object Detector
- Get Started with Object Detection Using Deep Learning
- Getting Started with YOLOX for Object Detection
- Object Detection Using YOLO v2 Deep Learning