matchScansLine
Estimer la pose entre deux balayages laser à l'aide des caractéristiques linéaires
Syntaxe
Description
relpose = matchScansLine(currScan,refScan,initialRelPose)initialRelPose.
[___] = matchScansLine(___, spécifie les options en utilisant un ou plusieurs arguments de paire nom-valeur.Name,Value)
Exemples
Cet exemple montre comment utiliser la fonction matchScansLine pour estimer la pose relative entre les analyses lidar à partir d'une estimation initiale. Les caractéristiques linéaires identifiées sont visualisées pour montrer comment l'algorithme de correspondance de balayage associe les caractéristiques entre les balayages.
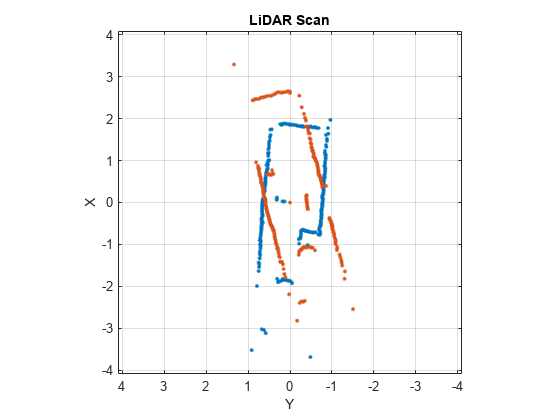
Chargez une paire de scans lidar. Le fichier .mat contient également une estimation initiale de la différence de pose relative, initGuess, qui pourrait être basée sur l'odométrie ou d'autres données de capteur.
load tb3_scanPair.mat plot(s1) hold on plot(s2) hold off
Définissez les paramètres d’extraction et d’association des entités linéaires. Le bruit des données lidar détermine le seuil de lissage, qui définit le moment où un saut de ligne se produit pour une entité linéaire spécifique. Augmentez cette valeur pour obtenir des données lidar plus bruitées. L'échelle de compatibilité détermine quand les fonctionnalités sont considérées comme des correspondances. Augmentez cette valeur pour des restrictions plus souples sur les paramètres des entités linéaires.
smoothnessThresh = 0.2; compatibilityScale = 0.002;
Appelez matchScansLine avec la supposition initiale donnée et d'autres paramètres spécifiés sous forme de paires nom-valeur. La fonction calcule les caractéristiques linéaires pour chaque numérisation, tente de les faire correspondre et utilise une estimation globale pour obtenir la différence de pose.
[relPose, stats, debugInfo] = matchScansLine(s2, s1, initGuess, ... 'SmoothnessThreshold', smoothnessThresh, ... 'CompatibilityScale', compatibilityScale);
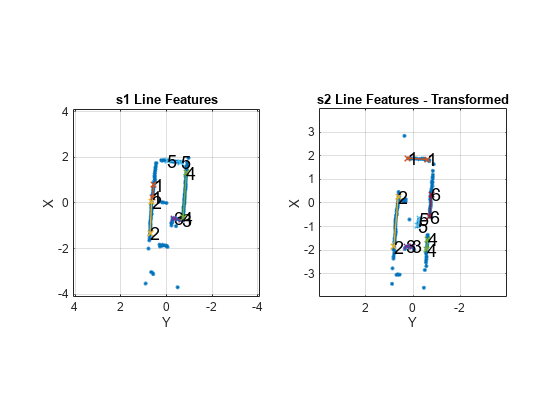
Après avoir fait correspondre les analyses, la sortie debugInfo vous donne des informations sur les paramètres des caractéristiques de ligne détectées, [rho alpha], et l'hypothèse selon laquelle les caractéristiques correspondent entre les analyses.
debugInfo.MatchHypothesis indique que les première, deuxième et sixième fonctionnalités de ligne de s1 correspondent aux cinquième, deuxième et quatrième fonctionnalités de s2.
debugInfo.MatchHypothesis
ans = 1×6
5 2 0 0 0 4
La fonction d'assistance fournie trace ces deux analyses et les caractéristiques extraites avec des étiquettes. s2 est transformé pour être dans le même cadre en fonction de la supposition initiale de la pose relative.
exampleHelperShowLineFeaturesInScan(s1, s2, debugInfo, initGuess);
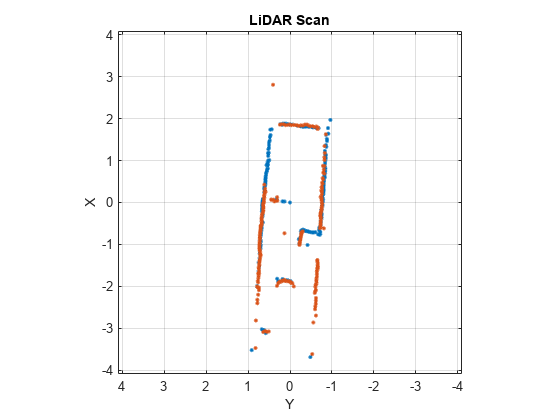
Utilisez la pose relative estimée de matchScansLine pour transformer s2. Ensuite, tracez les deux analyses pour montrer que la différence de pose relative est précise et les analyses se superposent pour montrer le même environnement.
s2t = transformScan(s2,relPose); clf plot(s1) hold on plot(s2t) hold off
Arguments d'entrée
Arguments nom-valeur
Arguments de sortie
Références
[1] Neira, J., and J.d. Tardos. “Data Association in Stochastic Mapping Using the Joint Compatibility Test.” IEEE Transactions on Robotics and Automation 17, no. 6 (2001): 890–97. https://doi.org/10.1109/70.976019.
[2] Shen, Xiaotong, Emilio Frazzoli, Daniela Rus, and Marcelo H. Ang. “Fast Joint Compatibility Branch and Bound for Feature Cloud Matching.” 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2016. https://doi.org/10.1109/iros.2016.7759281.
Historique des versions
Introduit dans R2020a