nmeaParser
Analyser les données à partir de phrases NMEA standard et spécifiques au fabricant envoyées à partir d'appareils électroniques marins
Description
Le nmeaParser System object™ analyse les données de toutes les phrases NMEA (National Marine Electronics Association). Les phrases qui nécessitent une analyse des données peuvent être n'importe quelle phrase standard conforme aux spécifications NMEA 0183® (qui sont envoyées à partir d'un récepteur GNSS (Global Navigation Satellite System)), ou d'autres phrases spécifiques au fabricant approuvées par le NMEA (qui sont envoyés par d'autres appareils électroniques marins).
Le nmeaParser System object fournit :
Prise en charge intégrée pour analyser les données envoyées par les récepteurs GNSS et identifiées par ces neuf types de messages NMEA : RMC, GGA, GSA, VTG, GLL, GST, ZDA, GSV et HDT
Configuration supplémentaire utilisant la paire nom-valeur
CustomSentencepour analyser les données NMEA de plusieurs catégories d'appareils, y compris les phrases spécifiques au fabricant de différents fabricants de matériel.
Pour analyser les données des phrases NMEA :
Créez l'objet
nmeaParseret définissez ses propriétés.Appelez l'objet avec des arguments, comme s'il s'agissait d'une fonction.
Pour en savoir plus sur le fonctionnement des objets système, voir What Are System Objects?
Le nmeaParser System object génère un tableau de structures correspondant aux valeurs extraites des phrases NMEA spécifiées.
Création
Syntaxe
Description
pnmea = nmeaParsernmeaParser System object, pnmea, avec des propriétés par défaut, qui extrait les données de ces messages standards NMEA : RMC, GGA et GSA. L'ordre des tableaux de structure dans les données de sortie extraites est également : RMC, GGA et GSA.
pnmea = nmeaParser("MessageIDs", 'msgID')nmeaParser System object, pnmea, qui extrait les données de l'un des neuf messages standards NMEA avec prise en charge intégrée, spécifiés à l'aide des ID de message. Spécifiez msgID comme "RMC", "GGA", "GSA", "GSV", "VTG", "GLL", "GST", "ZDA" et "HDT", ou une combinaison de ces identifiants (par exemple : ["VTG","GLL","HDT"]). L'ordre dans lequel vous spécifiez les ID de message détermine l'ordre des tableaux de structure dans les données de sortie extraites. La valeur par défaut est ["RMC","GGA","GSA"].
pnmea = nmeaParser("CustomSentence", {['CustomMessageId1','parserFunctionName1'],['CustomMessageId2','parserFunctionName2']})CustomSentence et renvoie un nmeaParser System object, pnmea, qui extrait les données de tout message NMEA personnalisé (soit un message NMEA standard, soit un message NMEA spécifique au fabricant), spécifié à l'aide des ID de message.
La paire nom-valeur CustomSentence accepte un cell array imbriqué où chaque élément est une paire de noms d'ID de message (soit le nom d'ID de message NMEA standard, soit l'ID de message spécifique au fabricant) et l'analyseur syntaxique correspondant (parser) défini par l'utilisateur, qui est créée en incluant la fonction extractNMEASentence dans un fichier de fonction. L'ordre dans lequel vous spécifiez les ID de message détermine l'ordre des tableaux de structure dans les données extraites en sortie
pnmea = nmeaParser("MessageIDs", {'msgID1','msgID2'},"CustomSentence", {['CustomMessageId1','parserFunctionName1'],['CustomMessageId2','parserFunctionName2']})nmeaParser System object, pnmea, qui extrait les données de deux des neuf standards NMEA messages avec prise en charge intégrée ainsi que des messages NMEA personnalisés que vous avez spécifiés à l'aide de la paire nom-valeur CustomSentence .
Arguments nom-valeur
Propriétés
Utilisation
Syntaxe
Description
[ analyse les données de neuf phrases NMEA standard avec prise en charge intégrée et renvoie un tableau de structures, où chaque structure correspond à un seul ID de message. La séquence que vous spécifiez pour les arguments de sortie doit être la même que celle que vous avez spécifiée pour les ID de message lors de la création du rmcData,ggaData,gsaData,vtgData,gllData,gstData,gsvData,zdaData,hdtData] = pnmea(rawData)nmeaParser System object.
[ analyse les données de deux phrases NMEA personnalisées (soit une phrase NMEA standard, soit une phrase NMEA spécifique au fabricant) et renvoie un tableau de structures, où chaque structure correspond à un seul ID de message. La séquence que vous spécifiez pour les arguments de sortie doit être la même que celle que vous avez spécifiée dans la paire nom-valeur customNmeaData1,customNmeaData2] = pnmea(rawData)CustomSentence lors de la création du nmeaParser System object.
Arguments en entrée
Arguments de sortie
Fonctions d'objet
Pour utiliser une fonction objet, spécifiez le System object comme premier argument d'entrée. Par exemple, pour libérer les ressources système d'un System object nommé obj, utilisez cette syntaxe :
release(obj)
Exemples
Extrayez les données de l'une des neuf phrases NMEA standard dans le cadre de la prise en charge intégrée à l'aide de la propriété MessageID. Les données NMEA sont obtenues à partir d'un récepteur GNSS.
Extraire les données de la phrase RMC
Créez un objet système nmeaParser en spécifiant l'ID de message comme RMC .
pnmea = nmeaParser("MessageID","RMC");
Fournissez la phrase RMC obtenue à partir du récepteur GNSS comme données d’entrée et d’extraction.
unparsedRMCLine='$GNRMC,143909.00,A,5107.0020216,N,11402.3294835,W,0.036,348.3,210307,0.0,E,A*31';
rmcData = pnmea(unparsedRMCLine)rmcData = struct with fields:
TalkerID: "GN"
MessageID: "RMC"
FixStatus: 'A'
Latitude: 51.1167
Longitude: -114.0388
GroundSpeed: 0.0185
TrueCourseAngle: 348.3000
UTCDateTime: 21-Mar-2007 14:39:09.000
MagneticVariation: 0
ModeIndicator: 'A'
NavigationStatus: "NA"
Status: 0
Extraire des données de plusieurs types de messages NMEA
Fournissez des phrases GGA, GSA et RMC comme entrée.
unparsedGGALine = ['$GPGGA,111357.771,5231.364,N,01324.240,E,1,12,1.0,0.0,M,0.0,M,,*69']; unparsedGSALine = ['$GPGSA,A,3,01,02,03,04,05,06,07,08,09,10,11,12,1.0,1.0,1.0*30']; unparsedRMCLine = ['$GPRMC,111357.771,A,5231.364,N,01324.240,E,10903,221.5,020620,000.0,W*44'];
Créez un tableau de chaînes de caractères pour inclure les trois phrases
rawNMEAData = [unparsedGGALine ,newline, unparsedGSALine ,newline, unparsedRMCLine]
rawNMEAData =
'$GPGGA,111357.771,5231.364,N,01324.240,E,1,12,1.0,0.0,M,0.0,M,,*69
$GPGSA,A,3,01,02,03,04,05,06,07,08,09,10,11,12,1.0,1.0,1.0*30
$GPRMC,111357.771,A,5231.364,N,01324.240,E,10903,221.5,020620,000.0,W*44'
Cependant, considérez que vous devez extraire les données uniquement des phrases GGA et GSA. Créez donc l'objet système nmeaParser 'pnmea' et spécifiez les ID de message 'GGA' et 'GSA' sous forme de tableau de chaînes de caractères.
pnmea=nmeaParser("MessageIDs",["GGA","GSA"]);
Spécifiez les arguments de sortie pour les trois phrases afin d'extraire les données sous forme de structures.
[ggaData,gsaData] = pnmea(rawNMEAData)
ggaData = struct with fields:
TalkerID: "GP"
MessageID: "GGA"
UTCTime: 11:13:57.771
Latitude: 52.5227
Longitude: 13.4040
QualityIndicator: 1
NumSatellitesInUse: 12
HDOP: 1
Altitude: 0
GeoidSeparation: 0
AgeOfDifferentialData: NaN
DifferentialReferenceStationID: NaN
Status: 0
gsaData = struct with fields:
TalkerID: "GP"
MessageID: "GSA"
Mode: "A"
FixType: 3
SatellitesIDNumber: [1 2 3 4 5 6 7 8 9 10 11 12]
PDOP: 1
VDOP: 1
HDOP: 1
SystemID: NaN
Status: 0
Le résultat ci-dessus montre que seules les phrases GGA et GSA sont extraites en fonction des ID de message spécifiés en entrée.
Fournissez une autre phrase GGA comme entrée supplémentaire et extrayez les données. Dans ce cas, vous n'avez pas besoin de modifier le System object car l'ID du message n'a pas changé.
unparsedGGALine1='$GNGGA,001043.00,4404.14036,N,12118.85961,W,1,12,0.98,1113.0,M,-21.3,M,,*47'unparsedGGALine1 = '$GNGGA,001043.00,4404.14036,N,12118.85961,W,1,12,0.98,1113.0,M,-21.3,M,,*47'
rawNMEAData = [unparsedGGALine ,newline, unparsedGSALine ,newline, unparsedGGALine1]
rawNMEAData =
'$GPGGA,111357.771,5231.364,N,01324.240,E,1,12,1.0,0.0,M,0.0,M,,*69
$GPGSA,A,3,01,02,03,04,05,06,07,08,09,10,11,12,1.0,1.0,1.0*30
$GNGGA,001043.00,4404.14036,N,12118.85961,W,1,12,0.98,1113.0,M,-21.3,M,,*47'
[ggaData,gsaData] = pnmea(rawNMEAData)
ggaData=2×1 struct array with fields:
TalkerID
MessageID
UTCTime
Latitude
Longitude
QualityIndicator
NumSatellitesInUse
HDOP
Altitude
GeoidSeparation
AgeOfDifferentialData
DifferentialReferenceStationID
Status
gsaData = struct with fields:
TalkerID: "GP"
MessageID: "GSA"
Mode: "A"
FixType: 3
SatellitesIDNumber: [1 2 3 4 5 6 7 8 9 10 11 12]
PDOP: 1
VDOP: 1
HDOP: 1
SystemID: NaN
Status: 0
Un statut 0 indique que les données ont été analysées avec succès.
Extraire les données de la phrase GSV
Créez un objet système nmeaParser en spécifiant l'ID de message comme GSV .
pnmea = nmeaParser("MessageID","GSV");
Fournissez la phrase GSV obtenue à partir du récepteur GNSS comme données d’entrée et d’extraction.
unparsedGSVLine='$GPGSV,3,3,10,32,69,205,41,46,47,215,39*79';
gsvData = pnmea(unparsedGSVLine)gsvData = struct with fields:
TalkerID: "GP"
MessageID: "GSV"
NumSentences: 3
SentenceNumber: 3
SatellitesInView: 10
SatelliteID: [32 46]
Elevation: [69 47]
Azimuth: [205 215]
SNR: [41 39]
SignalID: NaN
Status: 0
Extraire les données de plusieurs phrases GSV
Fournissez plusieurs phrases GSV en entrée.
unparsedGSVLine1 = '$GPGSV,3,1,10,01,,,31,03,28,325,40,10,,,33,12,20,047,30*70'; unparsedGSVLine2 = '$GPGSV,3,2,10,14,88,028,42,22,39,299,48,25,,,25,31,79,289,46*49'; unparsedGSVLine3 = '$GPGSV,3,3,10,32,69,205,41,46,47,215,39*79';
Créez un tableau de chaînes de caractères pour inclure les trois phrases.
CRLF = [char(13),newline]; unparsedGSVLines = [unparsedGSVLine1,CRLF, unparsedGSVLine2, CRLF, unparsedGSVLine3];
Créez l'objet système nmeaParser pnmea , spécifiez l'ID de message GSV et extrayez les données.
pnmea = nmeaParser("MessageIDs","GSV"); gsvData = pnmea(unparsedGSVLines)
gsvData=3×1 struct array with fields:
TalkerID
MessageID
NumSentences
SentenceNumber
SatellitesInView
SatelliteID
Elevation
Azimuth
SNR
SignalID
Status
Lire les données du journal NMEA
Lisez les données d'un exemple de journal NMEA, afin que les données puissent être analysées à l'aide de l'objet système nmeaParser.
L'exemple de fichier journal est nmeaLog.nmea, qui est inclus dans cet exemple.
f = fopen('nmeaLog.nmea'); unParsedNMEAdata = fread(f); pnmea = nmeaParser("MessageIDs",["RMC","GGA"]); [rmcStruct, ggaStruct] = pnmea(unParsedNMEAdata)
rmcStruct=9×1 struct array with fields:
TalkerID
MessageID
FixStatus
Latitude
Longitude
GroundSpeed
TrueCourseAngle
UTCDateTime
MagneticVariation
ModeIndicator
NavigationStatus
Status
ggaStruct=9×1 struct array with fields:
TalkerID
MessageID
UTCTime
Latitude
Longitude
QualityIndicator
NumSatellitesInUse
HDOP
Altitude
GeoidSeparation
AgeOfDifferentialData
DifferentialReferenceStationID
Status
Vous pouvez extraire des données de n'importe quelle phrase NMEA en utilisant la paire nom-valeur CustomSentence . Les données NMEA à analyser sont obtenues à partir d'appareils électroniques marins.
Identifiez la structure de la phrase NMEA et créez la fonction d'analyse syntaxique (parser)
Vous devez identifier la structure de la phrase NMEA, telle que définie dans la spécification, et utiliser ces informations pour définir la structure des données de sortie à utiliser dans l' System object nmeaParser.
Par exemple, considérons un exemple de phrase avec l'ID de message, SSS.

Après avoir identifié la structure, vous créez un fichier de fonction qui définit la fonction d'analyse syntaxique (parser), fsssParser. Dans le fichier de fonction, vous définissez les données en sortie sous la forme d'un tableau de structure dont les champs correspondent à la séquence telle qu'elle apparaît dans la spécification.
La Navigation Toolbox™ fournit une fonction préconfigurée facultative, extractNMEASentence, qui vérifie si la phrase est valide et convertit les champs de la phrase en tableau de chaînes de caractères. Vous pouvez appeler extractNMEASentence dans le fichier de fonction. Vous pouvez également utiliser n'importe quelle autre fonction à la place (qui génère un tableau de chaînes de caractères à partir de données non analysées), puis l'appeler dans le fichier de fonction.
L'image ci-dessous montre le fichier de fonction avec le code, en supposant que les champs disponibles dans la phrase SSS sont TalkerID, MessageID, UTC et LatitudeError. Reportez-vous aux commentaires supplémentaires pour plus de détails.
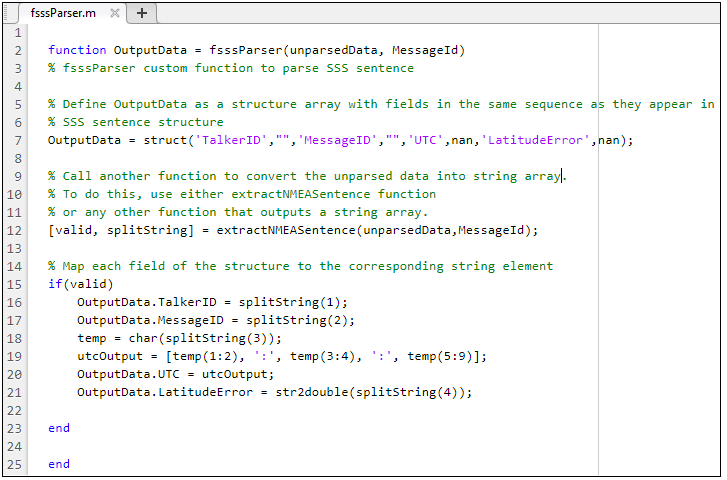
Dans l'exemple de fichier ci-dessus, vous définissez le mappage entre les champs du tableau de structure et les éléments du tableau de chaînes de caractères. Pour certains champs (par exemple, l'heure UTC), vous devrez peut-être définir un tableau de caractères pour mapper les champs.
Après avoir inclus le code MATLAB comme mentionné ci-dessus, enregistrez le fichier de fonction (fsssParser.m) dans le chemin MATLAB , afin de pouvoir l'appeler pour obtenir les données analysées en utilisant le nom-valeur CustomSentence. Paire de nmeaParserObjet System object.
Pour télécharger un autre exemple de fichier de fonction parserRMB.m utilisé dans cet exemple, cliquez sur Ouvrir Live Script . Il s'agit d'un fichier de fonctions spécifique aux champs d'une phrase RMB (mentionné dans la norme NMEA, version 4.1).
Extraire les données de la phrase RMB
Créez un objet système nmeaParser en utilisant la paire nom-valeur CustomSentence et en spécifiant l'ID du message comme RMB » et la fonction comme « parserRMB » (téléchargé à l'étape précédente).
pnmea = nmeaParser("CustomSentence",{["RMB","parserRMB"]});
Fournissez la phrase RMB obtenue à partir du récepteur GNSS comme données d’entrée et d’extraction.
unparsedRMBLine='$GPRMB,A,4.08,L,EGLL,EGLM,5130.02,N,00046.34,W,004.6,213.9,122.9,A*3D';
rmbData = pnmea(unparsedRMBLine)rmbData = «struct with fields:»
TalkerID: "GP"
MessageID: "RMB"
DataStatus: 'A'
CrossTrackError: 4.0800
DirectionToSteer: NaN
OriginWaypointID: NaN
DestinationWaypointID: NaN
DestinationWaypointLatitude: '5130.02 N'
DestinationWaypointLongitude: '00046.34 W'
RangeToDestination: 4.6000
BearingToDestination: 213.9000
DestinationClosingVelocity: 122.9000
ArrivalStatus: 'A'
ModeIndicator: "NA"
Status: 0
Extraire les données de plusieurs phrases RMB
Fournissez plusieurs phrases RMB comme entrée.
unparsedRMBLine1 = ['$GPRMB,A,0.66,L,003,004,4917.24,N,12309.57,W,001.3,052.5,000.5,V*20']; unparsedRMBLine2 = ['$GPRMB,A,4.08,L,EGLL,EGLM,5130.02,N,00046.34,W,004.6,213.9,122.9,A*3D'];
Créez un tableau de caractères pour inclure les deux phrases
rawNMEAData = [unparsedRMBLine1 ,newline, unparsedRMBLine2]
rawNMEAData =
'$GPRMB,A,0.66,L,003,004,4917.24,N,12309.57,W,001.3,052.5,000.5,V*20
$GPRMB,A,4.08,L,EGLL,EGLM,5130.02,N,00046.34,W,004.6,213.9,122.9,A*3D'
Spécifiez l'argument de sortie de la phrase RMB pour extraire les données.
[rmbData] = pnmea(rawNMEAData)
rmbData=«2×1 struct array with fields:»
TalkerID
MessageID
DataStatus
CrossTrackError
DirectionToSteer
OriginWaypointID
DestinationWaypointID
DestinationWaypointLatitude
DestinationWaypointLongitude
RangeToDestination
BearingToDestination
DestinationClosingVelocity
ArrivalStatus
ModeIndicator
Status
Extraire les données d'une phrase avec prise en charge intégrée (RMC) et phrase RMB
Créez un objet système nmeaParser en utilisant la propriété MessageID (pour analyser une phrase avec prise en charge intégrée - RMC) et en utilisant également la paire nom-valeur CustomSentence (en spécifiant l'ID du message comme "RMB" et la fonction comme "parserRMB" (créée dans une étape précédente)).
pnmea = nmeaParser("MessageID","RMC","CustomSentence",{["RMB","parserRMB"]});
Fournissez des phrases RMC et RMB comme entrée.
unparsedRMCLine1 = ['$GNRMC,143909.00,A,5107.0020216,N,11402.3294835,W,0.036,348.3,210307,0.0,E,A*31']; unparsedRMBLine2 = ['$GPRMB,A,4.08,L,EGLL,EGLM,5130.02,N,00046.34,W,004.6,213.9,122.9,A*3D'];
Créez un tableau de chaînes de caractères pour inclure les deux phrases
rawNMEAData = [unparsedRMCLine1 ,newline, unparsedRMBLine2]
rawNMEAData =
'$GNRMC,143909.00,A,5107.0020216,N,11402.3294835,W,0.036,348.3,210307,0.0,E,A*31
$GPRMB,A,4.08,L,EGLL,EGLM,5130.02,N,00046.34,W,004.6,213.9,122.9,A*3D'
Spécifiez l'argument de sortie de la phrase RMB pour extraire les données.
[rmcdata,rmbData] = pnmea(rawNMEAData)
rmcdata = «struct with fields:»
TalkerID: "GN"
MessageID: "RMC"
FixStatus: 'A'
Latitude: 51.1167
Longitude: -114.0388
GroundSpeed: 0.0185
TrueCourseAngle: 348.3000
UTCDateTime: 21-Mar-2007 14:39:09.000
MagneticVariation: 0
ModeIndicator: 'A'
NavigationStatus: "NA"
Status: 0
rmbData = «struct with fields:»
TalkerID: "GP"
MessageID: "RMB"
DataStatus: 'A'
CrossTrackError: 4.0800
DirectionToSteer: NaN
OriginWaypointID: NaN
DestinationWaypointID: NaN
DestinationWaypointLatitude: '5130.02 N'
DestinationWaypointLongitude: '00046.34 W'
RangeToDestination: 4.6000
BearingToDestination: 213.9000
DestinationClosingVelocity: 122.9000
ArrivalStatus: 'A'
ModeIndicator: "NA"
Status: 0
Identifiez la structure de la phrase spécifique au fabricant et créez un fichier de fonction avec la fonction d'analyse syntaxique (parser)
La structure de la phrase NMEA à analyser est disponible dans les spécifications de l'appareil auprès du fabricant. Vous devez identifier la structure et utiliser les informations pour définir la structure des données de sortie à utiliser dans l' System object nmeaParser.
Par exemple, la structure de la phrase NMEA d'un fabricant de matériel peut ressembler à ceci :
$PMMCZ,hhmmss.ss,Latitude,N,Longitude,E,NavSatellite,DR*hh<CR><LF>Ici, P indique que la phrase est spécifique au fabricant, MMC est le code mnémonique du fabricant et Z est le type de phrase. Chaque champ indique ensuite une donnée spécifique (position, vitesse, temps, etc.). Certains fabricants utilisent deux caractères pour le type de phrase, suivis des champs de données.
Après avoir identifié la structure, créez la fonction d'analyse syntaxique (parser),
parserMMCZ, en utilisant la fonction facultativeextractNMEASentence, comme indiqué ci-dessous (vous pouvez également utiliser d'autres fonctions pour extraire les données non analysées vers chaînes, au lieu deextractNMEASentence).function OutputData = parserMMCZ(unparsedData, MessageID) OutputData = struct("MessageID",MessageID,... "UTC","NA",... "Latitude",NaN,... "Longitude",NaN,... "NavigationSatellites",NaN,... "Status",uint8(1)); [isValid, splitString] = extractNMEASentence(unparsedData, MessageID); if(isValid) OutputData.MessageID = splitString(1); temp = char(splitString(2)); utcOutput = [temp(1:2), ':', temp(3:4), ':', temp(5:6)]; OutputData.UTC = utcOutput; OutputData.Latitude = str2double(splitString{3}); OutputData.Longitude = str2double(splitString{5}); OutputData.NavigationSatellites = str2double(splitString{7}); OutputData.Status = uint8(0); end end
Enregistrez
parserMMCZ.mdans le chemin MATLAB .Extraire les données de la phrase spécifique au fabricant
Créez un objet système
nmeaParseren utilisant la paire nom-valeurCustomSentenceet en spécifiant l'ID du message comme "MMCZ" et la fonction comme "parserMMCZ" (créée dans le précédent étape).pnmea = nmeaParser("CustomSentence",{["MMCZ","parserMMCZ"]});
Fournissez une phrase MMC obtenue à partir de l'appareil comme données d'entrée et d'extraction :
unparsedMMCLine='$PMMCZ,225444,4917.24,N,00046.34,E,3,DR*7C'; mmcData = pnmea(unparsedMMCLine)mmcData = struct with fields: MessageID: "MMCZ" UTC: '22:54:44' Latitude: 4.9172e+03 Longitude: 46.3400 NavigationSatellites: 3 Status: 0
En savoir plus
Historique des versions
Introduit dans R2020b