L'apprentissage par transfert est une approche de Deep Learning dans laquelle un modèle entraîné pour une tâche est utilisé comme point de départ pour un modèle effectuant une tâche similaire. Il est plus rapide et plus facile de mettre à jour et de réentraîner un réseau avec l'apprentissage par transfert que d'entraîner un réseau en partant de zéro. L'apprentissage par transfert est utilisé pour la classification d'images, la détection d'objets, la reconnaissance vocale ainsi que d'autres applications.
Importance de l'apprentissage par transfert
L'apprentissage par transfert vous permet de tirer parti de l'expertise de la communauté du Deep Learning. Les modèles populaires pré-entraînés offrent une architecture robuste et permettent de ne pas partir de zéro. L'apprentissage par transfert est une technique courante pour l'apprentissage supervisé car :
- Il vous permet d'entraîner des modèles avec moins de données labellisées en réutilisant des modèles populaires déjà entraînés sur des jeux de données volumineux.
- Il permet de réduire le temps d'apprentissage et les ressources informatiques. Avec l'apprentissage par transfert, les pondérations du réseau de neurones ne sont pas apprises en partant de zéro car le modèle pré-entraîné les a déjà définies en se basant sur des apprentissages antérieurs.
- Vous pouvez utiliser des architectures de modèles développées par la communauté de recherche en Deep Learning, notamment des architectures populaires telles que GoogLeNet ou YOLO.

Transférer les connaissances d'un modèle pré-entraîné à un autre modèle, qui peut être entraîné avec moins de données labellisées
Apprentissage à partir de zéro ou apprentissage par transfert ?
Pour créer un modèle de Deep Learning, vous pouvez entraîner un modèle en partant de zéro ou effectuer un apprentissage par transfert avec un modèle pré-entraîné.
Il est plus efficace de développer et d'entraîner un modèle en partant de zéro pour des tâches très spécifiques où des modèles préexistants ne peuvent pas être utilisés. L'inconvénient de cette approche tient au fait qu'elle nécessite généralement une grande quantité de données pour produire des résultats précis. Créer un modèle en partant de zéro fonctionne également bien dans les cas où des réseaux plus petits peuvent atteindre la précision souhaitée. Par exemple, les réseaux de neurones récurrents (RNN) et les réseaux LSTM (Long Short-Term Memory) sont particulièrement efficaces avec les données séquentielles dont la longueur varie, et ils résolvent des problèmes tels que la classification de signaux ou la prédiction de séries temporelles.
L'apprentissage par transfert est utile pour les tâches pour lesquelles il existe différents modèles entraînés. Par exemple, de nombreux réseaux de neurones à convolution (CNN) populaires sont pré-entraînés sur le jeu de données ImageNet, qui contient plus de 14 millions d'images et un millier de classes d'images. Si vous devez classer les images des fleurs de votre jardin (ou toute autre image non incluse dans le jeu de données ImageNet) et que vous disposez d'un nombre limité d'images de fleurs, vous pouvez transférer les couches et leurs pondérations d'un réseau SqueezeNet, remplacer les couches finales et réentraîner votre modèle avec les images dont vous disposez.
Cette approche peut vous aider à obtenir une plus grande précision du modèle en un temps plus court grâce à l'apprentissage par transfert.

Comparaison des performances du réseau (précision) de l'apprentissage à partir de zéro et de l'apprentissage par transfert.
Applications de l'apprentissage par transfert
L'apprentissage par transfert est populaire dans de nombreuses applications de Deep Learning, telles que :

Computer Vision
Les applications de Computer Vision comprennent la reconnaissance d'images, la détection d'objets, la segmentation d'images ainsi que le traitement de nuages de points LiDAR. Consultez l'exemple MATLAB intitulé Classifier les tumeurs dans des images multirésolution bloquées grâce à l'apprentissage par transfert.

Le traitement de la parole et de l'audio
Consultez l'exemple MATLAB intitulé Apprentissage par transfert avec des réseaux audio pré-entraînés dans Deep Network Designer.

Analyse de texte
Consultez l'exemple MATLAB GitHub intitulé Ajustement d'un modèle BERT pour du texte en japonais.
Des modèles pré-entraînés pour l'apprentissage par transfert
Au cœur de l'apprentissage par transfert, on trouve le modèle de Deep Learning pré-entraîné, créé par des chercheurs en Deep Learning, qui a été entraîné en utilisant des milliers ou des millions d'échantillons de points de données.
Il existe de nombreux modèles pré-entraînés, chacun d'entre eux présentant des avantages et des inconvénients qu'il convient de prendre en considération :
- Vitesse de prédiction : à quelle vitesse le modèle peut-il prédire de nouvelles entrées ? Si la vitesse de prédiction peut varier en fonction d'autres facteurs tels que le hardware et la taille des batchs, la vitesse varie également en fonction de l'architecture et de la taille du modèle.
- Taille : quelle est l'empreinte mémoire souhaitée pour votre modèle ? L'importance de la taille de votre modèle variera en fonction de où et comment vous comptez le déployer. Le modèle fonctionnera-t-il sur du hardware embarqué ou sur un PC ? La taille du réseau est importante lors d'un déploiement vers une cible dont les ressources sont limitées.
- Précision : quels sont les performances du modèle avant de procéder à un nouvel entraînement ? Un modèle qui donne de bons résultats pour le jeu de données ImageNet donnera probablement de bons résultats pour de nouvelles tâches similaires. Cependant, un faible taux de précision sur ImageNet ne signifie pas nécessairement que le modèle sera peu performant pour toutes les tâches.

Comparer la taille, la vitesse et la précision des modèles pré-entraînés CNN les plus répandus
Quel est le meilleur modèle pour votre workflow d'apprentissage par transfert ?
Compte tenu du grand nombre de modèles d'apprentissage par transfert disponibles, il est important de garder à l'esprit les compromis à effectuer et les objectifs généraux de votre projet spécifique. Une bonne approche consiste à essayer plusieurs modèles pour trouver celui qui correspond le mieux à votre application.
Des modèles simples pour débuter, tels que GoogLeNet, VGG-16 et VGG-19, vous permettent d'itérer rapidement et d'expérimenter différentes étapes de prétraitement des données, ainsi que différentes options d'apprentissage. Une fois que vous avez identifié les paramètres qui fonctionnent bien, vous pouvez essayer un réseau plus précis pour voir si cela améliore vos résultats.
Des modèles légers et efficaces en termes de calcul, tels que SqueezeNet, MobileNet-v2 ou ShuffleNet, constituent de bonnes options lorsque l'environnement de déploiement limite la taille du modèle.
Comment obtenir des modèles pré-entraînés dans MATLAB ?
Vous pouvez explorer MATLAB® Deep Learning Model Hub pour accéder aux derniers modèles par catégorie et obtenir des conseils pour choisir un modèle. Vous pouvez charger la plupart des modèles avec une seule fonction MATLAB, telle que la fonction darknet19.
Vous pouvez aussi obtenir des réseaux pré-entrainés à partir de plateformes externes. Vous pouvez convertir un modèle de TensorFlow™, PyTorch® ou ONNX™ en un modèle MATLAB en utilisant une fonction d'importation, comme importNetworkFromTensorFlow.

Obtenir des modèles de Deep Learning pré-entraînés directement à partir de MATLAB, ou de plateformes de Deep Learning externes (PyTorch, TensorFlow et ONNX).
Apprentissage par transfert appliqué au design de capteurs virtuels
Découvrez comment Poclain Hydraulics a tiré parti des réseaux pré-entraînés dans MATLAB pour accélérer le design de capteurs virtuels.
« Nous avons identifié deux réseaux de neurones qui étaient déjà implémentés dans MATLAB. Ces réseaux nous ont aidés à intégrer le code pour la prédiction de la température en temps réel, dans notre hardware. »
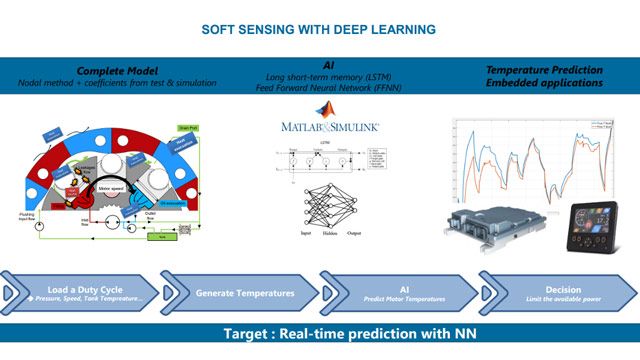
Apprentissage par transfert avec MATLAB
L'utilisation de MATLAB avec Deep Learning Toolbox™ vous permet d'accéder à des centaines de modèles pré-entraînés et d'effectuer un apprentissage par transfert avec des fonctions prédéfinies ou des applications interactives. Pour différentes applications d'apprentissage par transfert, vous pouvez également avoir besoin d'utiliser d'autres toolboxes telles que Computer Vision Toolbox™, Audio Toolbox™, Lidar Toolbox™ ou Text Analytics Toolbox™.
Le workflow d'apprentissage par transfert

Diagramme des étapes du workflow d'apprentissage par transfert.
Bien qu'il existe diverses architectures et applications d'apprentissage par transfert, la plupart de leurs workflows suivent des séries d'étapes communes. L'illustration suivante montre le workflow d'apprentissage par transfert pour la classification d'images. L'apprentissage par transfert est effectué sur un modèle GoogLeNet pré-entraîné, un réseau populaire de 22 couches entraîné à classer 1 000 catégories d'objets.
- Sélectionner un modèle pré-entraîné. Il est préférable de choisir un modèle simple lorsque l'on débute.

Architecture du modèle GoogLeNet, un réseau de 22 couches entraîné à classer 1 000 catégories d'objets.
- Remplacer les dernières couches. Pour réentraîner le réseau à classer un nouveau jeu d'images et de classes, vous remplacez la dernière couche d'apprentissage et la dernière couche de classification du modèle GoogLeNet. La dernière couche entièrement connectée (dernière couche d'apprentissage) est modifiée pour contenir le même nombre de nœuds que le nombre de nouvelles classes. La nouvelle couche de classification produira un résultat basé sur les probabilités calculées par la couche softmax.

Remplacer la dernière couche d'apprentissage et la couche de classification d'un modèle CNN avant de procéder au réapprentissage du modèle
Après avoir modifié les couches, la couche finale entièrement connectée spécifiera le nouveau nombre de classes que le réseau apprendra, et la couche de classification déterminera les sorties à partir des nouvelles catégories de sortie disponibles. Par exemple, GoogLeNet a été entraîné à l'origine sur 1 000 catégories, mais en remplaçant les couches finales, vous pouvez le réentraîner pour qu'il ne classifie que les cinq (ou n'importe quel autre nombre) catégories d'objets qui vous intéressent.
- Geler éventuellement les pondérations. Vous pouvez geler les pondérations des couches précédentes du réseau en mettant les taux d'apprentissage de ces couches à zéro. Pendant l'apprentissage, les paramètres des couches gelées ne sont pas mis à jour, ce qui permet d'accélérer considérablement l'apprentissage du réseau. Si le nouveau jeu de données est petit, le gel des pondérations peut également empêcher le surajustement du réseau au nouveau jeu de données.
- Réentraîner le modèle. Le nouvel apprentissage actualisera le réseau pour qu'il apprenne et identifie les caractéristiques associées aux nouvelles images et aux catégories. Dans la plupart des cas, réentraîner nécessite moins de données que l'apprentissage d'un modèle à partir de zéro.
- Prédire et évaluer la précision du réseau. Une fois le modèle réentraîné, vous pouvez classer de nouvelles images et évaluer la performance du réseau.
Une approche interactive de l'apprentissage par transfert
Avec l'application Deep Network Designer, vous pouvez exécuter de manière interactive l'ensemble du workflow d'apprentissage par transfert, notamment la sélection ou l'importation (depuis MATLAB, TensorFlow ou PyTorch) d'un modèle pré-entraîné, la modification des couches finales et le réapprentissage du réseau avec de nouvelles données, avec peu ou pas de codage.
En savoir plus sur l'apprentissage par transfert
Regardez ces vidéos pour en savoir plus sur l'apprentissage par transfert en ligne de commande ou avec Deep Network Designer.




