La traduction de cette page n'est pas à jour. Cliquez ici pour voir la dernière version en anglais.
Reconnaissance de patterns avec un réseau de neurones peu profond
Outre l’ajustement de fonctions, les réseaux de neurones sont efficaces pour reconnaître des patterns.
Par exemple, supposez que vous vouliez classer une tumeur comme bénigne ou maligne sur la base de l’uniformité de taille des cellules, de l’épaisseur d’agglutination, de la mitose, etc. Vous avez 699 cas avec 9 caractéristiques et la classification correcte comme bénigne ou maligne.
Comme avec l’ajustement de fonctions, il existe deux manières de résoudre ce problème :
Utiliser l’application Neural Net Pattern Recognition, décrite dans Utiliser l’application Neural Net Pattern Recognition pour reconnaître des patterns.
Utiliser les fonctions en ligne de commande, décrites dans Utiliser les fonctions en ligne de commande pour la reconnaissance de patterns.
Il est généralement préférable de commencer avec l’application puis d’utiliser l’application pour générer automatiquement des scripts de lignes de commande. Avant d’utiliser l’une des méthodes, commencez par définir le problème en sélectionnant un jeu de données. Chacune des applications du réseau de neurones a accès à de nombreux jeux de données que vous pouvez utiliser pour vous entraîner avec la toolbox (voir Exemples de jeux de données pour les réseaux de neurones peu profonds). Si vous voulez résoudre un problème spécifique, vous pouvez charger vos propres données dans l’espace de travail. La section suivante décrit le format des données.
Remarque
Utilisez l’application Deep Network Designer pour créer, visualiser et entraîner des réseaux de neurones de Deep Learning de manière interactive. Pour plus d’informations, veuillez consulter Introduction au Deep Network Designer.
Définir un problème
Pour définir un problème de reconnaissance de formes, organisez un ensemble de vecteurs d’entrée (prédicteurs) sous forme de colonnes dans une matrice. Organisez ensuite un autre jeu de vecteurs réponses en indiquant à quelles catégories les observations sont affectées.
Lorsqu’il n’y a que deux classes, chaque réponse comporte deux éléments, 0 et 1, pour indiquer la classe correspondant à l’observation. Vous pouvez par exemple définir un problème de classification en deux classes de la manière suivante :
predictors = [7 10 3 1 6; 5 8 1 1 6; 6 7 1 1 6]; responses = [0 0 1 1 0; 1 1 0 0 1];
Lorsque les prédicteurs doivent être classés en N classes différentes, les réponses comportent N éléments. Pour chaque réponse, un élément est 1 et les autres sont 0. Par exemple, les lignes suivantes montrent comment définir un problème de classification qui reparti les angles d’un cube de 5 par 5 par 5 en trois classes :
L’origine (le premier vecteur d’entrée) dans une classe
L’angle le plus éloigné de l’origine (le dernier vecteur d’entrée) dans une deuxième classe
Tous les autres points dans une troisième classe
predictors = [0 0 0 0 5 5 5 5; 0 0 5 5 0 0 5 5; 0 5 0 5 0 5 0 5]; responses = [1 0 0 0 0 0 0 0; 0 1 1 1 1 1 1 0; 0 0 0 0 0 0 0 1];
La section suivante indique comment entraîner un réseau pour reconnaître des patterns avec l’application Neural Net Pattern Recognition. Cet exemple utilise un jeu de données fourni avec la toolbox.
Utiliser l’application Neural Net Pattern Recognition pour reconnaître des patterns
Cet exemple indique comment entraîner un réseau de neurones peu profond pour classer des patterns (formes) avec l’application Neural Net Pattern Recognition.
Ouvrez l’application Neural Net Pattern Recognition avec nprtool.
nprtool
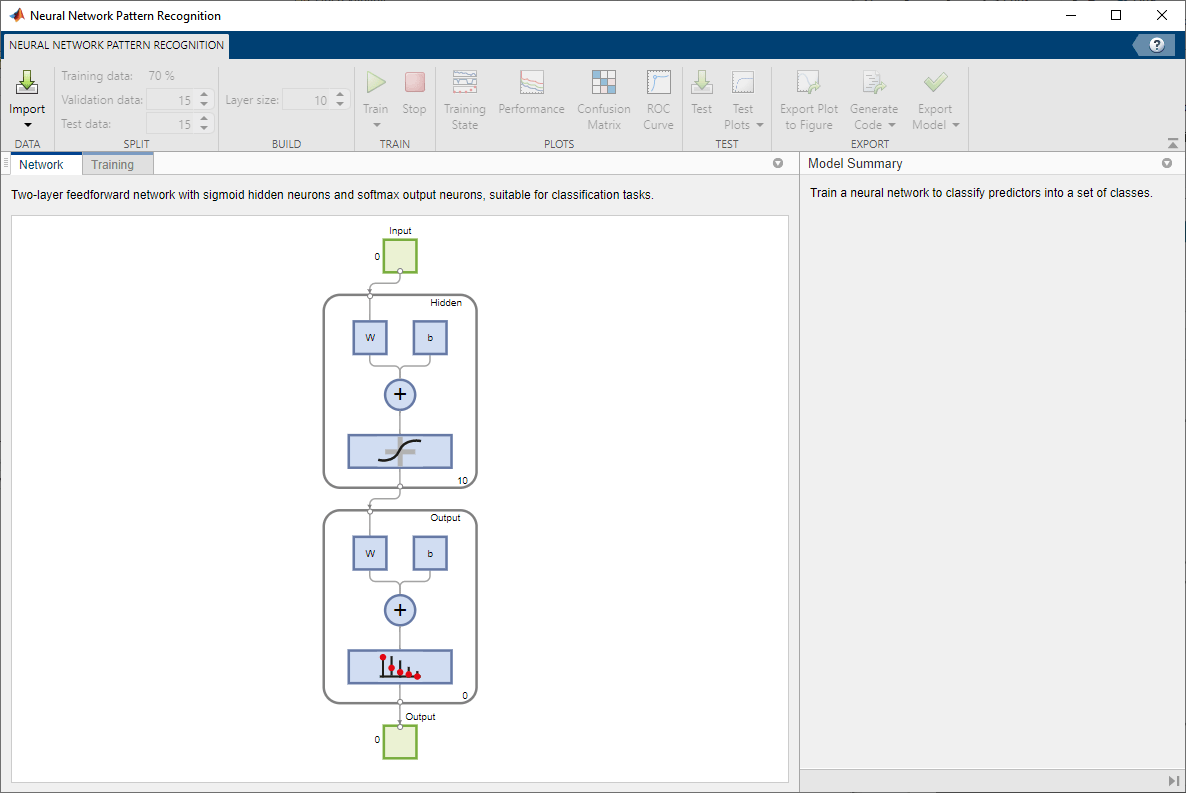
Sélectionner les données
L’application Neural Net Pattern Recognition comporte des exemples de données pour vous aider à commencer à entraîner un réseau de neurones.
Pour importer un exemple de données de classification du verre, sélectionnez Import > Import Glass Data Set. Vous pouvez utiliser ce jeu de données pour entraîner un réseau de neurones afin de classer le verre comme un verre utilisable pour des fenêtres ou non grâce aux propriétés chimiques du verre. Si vous importez vos propres données depuis un fichier ou l’espace de travail, vous devez spécifier les prédicteurs et les réponses et si les observations sont dans des lignes ou dans des colonnes.
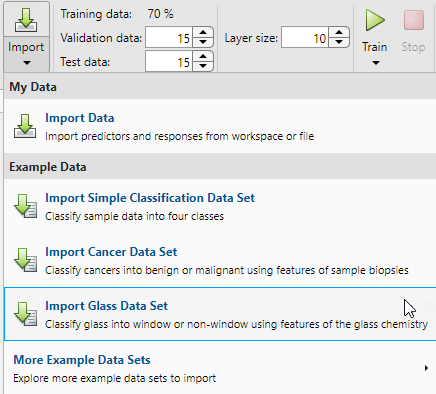
Les informations sur les données importées apparaissent dans le Model Summary. Ce jeu de données contient 214 observations avec 9 caractéristiques chacune. Chaque observation est classée dans l’une des deux classes : window ou non-window.

Répartissez les données entre les jeux d’apprentissage, de validation et de test. Conservez les paramètres par défaut. Les données sont réparties en :
70 % pour l’apprentissage.
15 % pour valider que le réseau généralise et arrêter l’apprentissage avant un surajustement (overfitting).
15 % pour tester la généralisation du réseau de manière indépendante.
Pour plus d’informations sur la division des données, veuillez consulter Divide Data for Optimal Neural Network Training.
Créer un réseau
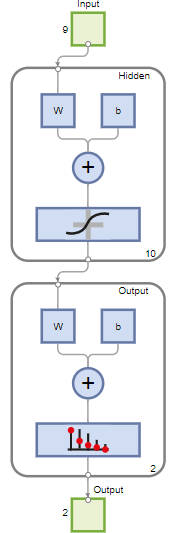
Ce réseau est un réseau feedforward à deux couches, avec une fonction de transfert sigmoïde dans la couche cachée et une fonction de transfert softmax dans la couche de sortie. La taille de la couche cachée correspond au nombre de neurones cachés. La taille de couche par défaut est de 10. Vous pouvez voir l’architecture du réseau dans le volet Network. Le nombre de neurones de sortie est défini à 2, ce qui correspond au nombre de classes spécifié par les données de réponse.
Entraîner le réseau
Pour entraîner le réseau, cliquez sur Train.
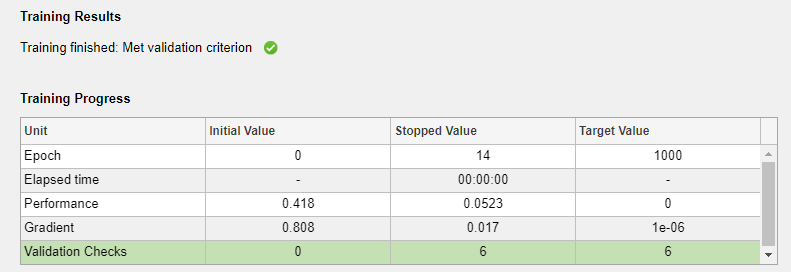
Vous pouvez voir la progression de l'apprentissage dans le volet Training. L'apprentissage se poursuit jusqu’à ce que l'un des critères d’arrêt soit rempli. Dans cet exemple, l’apprentissage continue jusqu’à ce que l’erreur de validation augmente consécutivement sur six itérations (« Critère de validation respecté »).
Analyser les résultats
Le Model Summary contient des informations sur l’algorithme d’apprentissage et sur les résultats de l’apprentissage pour chaque jeu de données.
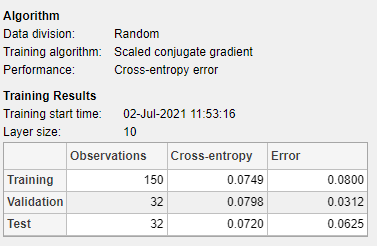
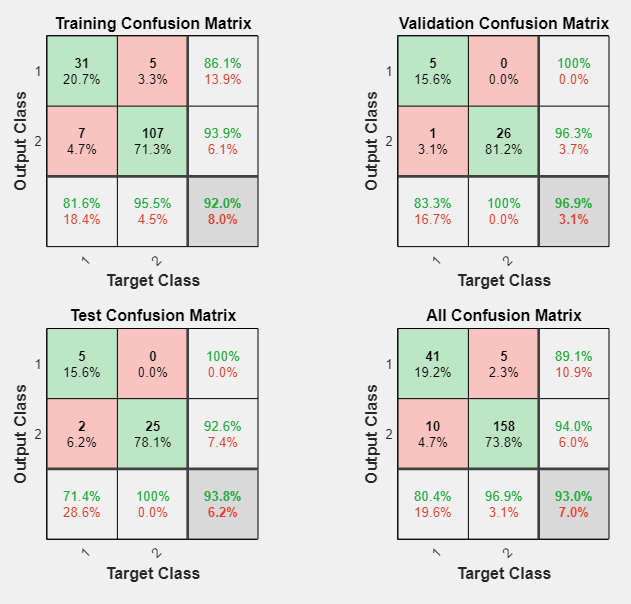
Vous pouvez continuer à analyser les résultats en générant des tracés. Pour tracer les matrices de confusion, dans la section Plots, cliquez sur Confusion Matrix. Les sorties du réseau sont très précises, comme vous pouvez le voir par les nombres élevés de classifications correctes dans les carrés verts (diagonale) et les faibles nombres de classifications incorrectes dans les carrés rouges (hors diagonale).
Regardez la courbe ROC afin d’obtenir une vérification supplémentaire des performances du réseau. Dans la section Plots, cliquez sur ROC Curve.
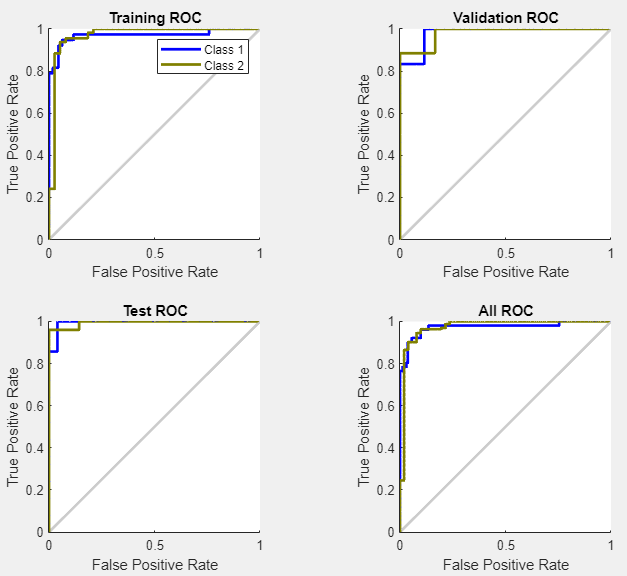
Les lignes colorées sur chaque axe représentent les courbes ROC. La courbe ROC est un tracé du taux de vrais positifs (sensibilité) vs le taux de faux positifs (1 - spécificité) lorsque le seuil varie. Un test parfait présenterait des points dans l’angle supérieur gauche, avec 100 % de sensibilité et 100 % de spécificité. Le réseau est très performant pour ce problème.
Si vous n’êtes pas satisfait des performances du réseau, vous disposez des possibilités suivantes :
Entraîner à nouveau le réseau.
Augmenter le nombre de neurones cachés.
Utiliser un jeu de données d’apprentissage plus grand.
De bonnes performances sur le jeu d’apprentissage associées à de mauvaises performances sur le jeu de test pourraient indiquer un surajustement (overfitting) du modèle. Une réduction du nombre de neurones permet de réduire le surajustement.
Vous pouvez également évaluer les performances du réseau sur un jeu de test supplémentaire. Pour charger des données de test supplémentaires pour l'évaluation du réseau, dans la section Test, cliquez sur Test. Le Model Summary affiche les résultats des tests supplémentaires. Vous pouvez également générer des tracés afin d’analyser les résultats de tests supplémentaires.
Générer du code
Sélectionnez Generate Code > Generate Simple Training Script afin de créer du code MATLAB pour reproduire les étapes précédentes en ligne de commande. Il peut être utile de créer du code MATLAB si vous voulez apprendre comment utiliser la fonctionnalité de ligne de commande de la toolbox pour personnaliser le processus d’apprentissage. Dans Utiliser les fonctions en ligne de commande pour la reconnaissance de patterns, vous étudierez les scripts générés de manière plus détaillée.
Exporter un réseau
Vous pouvez exporter votre réseau entraîné vers l’espace de travail ou Simulink®. Vous pouvez également déployer le réseau avec MATLAB Compiler™ et d’autres outils de génération de code MATLAB. Pour exporter votre réseau entraîné et vos résultats, sélectionnez Export Model > Export to Workspace.
Utiliser les fonctions en ligne de commande pour la reconnaissance de patterns
La manière la plus facile d’apprendre à utiliser la fonctionnalité en ligne de commande de la toolbox consiste à générer des scripts à partir des applications, puis à les modifier afin de personnaliser l’apprentissage du réseau. À titre d’exemple, regardez le script simple qui a été créé dans la section précédente à l’aide de l'application Neural Net Pattern Recognition.
% Solve a Pattern Recognition Problem with a Neural Network % Script generated by Neural Pattern Recognition app % Created 22-Mar-2021 16:50:20 % % This script assumes these variables are defined: % % glassInputs - input data. % glassTargets - target data. x = glassInputs; t = glassTargets; % Choose a Training Function % For a list of all training functions type: help nntrain % 'trainlm' is usually fastest. % 'trainbr' takes longer but may be better for challenging problems. % 'trainscg' uses less memory. Suitable in low memory situations. trainFcn = 'trainscg'; % Scaled conjugate gradient backpropagation. % Create a Pattern Recognition Network hiddenLayerSize = 10; net = patternnet(hiddenLayerSize, trainFcn); % Setup Division of Data for Training, Validation, Testing net.divideParam.trainRatio = 70/100; net.divideParam.valRatio = 15/100; net.divideParam.testRatio = 15/100; % Train the Network [net,tr] = train(net,x,t); % Test the Network y = net(x); e = gsubtract(t,y); performance = perform(net,t,y) tind = vec2ind(t); yind = vec2ind(y); percentErrors = sum(tind ~= yind)/numel(tind); % View the Network view(net) % Plots % Uncomment these lines to enable various plots. %figure, plotperform(tr) %figure, plottrainstate(tr) %figure, ploterrhist(e) %figure, plotconfusion(t,y) %figure, plotroc(t,y)
Vous pouvez enregistrer le script puis l’exécuter en ligne de commande afin de reproduire les résultats de la session d’apprentissage précédente. Vous pouvez également éditer le script pour personnaliser le processus d’apprentissage. Dans ce cas, suivez chaque étape du script.
Sélectionner les données
Ce script suppose que les vecteurs prédicteurs et réponses soient déjà chargés dans l’espace de travail. Si les données ne sont pas chargées, vous pouvez les charger de la manière suivante :
load glass_datasetglassInputs et les réponses glassTargets dans l’espace de travail.Ce jeu de données est l’un des exemples de jeux de données de la toolbox. Pour des informations sur les jeux de données disponibles, veuillez consulter Exemples de jeux de données pour les réseaux de neurones peu profonds. Vous pouvez également voir une liste de tous les jeux de données disponibles en saisissant la commande help nndatasets. Vous pouvez charger les variables depuis n’importe lequel de ces jeux de données avec vos propres noms de variables. Par exemple, la commande
[x,t] = glass_dataset;
x et les réponses dans le tableau t.Choisir un algorithme d’apprentissage
Définissez l’algorithme d’apprentissage.
trainFcn = 'trainscg'; % Scaled conjugate gradient backpropagation.
Créer un réseau
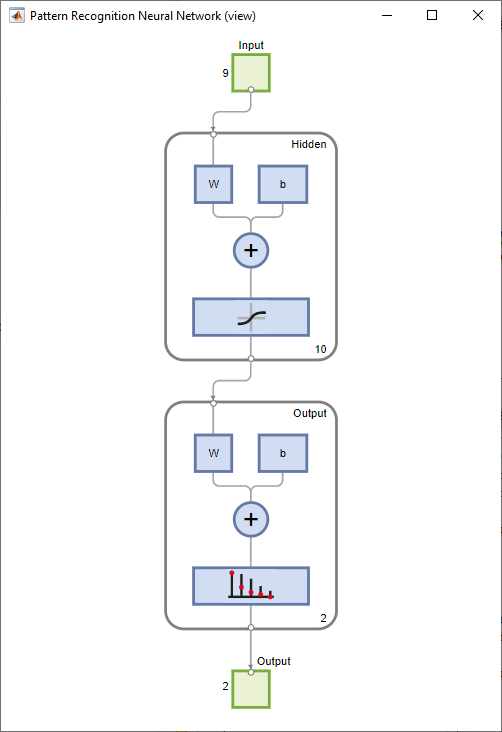
Créez le réseau. Le réseau par défaut pour les problèmes de reconnaissance de formes (classification), patternnet, est un réseau feedforward avec une fonction de transfert sigmoïde par défaut dans la couche cachée, et une fonction de transfert softmax dans la couche de sortie. Le réseau a une couche cachée unique avec dix neurones (par défaut).
Le réseau présente deux neurones de sortie car deux valeurs de réponses (classes) sont associées à chaque vecteur d’entrée. Chaque neurone de sortie représente une classe. Lorsqu’un vecteur d’entrée de la classe appropriée est appliqué au réseau, le neurone correspondant devrait produire un 1 et les autres neurones un 0.
hiddenLayerSize = 10; net = patternnet(hiddenLayerSize, trainFcn);
Remarque
L’augmentation du nombre de neurones nécessite plus de calcul, ce qui a tendance à provoquer un surajustement (overfitting) des données lorsque le nombre est trop élevé, mais cela permet au réseau de résoudre des problèmes plus compliqués. Un plus grand nombre de couches nécessite plus de calcul, mais cela peut permettre au réseau de résoudre des problèmes complexes plus efficacement. Pour utiliser plusieurs couches cachées, entrez les tailles des couches cachées comme éléments d’un tableau dans la commande patternnet.
Diviser les données
Définissez la division des données.
net.divideParam.trainRatio = 70/100; net.divideParam.valRatio = 15/100; net.divideParam.testRatio = 15/100;
Avec ces paramètres, les vecteurs prédicteurs et les vecteurs réponses seront divisés de manière aléatoire, 70 % des données étant utilisées pour l’apprentissage, 15 % pour la validation et 15 % pour les tests. Pour plus d’informations sur le processus de division des données, veuillez consulter Divide Data for Optimal Neural Network Training.
Entraîner le réseau
Entraînez le réseau.
[net,tr] = train(net,x,t);
Pendant l’apprentissage, la fenêtre de progression de l’apprentissage apparaît. Vous pouvez interrompre l’apprentissage n'importe quand en cliquant sur le bouton d’arrêt  .
.

L’apprentissage s’arrête lorsque l’erreur de validation augmente consécutivement sur six itérations, ce qui s’est produit à l’itération 14.
Si vous cliquez sur Performance dans la fenêtre d’apprentissage, un tracé des erreurs d’apprentissage, de validation et de test apparaît, comme illustré sur la figure suivante.
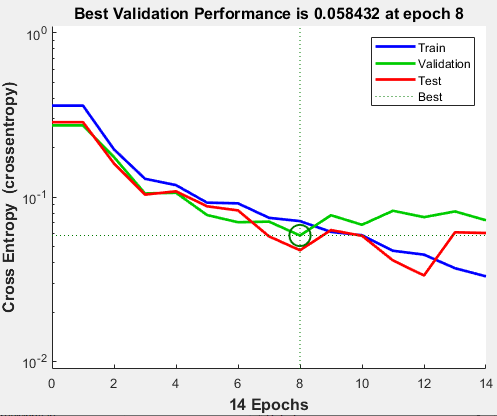
Dans cet exemple, le résultat est raisonnable car l’erreur d’entropie croisée finale est faible.
Tester le réseau
Testez le réseau. Une fois que le réseau a été entraîné, vous pouvez l’utiliser pour calculer les sorties du réseau. Le code suivant calcule les sorties, les erreurs et la performance globale du réseau.
y = net(x); e = gsubtract(t,y); performance = perform(net,t,y)
performance =
0.0659Vous pouvez également calculer la fraction des observations mal classées. Dans cet exemple, le taux d’erreurs de classification du modèle est très faible.
tind = vec2ind(t); yind = vec2ind(y); percentErrors = sum(tind ~= yind)/numel(tind)
percentErrors =
0.0514Il est également possible de calculer les performances du réseau uniquement sur le jeu de test en utilisant les indices de test, qui sont situés dans l’enregistrement d’apprentissage.
tInd = tr.testInd; tstOutputs = net(x(:,tInd)); tstPerform = perform(net,t(tInd),tstOutputs)
tstPerform =
2.0163
Afficher le réseau
Affichez le schéma du réseau.
view(net)
Analyser les résultats
Pour obtenir la matrice de confusion, utilisez la fonction plotconfusion. Vous pouvez également obtenir la matrice de confusion de chaque jeu de données en cliquant sur Confusion dans la fenêtre d’apprentissage.
figure, plotconfusion(t,y)
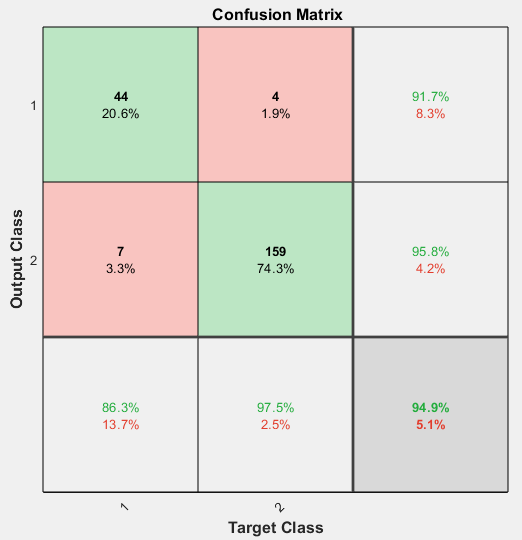
Les cellules vertes sur la diagonale indiquent le nombre de cas bien classés et les cellules rouges en dehors de la diagonale indiquent les cas mal classés. Les résultats indiquent une très bonne reconnaissance. Si vous aviez besoin de résultats encore plus précis, vous pourriez essayer l’une des approches suivantes :
Remplacer les valeurs de poids et de biais initiaux du réseau par de nouvelles valeurs avec
initet réessayer.Augmenter le nombre de neurones cachés.
Utiliser un jeu de données d’apprentissage plus grand.
Augmenter le nombre de valeurs d’entrée si des informations plus utiles sont disponibles.
Essayer un autre algorithme d’apprentissage (voir Training Algorithms).
Dans ce cas, les résultats du réseau sont satisfaisants et vous pouvez maintenant utiliser le réseau avec de nouvelles données d’entrée.
Étapes suivantes
Pour gagner de l’expérience dans les opérations en ligne de commande, vous pouvez essayer ces tâches :
Pendant l’apprentissage, ouvrez une fenêtre de tracé (telle que la matrice de confusion) et regardez-la s’animer.
Tracez en ligne de commande avec des fonctions telles que
plotroc, etplottrainstate.
A chaque fois qu'un réseau de neurones est entraîné, il peut produire une solution différente en raison des valeurs initiales aléatoires de poids et de biais, et des différences de partition des données en jeux de données d’apprentissage, de validation et de test. Par conséquent, différents réseaux de neurones entraînés sur le même problème peuvent produire différentes sorties pour la même entrée. Pour s'assurer qu'un réseau de neurones est suffisamment précis, réalisez plusieurs apprentissages.
Il existe plusieurs autres techniques pour améliorer les résultats si vous voulez plus de précision. Pour plus d’informations, veuillez consulter Improve Shallow Neural Network Generalization and Avoid Overfitting.
Voir aussi
Neural Net Fitting | Neural Net Time Series | Neural Net Pattern Recognition | Neural Net Clustering | Deep Network Designer | trainscg
Sujets associés
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)