Estimer un modèle de processus
Estimer un modèle de processus en temps continu pour un système à entrée unique et à sortie unique (SISO) dans le domaine temporel ou fréquentiel dans le Live Editor
Description
La tâche Estimate Process Model (Estimer un modèle de processus) vous permet d’estimer et de valider interactivement un modèle de processus pour les systèmes SISO. Vous pouvez définir et faire varier la structure du modèle et spécifier des paramètres optionnels tels que le traitement des conditions initiales et les méthodes de recherche. La tâche génère automatiquement un code MATLAB® pour votre live script. Pour plus d’informations sur les tâches du Live Editor en général, consultez Add Interactive Tasks to a Live Script.
Les modèles de processus sont de simples fonctions de transfert en temps continu qui décrivent la dynamique de système linéaire. Les éléments de modèle de processus comprennent le gain statique, les constantes de temps, les retards de temps, l’intégrateur et le zéro de processus.
Les modèles de processus sont populaires lorsqu’il s’agit de décrire la dynamique des systèmes dans de nombreux secteurs. Ils peuvent s’appliquer à divers environnements de production. Ces modèles ont pour avantages d’être simples et de prendre en charge l’estimation des retards de transport. En outre, les coefficients du modèle sont faciles à interpréter en tant que pôles et zéros. Pour plus d’informations sur l’estimation d’un modèle de processus, consultez What Is a Process Model?
La tâche Estimate Process Model est indépendante de l’application System Identification plus générale. Utilisez l’application System Identification quand vous voulez calculer et comparer des estimations pour plusieurs structures de modèle.
Pour démarrer, chargez des données expérimentales contenant des données d’entrée et de sortie sur votre espace de travail MATLAB, puis importez ces données dans la tâche. Sélectionnez ensuite une structure de modèle à estimer. La tâche vous donne des contrôles et des tracés que vous pouvez expérimenter avec différentes structures de modèle afin de comparer la qualité de l’ajustement de la sortie de chaque modèle aux mesures.
Ouvrir la tâche
Pour ajouter la tâche Estimate Process Model à un live script dans MATLAB Editor :
Dans l’onglet Live Editor, sélectionnez Task > Estimate Process Model.
Dans un bloc de code de votre script, tapez un mot clé utile, tel que
processouestimate. SélectionnezEstimate Process Modelparmi les complétions de commande suggérées.
Exemples
Utilisez la tâche Live Editor Estimate Process Model pour estimer un modèle de processus et comparer la sortie du modèle aux données de mesure.
Configurer des données
Chargez les données de mesure tt1 sur votre espace de travail MATLAB. tt1 est une timetable qui contient une variable d’entrée u et une variable de sortie y.
load sdata1 tt1
Importer les données dans la tâche
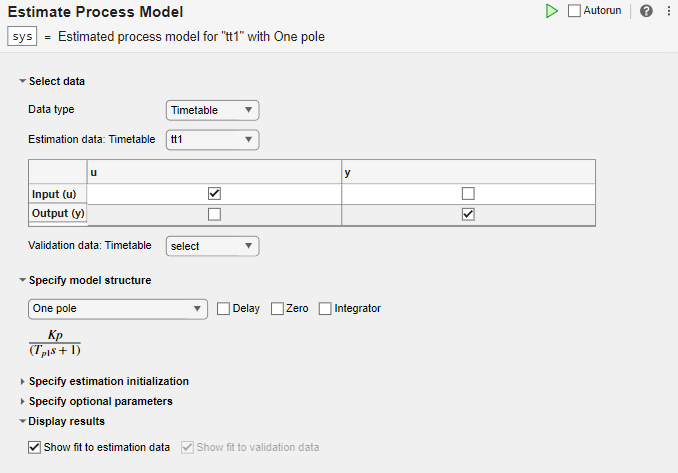
Dans la section Select data, définissez le Data type sur Timetable et définissez Estimation data sur tt1.

La tâche affiche un tableau contenant les noms de variables d’entrée et de sortie tt1.
Estimer le modèle avec les paramètres par défaut
Examinez la structure du modèle et les paramètres optionnels.

Dans la section Specify model structure, l’option par défaut est One Pole sans délai, zéro ou intégrateur. Les équations sous les paramètres de cette section affichent la structure spécifiée.
Dans la section Specify estimation initialization, les paramètres d’initialisation correspondant aux paramètres de votre structure de modèle vous permettent de définir des points de départ pour l’estimation. Si vous sélectionnez Fix, le paramètre reste fixé à la valeur que vous spécifiez. Pour cet exemple, ne spécifiez pas d’initialisation. La tâche utilise donc des valeurs par défaut pour les points de départ.
Dans la section Specify optional parameters, les options par défaut pour l’estimation de processus sont définies.
Exécutez la tâche depuis l’onglet Live Editor en cliquant sur la flèche verte. Vous pouvez également sélectionner Autorun pour exécuter la tâche automatiquement à chaque fois que vous mettez à jour un paramètre.
![]()
Un tracé affiche les données d’estimation, la sortie du modèle estimée et le pourcentage d’ajustement.

Expérimenter avec différentes configuration de paramètres
Expérimentez avec différentes configurations de paramètres et observez comment cela influe sur l’ajustement.
Par exemple, ajoutez un retard à la structure One Pole et exécutez la tâche.


L’ajustement d’estimation s’améliore, bien que le pourcentage d’ajustement reste sous 50 %.
Essayez une structure de modèle différente. Dans Specify model structure, sélectionnez Underdamped Pair sans retard et exécutez la tâche.


Les résultats d’ajustement s’améliorent considérablement.
Générer le code
Pour afficher le code généré par la tâche, cliquez sur ![]() au bas de la section des paramètres. Le code que vous voyez montre la configuration actuelle des paramètres de la tâche.
au bas de la section des paramètres. Le code que vous voyez montre la configuration actuelle des paramètres de la tâche.

Utilisez des données d’estimation et de validation séparées afin que vous puissiez valider le modèle de processus estimé.
Configurer des données
Chargez les données de mesure sdata1 sur votre espace de travail MATLAB et examinez leur contenu.
load sdata1 umat1 ymat1 Ts
Divisez les données en deux jeux, une moitié pour l’estimation et l’autre pour la validation. Le jeu de données original avait 300 échantillons, donc chaque nouveau jeu de données doit avoir 150 échantillons.
u_est = umat1(1:150); u_val = umat1(151:300); y_est = ymat1(1:150); y_val = ymat1(151:300); Ts
Ts = 0.1000
Importer les données dans la tâche
Dans la section Select data, définissez le Data type sur « Numeric ». Spécifiez le pas d’échantillonnage sur 0.1 seconde. Sélectionnez les jeux de données appropriés pour l’estimation et la validation.

Estimer et valider le modèle
L’exemple Estimer un modèle de processus avec la tâche Live Editor obtient les meilleurs résultats avec la structure de modèle Underdamped Pair. Choisissez la même option pour cet exemple.

Exécutez la tâche. Exécuter la tâche crée deux tracés. Le premier tracé montre les résultats d’estimation et le deuxième tracé montre les résultats de validation.

L’ajustement aux données d’estimation est un peu moins bon que dans Estimer un modèle de processus avec la tâche Live Editor. L’estimation dans cet exemple ne possède que la moitié des données avec lesquelles estimer le modèle. L’ajustement aux données de validation, qui représente la qualité du modèle plus généralement, est meilleur que l’ajustement aux données d’estimation.